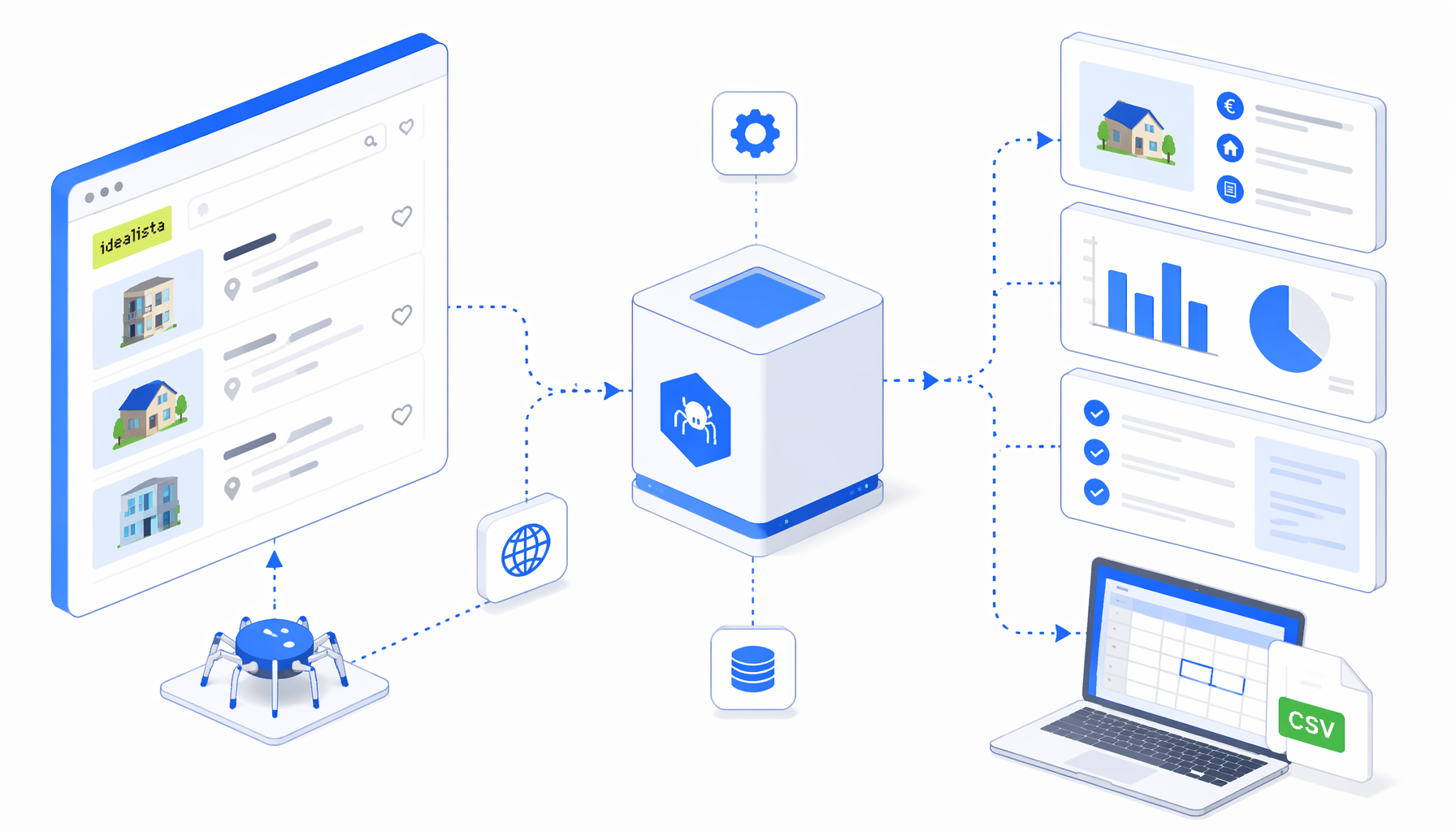
An Idealista property data scraper is useful when the job is not "collect everything" but "turn selected property pages into a reviewable dataset." Research teams, newsroom data desks, SEO teams, and monitoring analysts can use UScraper's Idealista Property Scraper for Detail Pages to export visible detail-page fields into CSV before rows enter reports, dashboards, or editorial workflows.
Problem
Property research breaks when details stay in browser tabs
Idealista is a rich source for property research, but browser tabs are a poor system of record. One analyst copies price, another copies the agent comment, a third records energy certificate text, and nobody remembers whether the page was live, blocked, or partially loaded.
That shows up in four workflows:
- Market research teams shortlist comparable listings.
- Newsrooms check price, location, advertiser text, and listing changes.
- SEO teams review titles, descriptions, neighborhood names, and feature phrases.
- Monitoring teams watch known properties for price, availability, or presentation changes.
The painful part is not opening five property pages. The painful part is repeating that check next week and proving which page produced each row.
Official routes exist for different jobs. The Idealista Search API access request is the place to start for approved product integrations, while idealista/data is better suited to licensed market intelligence. A scraper template fits a narrower use case: selected pages, analyst review, local CSV output, and an inspectable workflow.
Personas
Who uses an Idealista details scraper?
| Team | Pain | CSV outcome | Example decision |
|---|---|---|---|
| Research analysts | Comparable pages are reviewed manually across tabs. | Price, location, features, building details, advertiser, and timestamp. | Keep or reject candidate comps. |
| Newsroom data desks | Reporters need source evidence from live pages. | Page URL, scrape time, title, price, location, agency, and diagnostics. | Support a housing story with auditable rows. |
| SEO teams | Agency listing language is hard to compare. | Titles, advertiser comments, location text, feature phrases, and professional names. | Find title patterns or thin descriptions. |
| Portfolio monitors | A watchlist changes faster than manual sheets. | One row per URL per run, including blocked-page signals. | Spot price, access, or structure changes. |
The key is scope. This is not broad listing discovery. It starts from specific detail URLs gathered from a listing workflow, shortlist, or monitoring sheet.
Workflow
How the template turns pain into structured export
The exported JSON defines a simple, auditable flow:
Set Window Size -> Navigate -> Wait for Page Load -> Sleep
-> Wait for Element -> Element Exists -> Structured Export -> Loop Continue
Navigate holds the URL list. The wait steps let the detail page render. Element Exists checks for title or price signals. The true branch writes property data; the false branch writes a diagnostic row when expected selectors are unavailable.
| Export group | Columns | Why teams care |
|---|---|---|
| Source trail | URL_ingresadas, Página_URL, Hora_actual | Shows source URL and observation time. |
| Core facts | Titulo, Precio, Ubicación, Características_destacadas | Captures the fields researchers check first. |
| Detail sections | Características_básicas, Edificio, Equipamiento, Certificado_energetico | Keeps optional property facts together. |
| Advertiser context | Comentario_del_anunciante, Ref, Profesional, Contacto_URL | Supports SEO, compliance, and editorial review. |
| Media and access state | Imagen, diagnostic text | Makes image references and blocked-page outcomes visible. |
Use cases
Four concrete Idealista scraping workflows
Comparable property research
A valuation analyst may start with twelve Idealista detail URLs around one neighborhood. The goal is not a full real estate database; it is enough evidence for a comp review. Exporting title, price, location, features, building text, equipment, energy certificate, and advertiser description gives the analyst one CSV to filter and annotate.
Run one test URL, compare the CSV against the browser, then add the remaining URLs. Keep each run in a dated file so later checks do not overwrite the snapshot.
Newsroom and policy research
Housing stories often rely on specific examples: properties at a price point, listings in a district, or pages that show how a market condition appears to renters and buyers. The Idealista property market statistics pages and Idealista18 open dataset announcement are useful context, but a newsroom may still need source rows from currently reviewed pages.
The template writes source URL, page URL, timestamp, title, price, location, advertiser text, and diagnostics. That does not replace editorial verification, but it gives editors a cleaner audit trail.
SEO and listing-quality analysis
Real estate SEO teams care about language. How do agencies phrase terraces, renovations, energy certificates, floor level, neighborhood names, or investment angles? A detail-page export lets the team compare Titulo, Ubicación, Comentario_del_anunciante, Características_destacadas, and Profesional.
An analyst can adjust the URL list, rerun a smaller group, and keep the CSV beside the content audit.
Portfolio and watchlist monitoring
Monitoring is repetitive. A team may have forty pages that matter because they are competitor listings, client properties, distressed assets, or market examples. Append mode lets each run add fresh observations with a timestamp.
Use a stable filename for exploratory work, then switch to dated exports for monitoring. A blocked diagnostic row may mean the listing is gone, access changed, or the page structure shifted.
Decision
Idealista scraper vs API vs managed data
| Route | Use it when | Trade-off |
|---|---|---|
| Official Idealista API or licensed data | You need approved integration, redistribution, service levels, or production access. | Requires access request, approval, contracts, or engineering work. |
| idealista/data reports and APIs | You need market-level intelligence, historical indicators, comparables, metrics, or professional datasets. | Stronger for licensed intelligence than page-by-page source review. |
| Hosted scraper actors or scraper APIs | You need cloud schedules, API delivery, retries, remote storage, and larger recurring jobs. | Rows and logs run through a third-party infrastructure layer. |
| UScraper Idealista details template | You have selected detail URLs and need inspectable local CSV output. | Best for controlled batches, not unattended high-volume crawling. |
Risks
Access, legality, and quality checks
Public visibility is not permission. Idealista pages can still be governed by terms, robots directives, copyright, database rights, privacy law, anti-abuse systems, and local real estate rules. Do not bypass CAPTCHA, DataDome, login walls, payment flows, or account-only areas.
Run one URL, open the CSV, and compare title, price, location, features, advertiser comment, reference, agency, contact URL, image URL, and timestamp against the page. Only then add more URLs.
Frequently asked questions
Who should use an Idealista property data scraper?
Use it when a team has reviewed detail URLs and needs repeatable CSV for research, editorial QA, SEO analysis, or monitoring. For production feeds or redistribution, start with official or licensed access.
When is the Idealista API a better fit?
The Idealista API route is better for approved integrations, commercial applications, service-level expectations, or recurring access where permission and reliability matter more than ad hoc spreadsheet review.
What does the Idealista details scraper export?
The workflow writes idealista-detalles-scraper.csv with URL_ingresadas, Titulo, Precio, Características_destacadas, Ubicación, Comentario_del_anunciante, Características_básicas, Edificio, Equipamiento, Certificado_energetico, Ref, Profesional, Contacto_URL, Imagen, Página_URL, and Hora_actual.
Where should I go next?
Start with the Idealista Property Scraper for Detail Pages template, then use the Idealista scraping tutorial for setup steps or the Idealista scraper alternatives comparison if you are still choosing between UScraper, APIs, hosted actors, and scripts.