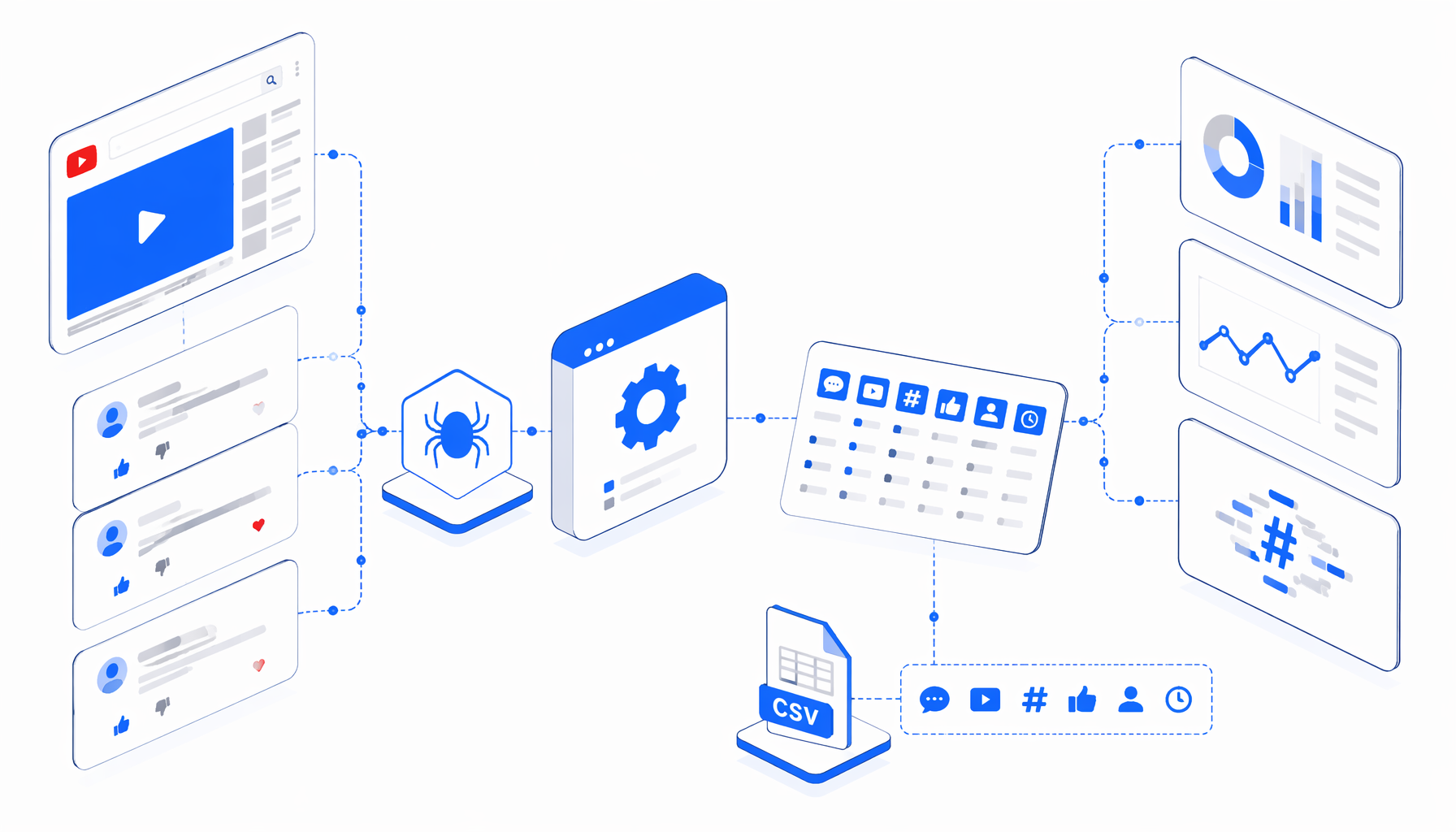
A YouTube comments scraper is useful when the real job is not watching videos. The job is turning a defined set of YouTube URLs into a reviewable CSV export for research, newsroom checks, SEO analysis, creator reporting, or monitoring. The YouTube Comments Scraper with Video Details template gives each loaded comment row its source video context, so analysts can work from one file instead of joining metadata later.
Use-case fit
When YouTube comment analysis needs structure
YouTube comments are useful because they are close to the audience. They are also hard to analyze in the browser. Threads load dynamically, creators can disable comments, replies may be hidden behind expansion controls, and the useful context is scattered across the watch page: title, channel, publish date, views, description, and comment count.
That is the pain behind searches like how to scrape YouTube comments, YouTube comment search, scrape YouTube video metadata, and YouTube data API vs scraper. The question is usually practical: "How do we collect a defensible sample from known videos and make it usable in a spreadsheet?"
A comment without the source video, channel, date, URL, and collection notes is not analysis-ready. It is a loose quote.
The UScraper workflow fits narrow, supervised exports. It is not a promise of every historical comment, every reply, or a permanent YouTube archive. It helps teams convert the visible state of selected video pages into rows that can be filtered, coded, tagged, and audited.
Personas
Who uses a YouTube comments scraper?
| Persona | Pain | Useful CSV outcome |
|---|---|---|
| Public-interest researchers | Manual copying makes qualitative coding inconsistent across a video sample. | Export comment text with video ID, title, channel, date, and URL for coding and anonymization workflows. |
| Newsrooms | Public reaction changes quickly after a story, launch, hearing, or crisis. | Keep a dated CSV sample that editors can spot-check against the source videos before quoting or summarizing. |
| SEO teams | Viewer questions and objections are buried below tutorials, comparisons, and product videos. | Mine repeated language, questions, objections, and topic gaps for content briefs. |
| Creator teams | Audience requests are spread across uploads and hard to prioritize in the YouTube interface. | Group repeated questions by video, channel context, comment likes, and publish label. |
| Brand monitors | Launch and competitor videos need review, but screenshots do not scale. | Turn selected watch URLs into a local queue for sentiment tagging, escalation, and reporting. |
The common thread is a defined source list. For broad discovery, use a separate YouTube search, channel, or video-list workflow first. For analysis, this template is strongest when the video URLs are already chosen and the output needs to be a local CSV.
Workflow
How the template turns video pages into rows
The workflow uses a visible browser run rather than an API key. It sets a large browser window, navigates through multiple video URLs, waits for the watch page, caches video metadata, pauses playback, handles common consent prompts, scrolls to load comments, expands readable text where possible, checks for comment thread elements, then exports rows.
Set Window Size -> Navigate -> Wait for Page Load -> Wait for watch page
-> cache video metadata -> sleep and scroll sequence -> expand comments
-> Element Exists -> Structured Export -> Loop Continue
If ytd-comment-thread-renderer exists, the template exports one row per loaded top-level comment. If comments are disabled, blocked, require sign-in, trigger verification, or fail to load, the fallback branch still writes a video-level row with blank comment fields. That fallback matters because a missing comment section becomes visible in the dataset instead of disappearing from the run.
Export
Export shape summary for comment analysis
The bundle has no separate CSV sample. The JSON workflow definition is the authoritative export sample, and its Structured Export blocks define the columns below.
| Export group | Columns | Why it matters |
|---|---|---|
| Video identity | title, video_url, video_id | Keeps every comment tied to the source watch page. |
| Video metadata | view, date, thumbs_up, comment_count | Adds lightweight YouTube stats for screening and comparison. |
| Channel context | youtuber, subscribers, description | Helps interpret the audience and content angle behind the comments. |
| Comment detail | author, comment_date, comment, comment_likes | Provides the text and visible engagement signals used for tagging or coding. |
| Fallback state | Blank comment fields with populated video fields | Records attempted videos where comments did not load or were unavailable. |
{
"project": {
"name": "YouTube Details Comments Scraper",
"description": "Scrapes YouTube video details and comments from multiple YouTube video URLs."
},
"workflow": {
"navigate": "multiple YouTube video URLs",
"waitFor": "ytd-watch-flexy",
"commentRows": "ytd-comment-thread-renderer",
"exportFile": "youtube-details-comments-scraper.csv",
"fallback": "export video-level fields with blank comment fields"
}
}
youtube-details-comments-scraper.csvColumn
title
Video title from YouTube metadata or the visible watch-page heading.
Column
view
Visible or metadata-backed view count text.
Column
date
Publish date from metadata, scripts, or visible watch-page text.
Column
thumbs_up
Visible like label for the video when exposed.
Column
youtuber
Creator or channel name.
Column
subscribers
Visible subscriber count text when rendered.
Column
description
Video description or short description text.
Column
comment_count
Visible comment count parsed from the comments header.
Column
author
Comment author display name.
Column
comment_date
Visible comment publish label.
Column
comment
Loaded top-level comment text.
Column
comment_likes
Visible like count for the comment.
Column
video_url
Current YouTube video URL.
Column
video_id
Video ID parsed from the URL.
Scenarios
Concrete YouTube comment analysis workflows
Research codebook preparation
Export comments from a defined sample of public videos, then create labels for topics, sentiment, stance, spam, creator replies, or misinformation review. Keep the source URL and video ID beside every row.
Newsroom reaction checks
Collect comments from videos tied to a public event and preserve a dated evidence index. Editors can filter by video, spot-check the source page, and decide which comments require manual verification.
SEO question mining
Run tutorial, comparison, and competitor videos through the template, then group repeated viewer questions. Use the output to plan FAQs, product pages, and blog posts that answer real audience language.
Creator feedback triage
Export comments from recent uploads, sort by comment likes, and tag repeated support questions, feature requests, complaints, praise, and follow-up video ideas.
Brand and competitor monitoring
Review launch videos, sponsored videos, and comparison content with a stable URL list. Compare runs by video ID and collection date rather than relying on screenshots.
For setup steps, use the companion YouTube comments scraper tutorial. If you are still choosing tooling, compare YouTube comments scraper alternatives or browse the full UScraper template library.
API decision
YouTube Data API vs scraper for comments and metadata
The official YouTube Data API is the first route to evaluate for applications. The commentThreads.list method returns comment threads that match request parameters, comments.list covers comment resources such as replies, and videos.list returns video resources for metadata and statistics. Google's quota cost reference is important because paginated API work needs quota planning.
| Route | Best fit | Trade-off |
|---|---|---|
| YouTube Data API | Approved software integrations, pagination, reply workflows, repeatable developer access, and quota-managed pipelines | Requires API setup, keys or OAuth depending on the action, schema work, and quota planning. |
| UScraper template | Local CSV exports from known video URLs, visible page QA, research batches, and analyst-led review | Depends on rendered page state, bounded scrolling, selector stability, and manual handling of access prompts. |
| Hosted scraper platform | Scheduled cloud jobs, datasets, API delivery, and higher-throughput operations | Adds vendor custody, usage pricing, run logs, and platform-specific extraction behavior. |
| Custom script | Engineering-owned queues, storage, tests, retries, and parser control | Highest control, but also highest maintenance and compliance burden. |
Use the API when the project is a product integration. Use a supervised scraper when the deliverable is a spreadsheet for a bounded research or monitoring task. In either case, review the current YouTube Terms of Service, robots.txt, and, for formal research, the YouTube Researcher Program terms.
QA
Validation checklist before analysis
- Save the source video URL list and the reason each video was included.
- Run one public video first and compare the CSV against the visible watch page.
- Record the run date, region, browser state, template version, and any selector edits.
- Treat blank comment fields as QA signals, not as zeros.
- Preserve fallback rows so failed or unavailable comment sections are auditable.
- Dedupe repeated test runs before coding, sentiment analysis, or AI enrichment.
- Stop on sign-in, age gate, CAPTCHA, verification, private content, or unusual traffic screens.
This is the difference between a quick scrape and a comment analysis workflow. The template produces rows; the runbook makes those rows defensible.
FAQ
YouTube comments scraper workflow FAQ
Use it when researchers, newsroom teams, SEO analysts, creator teams, or monitoring teams have a controlled list of public YouTube video URLs and need a structured CSV with comment text plus source video metadata.
Next step
Download the YouTube comments scraper template
Use the YouTube Comments Scraper with Video Details when your team has a defined video list, a clear comment analysis question, and a need for local CSV output. Run one video first, verify the rows, then expand the batch only after the export matches what you see in the browser. For broader options, browse the UScraper blog and template library.