The practical reason to scrape Tabelog restaurant data is not to make a bigger spreadsheet. It is to turn scattered restaurant pages into a reviewable dataset for research, newsroom checks, local SEO, competitor monitoring, and hospitality planning. This use-case guide shows where the Tabelog Details Scraper template fits, what it exports, and how teams turn the CSV into decisions.
Problem
Why Tabelog restaurant data gets messy
Tabelog pages and restaurant homepages can hold the details researchers want: store name, address, access notes, operating hours, holidays, budget, payment, seats, smoking policy, parking, telephone, homepage, remarks, courses, drinks, and dishes. The trouble is that those details are meant for human browsing, not clean analysis.
A market researcher may need to compare 80 izakaya near a station. A newsroom may need to confirm whether restaurants in a story still publish the same hours or phone numbers. A local SEO team may want to audit address consistency across Tabelog, Google Maps, and restaurant sites. A monitoring analyst may need a weekly list of changing budgets, menus, or closure notes.
Manual copying works for five pages. It breaks when the work needs source URLs, repeatable columns, deduplication, QA, and a clean handoff to Excel, Sheets, Airtable, or BI tools.
The useful dataset is not "everything on Tabelog." It is the smallest allowed set of fields that answers a specific restaurant research question.
Personas
Who uses a Tabelog details scraper?
Restaurant researchers
Build a comparable table of names, address, transportation, hours, budget, phone, and amenities for a defined city, station area, cuisine, or price segment.
Newsrooms and analysts
Collect a dated snapshot for fact checks, local business reporting, tourism coverage, or market explainers where every row needs a source URL.
Local SEO teams
Compare restaurant identity, address, phone, homepage, and remarks against other directory profiles before fixing inconsistent listings.
Monitoring teams
Repeat a small approved URL list over time to detect changed hours, menu copy, contact details, or closed-location signals.
The common pattern is controlled scope: a narrow question, a known input list, and a CSV that can be audited later.
| Team | Pain before scraping | Outcome after export |
|---|---|---|
| Research | Restaurant details copied into inconsistent notes | One CSV with stable headers and source URLs |
| Newsroom | Reporters re-check the same pages by hand | Dated evidence table for editorial verification |
| SEO | Directory fields compared manually | Address, phone, homepage, and remarks ready for matching |
| Monitoring | Changes missed between manual checks | Repeatable snapshots for diffing and review |
Workflow
How the template turns pages into structured export
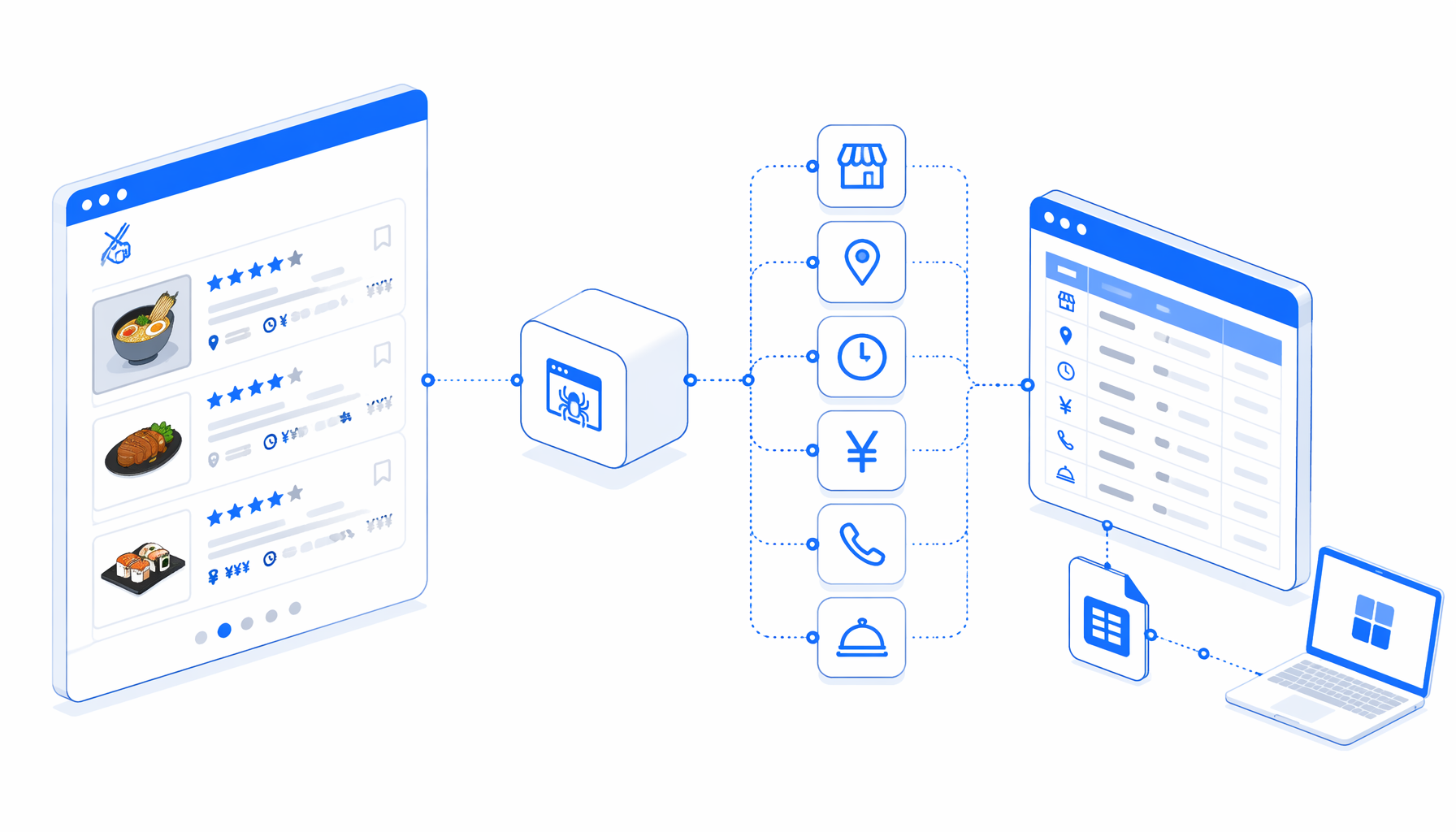
The Tabelog Details Scraper is built around a simple visible loop:
Navigate -> Wait for Page Load -> Wait for Element
-> Sleep -> Structured Export -> Loop Continue
Navigate holds the URL list. The wait blocks reduce empty rows by letting page content settle. Structured Export reads the rendered page and appends fields into tabelog-details-scraper.csv. Loop Continue moves to the next URL.
From research question to CSV
- 1
Define the question
Pick a scope such as "tonkatsu restaurants near Ginza" or "venues mentioned in this article."
- 2
Prepare URLs
Collect only the restaurant detail pages your team is allowed to process.
- 3
Run a small batch
Start with three to five URLs and watch the browser flow before expanding.
- 4
Audit the CSV
Compare names, address, hours, budget, phone, and menu fields against the source pages.
The template JSON is the authoritative workflow definition. It uses a multi-URL input list and a Structured Export block with fileMode=append, so each loaded restaurant URL becomes one row. The bundle does not include a CSV sample; treat the first run as the schema check.
Output
What the Tabelog CSV gives each workflow
tabelog-details-scraper.csvColumn
source_url
Trace every row back to the loaded restaurant page.
Column
store_name
Restaurant name or a page metadata fallback.
Column
address
Location text for area research and deduplication.
Column
operating_hours
Published hours when available on the page.
Column
budget
Price guidance or average budget text.
Column
tel
Telephone link or phone-like text.
Column
dishes
Menu items, courses, drinks, or dish summaries.
Column
remarks
Page summary or description text for analyst notes.
| Use case | Most useful columns | How the CSV is used |
|---|---|---|
| Market map | store_name, address, transportation, budget, number_of_seats | Segment restaurants by area, access, price, and capacity. |
| Newsroom check | source_url, store_name, tel, operating_hours, remarks | Preserve a dated trail for fact-checking and follow-up calls. |
| Local SEO audit | store_name, address, tel, the_homepage, remarks | Match identity fields against other directory profiles. |
| Menu monitoring | course, drink, dishes, budget, shop_holidays | Spot menu, price, or availability changes across repeat runs. |
| Hospitality benchmark | private_dining_room, private_use, parking_lot, with_children | Compare amenities across competitors in a defined area. |
Tabelog rating can be useful context, but it should not be the only signal in a research table. Tabelog publishes its own explanation of score, ranking, and rating behavior, so keep the rating beside source URL, scrape date, and the fields that explain why a restaurant matters for the project.
Examples
Concrete problem-solution examples
Station-area competitor scan
A hospitality team has 40 known restaurant pages around Shibuya Station. They export budget, hours, private room, smoking, parking, children policy, and dishes, then filter the CSV for venues competing with a new dinner concept.
Newsroom source table
A reporter covering local closures collects the restaurant pages cited by interviewees. The CSV gives source URLs, phone numbers, hours, remarks, and homepage links that can be checked before publication.
SEO listing cleanup
An agency compares the exported restaurant name, address, phone, homepage, and remarks against client-owned listings. Differences become review tasks, not copy-paste guesses.
Menu and budget watchlist
An analyst runs the same approved URL list monthly, saves dated CSV files, and compares budget, course, drink, and dishes for visible changes.
For a step-by-step setup guide, use the Tabelog scraper tutorial. If you are comparing hosted tools, APIs, and scripts first, read the Tabelog scraper alternatives guide.
Fit
When UScraper is the right fit
Use UScraper when the operator needs a local desktop workflow, visible browser behavior, editable blocks, and CSV output from a curated URL list.
Use a hosted actor, API provider, or Python scraper when the job needs scheduling, queues, webhooks, proxy strategy, database writes, tests, or engineer-owned infrastructure. A local template is stronger when the deliverable is a traceable spreadsheet and the team wants to see the run.
FAQ
Tabelog details scraper use-case FAQ
A Tabelog details scraper is useful for restaurant researchers, local SEO teams, newsrooms, hospitality operators, and monitoring teams that already have an approved list of restaurant URLs and need a structured CSV for review.
Next step
Start from the template
If your project starts with a curated restaurant URL list, download Tabelog Details Scraper, run a three-page validation batch, and inspect the CSV before widening the scope. For adjacent workflows, browse the UScraper template library or return to the UScraper blog.