This Tabelog scraper tutorial shows how to scrape Tabelog restaurant detail-style pages into CSV with the Tabelog Details Scraper for UScraper. You will import the template, replace the URL list, confirm the export path, run a small validation batch, and understand when Python, Apify, Octoparse, or an API-style Tabelog scraper alternative is a better fit.
Before you start
Prerequisites for a Tabelog scraper tutorial
You need UScraper installed as a local desktop app, a writable CSV folder, and a short list of restaurant detail URLs you are allowed to process. Start with three to five URLs from the official Tabelog English site or an internal research list; the first run is for access checks, selectors, and CSV shape.
Before scaling, review the current Tabelog rules and robots.txt. This tutorial is for supervised extraction from pages visible in your browser session, not bypassing logins, CAPTCHA, paid access, private pages, or source rules.
Technical access is not permission. Keep batches modest, collect only fields you need, and get legal review before publishing, reselling, or enriching third-party datasets with restaurant information.
Workflow shape
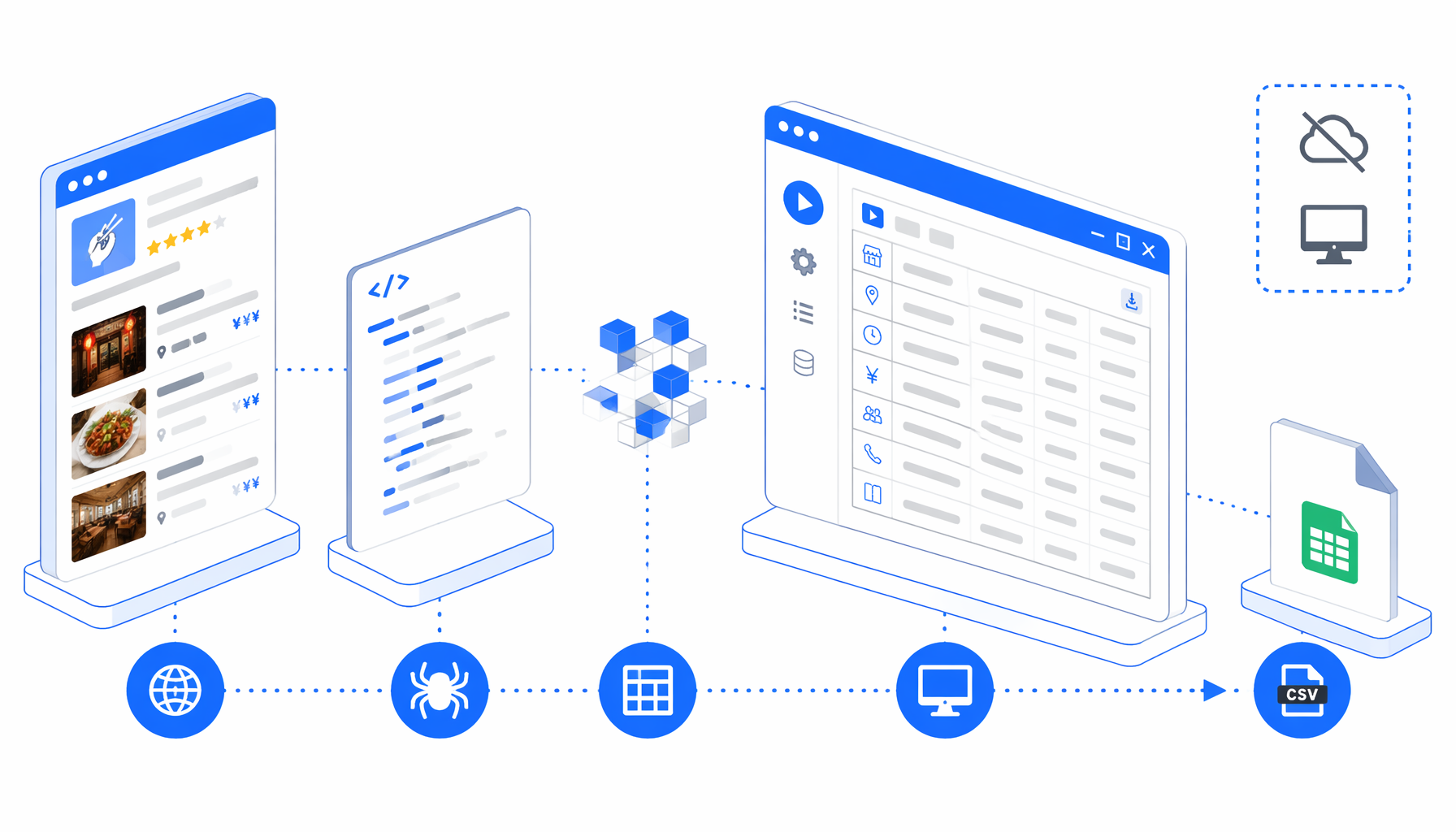
How the Tabelog details scraper workflow works
The JSON export is the operational source of truth. In plain English, the flow is:
Navigate -> Wait for Page Load -> Wait for Element
-> Sleep -> Structured Export -> Loop Continue
Navigate owns the URL list, the wait blocks guard page readiness, Structured Export appends one CSV row, and Loop Continue advances to the next URL.
CSV
29
URL list
Load + body
Local QA
tabelog-details-scraper.csvColumn
source_url
Browser URL for traceability.
Column
store_name
Restaurant name or metadata fallback.
Column
rating
Tabelog rating when exposed.
Column
address
Address from visible labels or copy.
Column
transportation
Access or station guidance.
Column
operating_hours
Opening-hour text.
Column
budget
Average budget or price guidance.
Column
tel
Telephone link or text.
Column
dishes
Courses, drinks, or menu items.
| Field group | Columns in the workflow |
|---|---|
| Source and identity | source_url, store_name, the_homepage, remarks |
| Tabelog-style profile | rating, the_opening_day, first_reviewers, occasion, location |
| Access and schedule | address, transportation, operating_hours, shop_holidays, tel |
| Commercial details | budget, method_of_payment, table_money, course, drink, dishes |
| Facilities and policy | number_of_seats, private_dining_room, private_use, no_smoking_or_smoking, parking_lot, space_and_facilities, service, with_children |
Runbook
How to scrape Tabelog restaurant details to CSV
Import the template
Open Tabelog Details Scraper, download the hosted JSON workflow, and import it into UScraper.
Replace the sample URLs
Open the Navigate block and paste the restaurant detail URLs your team is allowed to collect. Keep one URL per target restaurant and remove tracking parameters where possible.
Keep the load guardrails
Leave Wait for Page Load, Wait for Element, and Sleep in place for the first run. They reduce empty rows caused by reading the page before body text and metadata are ready.
Confirm the export path
In Structured Export, review the save folder, filename, headers, and append mode. The stock filename is tabelog-details-scraper.csv.
Run a validation batch
Run three to five URLs, open the CSV, and compare names, address, hours, budget, phone, menu, and source URL against the browser before widening the batch.
Validation
Validate the Tabelog CSV export
Treat the first CSV as a test artifact. A good Tabelog data extractor should produce rows that are easy to trace back to the browser.
| Check | What to verify | Why it matters |
|---|---|---|
| Source traceability | source_url opens the same restaurant page | Lets analysts audit any suspicious value quickly. |
| Identity | store_name matches the visible restaurant name | Prevents metadata or navigation text from becoming the restaurant name. |
| Location and access | address and transportation match the page | Useful for area research and location QA. |
| Operating detail | operating_hours, shop_holidays, budget | These fields often vary by page layout, so spot-check them early. |
| Amenities and menu | seats, parking, smoking, course, drink, dishes | Blank values can be legitimate or selector-related. |
| Symptom | Likely cause | Fix |
|---|---|---|
| Headers but no rows | Page did not finish loading, body selector failed, or an access prompt appeared | Open the URL manually in the same browser session, then rerun one page. |
| Blank rating or first reviewer | The source URL is not a Tabelog detail page or the current layout hides that data | Treat those fields as optional or adapt selectors for live Tabelog markup. |
| Wrong store name | The page title or metadata fallback won before the correct heading | Inspect the page and move the best selector earlier in the column logic. |
| Duplicate rows | Append mode captured multiple QA runs | Clear the file before reruns or dedupe by source_url and store_name. |
Alternatives
Tabelog scraper alternatives: Python, Apify, Octoparse, and APIs
Searches for best Tabelog scraper, Tabelog scraper Python, and Tabelog scraper alternative usually compare local templates, hosted no-code tools, cloud actors, APIs, and custom scripts.
| Approach | Best fit | Trade-off |
|---|---|---|
| UScraper template | Supervised CSV exports, local browser QA, editable blocks, visible URL lists | You maintain selectors, pacing, and access hygiene. |
| Octoparse Tabelog template | No-code users already running extraction inside Octoparse | Vendor workspace settings, limits, and field behavior control the run. |
| Apify Tabelog actor | Cloud runs, API workflows, and developer-owned ingestion | You manage actor inputs, run costs, storage, and downstream handling. |
| Anysite Tabelog API | API-first enrichment where a managed endpoint fits the project | Field coverage, pricing, usage rights, and data freshness depend on the provider. |
| Python scraper | Full engineering control over selectors, retries, tests, and storage | Requires maintenance, monitoring, throttling, and compliance gates. |
For a research spreadsheet, the local desktop app route works well because the operator can watch pages load and inspect the CSV immediately. For scheduled pipelines, compare custody, scale, API access, run cost, and permissions.
FAQ
Tabelog details scraper FAQ
Tabelog pages and linked restaurant pages may be public but still limited by rules, robots directives, copyright, database rights, privacy law, and local regulations. Avoid access-control bypassing, keep runs modest, and get legal review before commercial reuse.
Next step
Download the Tabelog details scraper template
When you are ready, download the JSON from Tabelog Details Scraper and keep this tutorial open for QA. For discovery workflows, browse UScraper templates; for adjacent walkthroughs, return to the UScraper blog.