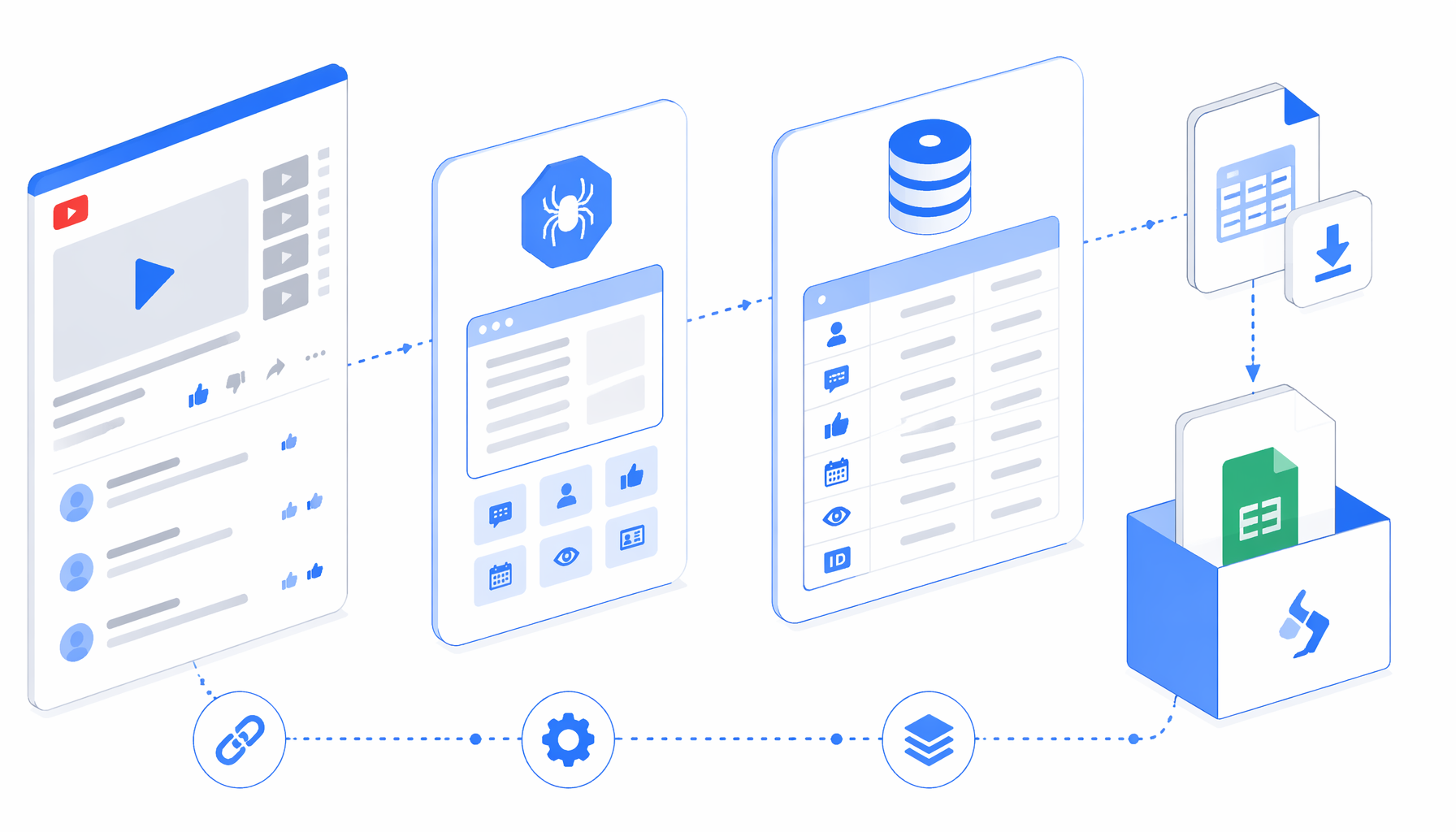
This YouTube comment scraper tutorial shows how to collect visible comments and video metadata into CSV with the YouTube Details Comments Scraper template for UScraper. You will import the workflow, replace the sample video URLs, choose an export folder, run a small validation batch, and understand when the official YouTube Data API is the better route.
Before you start
Prerequisites and policy checks
You need UScraper installed as a local desktop app, a short list of YouTube video URLs, and a folder where CSV exports can be saved. Start with two or three videos because comment availability varies by region, age restriction, sign-in state, creator settings, and YouTube's current page layout.
Review the current YouTube Terms of Service, YouTube robots.txt, and the YouTube Data API getting started guide before collecting data. This article is for visible, browser-accessible research workflows. It is not a guide to bypass login walls, consent screens, bot checks, paid content, or private account areas.
Treat the browser as the source of truth. If the page shows a verification prompt, comments are turned off, or a video requires sign-in, pause the run and handle the access question before trusting the CSV.
Workflow anatomy
What the YouTube details comments scraper does
The workflow definition is intentionally simple: set a large browser window, open each URL from navigate.urls, wait for ytd-watch-flexy, cache video metadata, scroll down several times, expand long comments where possible, check whether ytd-comment-thread-renderer exists, and export either comment rows or a fallback video-only row.
The bundled JSON is the authoritative workflow sample. It exports video metadata repeatedly beside each comment so the CSV can be filtered without joining separate files. When the comments section is blocked, unavailable, or not loaded, the fallback branch still records the video-level fields and leaves comment fields blank.
| Export group | Columns | Why it matters |
|---|---|---|
| Video identity | title, video_url, video_id | Keeps every comment tied to its source video. |
| Video metrics | view, date, thumbs_up, comment_count | Supports quick screening and trend analysis. |
| Channel context | youtuber, subscribers, description | Adds creator and content context to the comment rows. |
| Comment detail | author, comment_date, comment, comment_likes | Captures the visible discussion text and lightweight engagement signal. |
| Fallback behavior | Blank comment fields with populated video fields | Makes failed or unavailable comment sections auditable instead of silent. |
Runbook
How to scrape YouTube comments to CSV
Import the template
Open YouTube Details Comments Scraper, download the JSON template, and import it into UScraper.
Replace the sample video URLs
In Navigate, replace the sample youtu.be links with the YouTube video URLs you are allowed to process. Keep one URL per input entry.
Choose the CSV export path
Open Structured Export, keep youtube-details-comments-scraper.csv, and point the save location to a project folder you can audit later.
Run one video and inspect the page
Let the browser load, scroll, and expand visible comments. If consent, sign-in, disabled comments, or verification appears, resolve that state before scaling.
Run the URL list
After the first CSV looks correct, run the remaining URLs. Loop Continue advances the multi-URL list and Structured Export appends rows.
After the first run, sort the CSV by video_id and scan the comment column. A video with loaded comments should create multiple rows. A video with disabled or blocked comments should create a video-level fallback row, which is useful because you can see which URLs were attempted.
API comparison
YouTube comments API vs scraper
The official API is often the first option to evaluate. For comment collection, commentThreads.list lists top-level comment threads for a video, comments.list can retrieve replies and comment details, and videos.list returns video metadata and statistics. The tradeoff is setup and quota management: you need a Google Cloud project, an API key or OAuth depending on the action, and pagination for larger comment sets.
| Route | Best for | Watch out for |
|---|---|---|
| YouTube Data API | Product integrations, repeatable pipelines, documented fields, compliance review | API setup, quota limits, pagination, fields that differ from the rendered page |
| UScraper template | Local CSV research, visible page QA, no-code extraction, quick competitor or audience analysis | Layout changes, lazy-loaded comments, prompts, and browser state |
| Hosted scraper platforms | Scheduled cloud jobs, managed infrastructure, higher throughput | Usage-based pricing, external data handling, and vendor-specific limits |
For many analysts, the practical split is simple: use the API for approved software integration, and use a supervised scraper when the job is a small local export that must match what a human can inspect on the watch page.
Validation
Validate video details and comments before analysis
Do not send the CSV straight into a report. YouTube pages can change, and comments are loaded progressively. Keep the browser open beside the CSV and validate at least three records: one from the first video, one from the middle of the run, and one from the end.
| Symptom | Likely cause | Fix |
|---|---|---|
Blank comment cells for every row | Comments are disabled, hidden, blocked, or not loaded | Check the page state and rerun one URL with more scroll time. |
| Only a few comments exported | The scroll sequence stopped before more threads loaded | Add another scroll and sleep pair, then rerun a single video. |
Missing date or view | YouTube changed visible metadata or regional text | Compare against the browser and refresh the JavaScript selector if needed. |
| Duplicate rows | The CSV was appended from multiple test runs | Clear the file or write to a fresh folder before the final batch. |
| Fallback row appears | ytd-comment-thread-renderer was not found | Treat it as an attempted URL, not as a successful comment scrape. |
FAQ
YouTube comment scraper FAQ
YouTube comments may be public, but automated collection is still governed by YouTube terms, robots rules, API policies, copyright, privacy law, and local regulations. Review the current policies, avoid bypassing access controls, do not collect private account data, and use the official API when you need an approved integration path.
Next step
Download the YouTube details comments scraper template
When you are ready to run the tutorial, download the workflow from YouTube Details Comments Scraper and keep this article open for validation. For related no-code exports, browse the UScraper template library or read more tutorials in the UScraper blog.