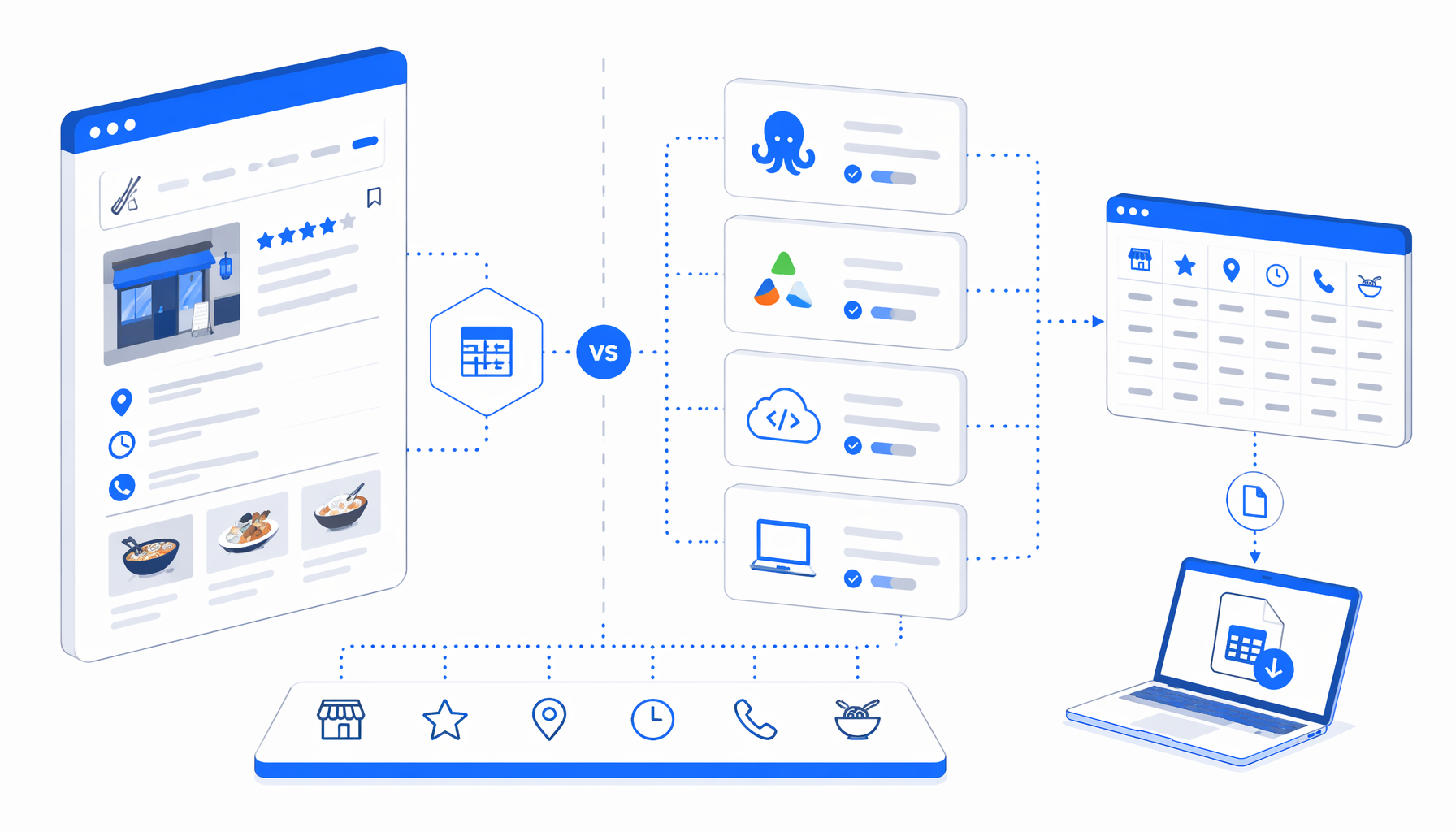
The best Tabelog scraper depends on where the workflow runs, whether it needs code, what the export looks like, and how painful it is to maintain. This comparison covers Octoparse templates, Apify actors, APIs, managed scrapers, Python scripts, and UScraper's Tabelog Details Scraper for local CSV exports.
Comparison frame
What a Tabelog scraper has to solve
Tabelog restaurant pages can include names, ratings, addresses, access notes, hours, holidays, budgets, payment details, seats, smoking policy, parking, telephone numbers, remarks, courses, drinks, and dishes. A useful Tabelog data extraction tool has to handle optional fields, regional layouts, redirects, and pages where some detail blocks do not exist.
The right comparison is not "Which vendor says Tabelog on the landing page?" The better question is:
Which workflow gives us the right permission model, hosting model, output format, and maintenance path for the restaurant data we are allowed to collect?
Before running any tool, review the current Tabelog rules and robots.txt. Public visibility is not the same thing as unrestricted automated reuse.
Side-by-side
Tabelog scraper alternatives compared
| Option | Best fit | Hosting and code | Output and price shape | Main trade-off |
|---|---|---|---|---|
| UScraper + Tabelog Details Scraper | Analyst-led exports from a known URL list | Local desktop app; low code | CSV named tabelog-details-scraper.csv; free template plus app plan | Best for inspectable local runs, not fleet-scale cloud crawling |
| Octoparse Tabelog templates | No-code teams that want a hosted visual scraper | Desktop builder plus vendor cloud options; low code | Table exports such as CSV or Excel-style files; SaaS subscription tiers | Fast setup and marketplace breadth, but less local custody |
| Apify Tabelog actors | Recurring jobs, APIs, queues, and developer workflows | Vendor cloud; low to medium code | Dataset, JSON, CSV, API access; usage or actor pricing | Strong orchestration, but cloud execution and actor-specific maintenance |
| API-style Tabelog data tools | Product integrations and repeatable data pipelines | Vendor API; developer integration | JSON responses, credits, or request pricing | Clean integration, but less visual control over page-level extraction |
| Managed scraper vendors | Larger data teams that want outsourced scraping | Vendor infrastructure; low internal code | Custom delivery, datasets, or dashboards; contracted pricing | Lower internal maintenance, higher vendor dependency |
| Python or Scrapy scripts | Engineering-owned parsers and storage | Your infrastructure; high code | Any schema you build; engineer time plus hosting/proxy cost | Maximum control, maximum maintenance |
Octoparse publishes Tabelog detail templates, Apify has multiple Tabelog actors, Anysite documents Tabelog restaurant API endpoints, and Bright Data, Thunderbit, Spider, and Scrapebit all position Tabelog scraping as managed or template-based work. That variety makes "best Tabelog scraper" a requirements decision.
Where UScraper wins
When the local CSV route is the better fit
The Tabelog Details Scraper is built for controlled, reviewable extraction from restaurant detail-style URLs. The workflow is intentionally simple:
Navigate -> Wait for Page Load -> Wait for Element
-> Sleep -> Structured Export -> Loop Continue
Navigate holds the URL list. Wait blocks reduce empty rows. Structured Export writes headers and appends one row per loaded page. Loop Continue moves to the next input. Analysts can inspect the graph, run three URLs, open the CSV, and confirm whether names, address, hours, budget, phone, menu, and notes match the browser.
The bundled workflow definition is the source of truth for the export shape. It includes 29 restaurant detail-style columns:
| Field group | Columns |
|---|---|
| Source and identity | source_url, store_name, the_homepage, remarks |
| Tabelog-style profile | rating, the_opening_day, first_reviewers, occasion, location |
| Access and schedule | address, transportation, operating_hours, shop_holidays, tel |
| Commercial details | budget, method_of_payment, table_money, course, drink, dishes |
| Facilities and policy | number_of_seats, private_dining_room, private_use, no_smoking_or_smoking, parking_lot, space_and_facilities, service, with_children |
Where others win
When Octoparse, Apify, APIs, or scripts make more sense
Choose Octoparse when your team prefers hosted no-code templates, a larger scraper marketplace, and SaaS-style cloud runs. It is a reasonable answer for Tabelog scraper vs Octoparse searches when the buyer wants visual setup and vendor-managed infrastructure.
Choose Apify when the project needs cloud actors, dataset storage, scheduled runs, API calls, queues, or developer handoff. Choose an API-style provider when the output needs to flow directly into software. Choose Python, Scrapy, or Playwright scripts when engineers own parsing, tests, retries, logs, and storage.
UScraper wins when the operator wants the browser run and CSV file on the same machine, with no scraper cloud in the middle.
Apify, APIs, and hosted vendors win when remote jobs, webhooks, queues, and programmatic access are core requirements.
Octoparse wins when template breadth and hosted no-code scraping matter more than open workflow inspection.
UScraper wins for small, auditable restaurant batches where a visual local workflow and spreadsheet output are enough.
Decision guide
Which Tabelog data extraction tool should you pick?
Pick by operating model:
- Use UScraper for known URL lists, local desktop runs, editable blocks, and CSV output.
- Use Octoparse or Thunderbit for hosted no-code extraction and visual setup.
- Use Apify for cloud actor workflows, datasets, APIs, and recurring automation.
- Use Anysite-style APIs or managed vendors for integration-first delivery.
- Use Python or Scrapy when engineers need ownership of parsing, tests, retries, and storage.
For the local CSV path, import the free Tabelog Details Scraper template, replace the sample URLs, run a three-page validation batch, and compare the CSV against the browser before expanding the list. You can also browse related workflows in the template library or read more guides in the blog.
FAQ
FAQ
What is the best Tabelog scraper alternative?
The best option depends on hosting, code tolerance, output format, and compliance needs. Use UScraper for local CSV exports, hosted no-code tools for cloud runs, Apify for actors and APIs, API providers for integrations, and scripts for full engineering control.
How does UScraper compare with Octoparse for Tabelog?
Octoparse is stronger for marketplace breadth and hosted no-code scraping. UScraper is stronger when the operator wants editable visual blocks, a local desktop app run, and CSV stored in a local folder.
Is Apify or an API better for Tabelog scraping?
Apify or an API is better for remote execution, scheduled runs, datasets, webhooks, queues, or backend integration. UScraper is better for supervised research runs where the browser flow and CSV need operator review.
What does the UScraper Tabelog Details Scraper export?
The workflow writes tabelog-details-scraper.csv with fields such as source_url, store_name, rating, address, transportation, operating_hours, shop_holidays, budget, method_of_payment, number_of_seats, parking_lot, tel, remarks, course, drink, and dishes.
Is it legal to scrape Tabelog restaurant details?
Legality depends on permission, jurisdiction, data type, access method, volume, and downstream use. Review Tabelog rules and robots directives, avoid bypassing access controls, keep runs modest, and get legal advice before commercial reuse or redistribution.