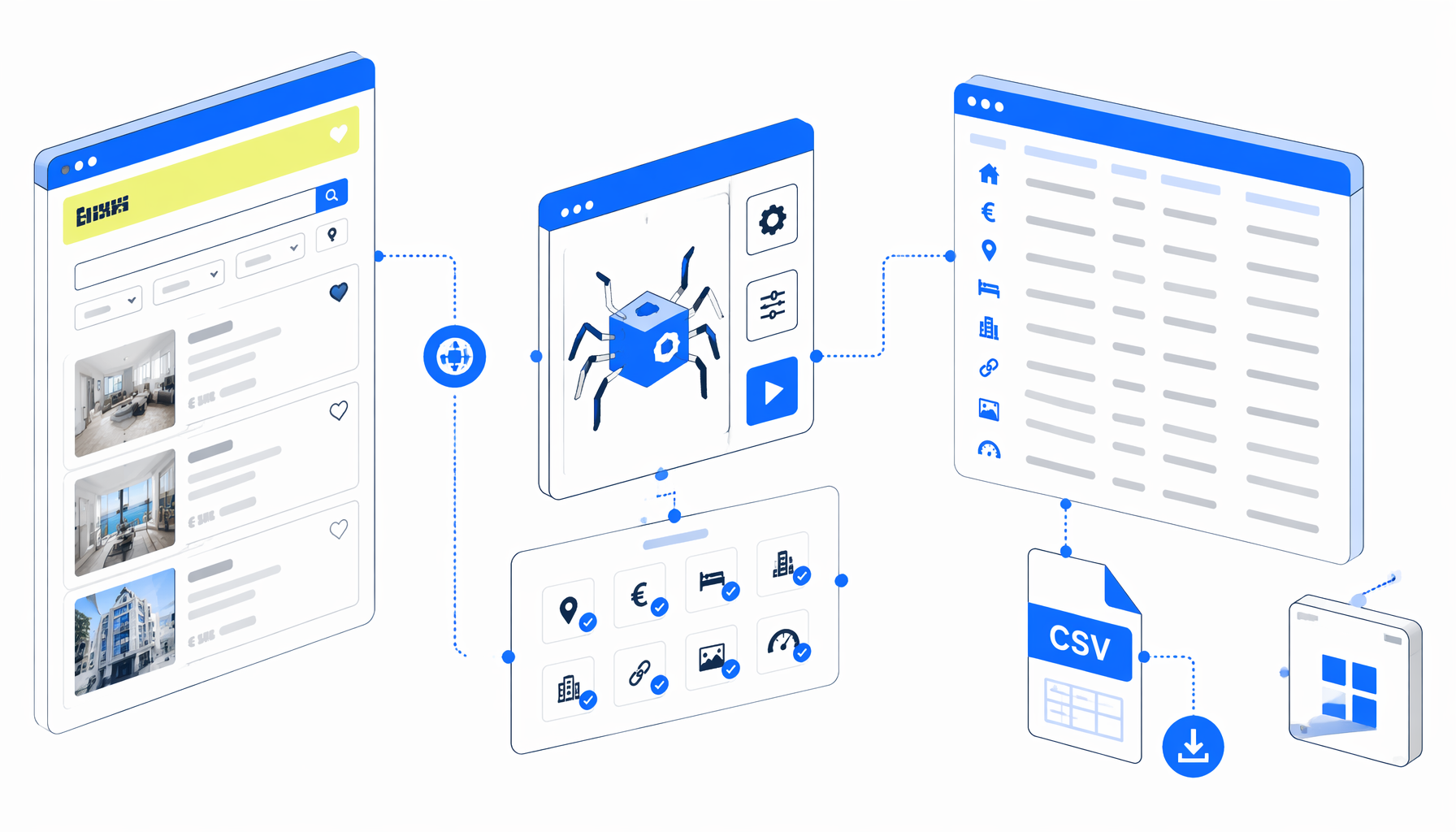
This Idealista scraping tutorial shows how to scrape Idealista property detail pages into CSV with the Idealista Details Scraper template for UScraper. You will import the workflow, replace sample property URLs, set the export path, validate one page, and compare no-code CSV export with API, hosted scraper, and Python options.
Before you start
Prerequisites, scope, and Idealista access checks
You need UScraper installed as a local desktop app, the Idealista Details Scraper template, a writable export folder, and a short list of Idealista property detail URLs you are allowed to process. Start with one to three /inmueble/ URLs because detail pages vary by market, language, property type, advertiser, and browser state.
This guide covers visible property detail pages. It does not cover account dashboards, lead forms, paid partner access, CAPTCHA solving, or bypassing blocked pages. If your project needs approved access, redistribution rights, or formal integration, review Idealista's official API access request before choosing scraping.
Technical access is not permission. Keep first runs visible, stop on verification pages, and document the business reason for collecting each URL.
Workflow shape
What the Idealista details scraper does
The exported JSON is the authoritative workflow definition:
Set Window Size -> Navigate -> Wait for Page Load -> Sleep
-> Wait for Element -> Element Exists -> Structured Export -> Loop Continue
Navigate owns the URL list. The waits give Idealista time to render. Element Exists checks for detail-page signals such as title or price. The true branch exports property data; the false branch writes a diagnostic row for blocked, unavailable, or structurally different pages.
| Export area | Columns | What to validate |
|---|---|---|
| Identity | URL_ingresadas, Titulo, Página_URL, Hora_actual | Confirm the title and source URL match the open browser tab. |
| Price and location | Precio, Ubicación | Compare displayed price, currency, neighborhood, and address text. |
| Property facts | Características_destacadas, Características_básicas, Edificio, Equipamiento, Certificado_energetico | Check optional sections because not every page exposes every module. |
| Advertiser context | Comentario_del_anunciante, Ref, Profesional, Contacto_URL | Validate agency names, references, and contact links before using them downstream. |
| Media and diagnostics | Imagen, blocked-page diagnostic text | Treat image URLs as references, not licensed media assets. |
Runbook
How to scrape Idealista property details to CSV
Import the template
Open Idealista Details Scraper from the templates library, download the JSON workflow, and import it into UScraper.
Replace the sample URLs
Open Navigate and replace the sample Idealista property detail URLs with the pages you reviewed. Keep the list short until you know the selector output is correct.
Confirm browser access
Open one target page manually in the same session. If Idealista shows DataDome, CAPTCHA, login, consent, or a removed listing, resolve the access state before running the workflow.
Set the CSV destination
In Structured Export, confirm idealista-detalles-scraper.csv, headers enabled, append mode, and a clean folder for the project, market, or client.
Run and compare
Run one URL while watching the browser. Compare title, price, location, features, advertiser, reference, contact URL, image URL, and scrape timestamp against the live page.
If the first row looks correct, add URLs in small batches. If a row looks partial, reopen the page, confirm the missing section is visible, then decide whether the page differs or the selector needs maintenance.
Validation
Check the CSV before you trust it
The bundle does not include a sample CSV, so treat the configured export shape as the contract. A healthy row should have a real title, price, location, page URL, and timestamp. Optional equipment, building, energy certificate, image, or agency fields can be blank when the page omits that section.
| URL_ingresadas | Titulo | Precio | Ubicación | Profesional | Comentario_del_anunciante |
|---|---|---|---|---|---|
https://www.idealista.com/inmueble/102275671/ | Piso reformado con terraza | 465.000 euro | Madrid, Centro | Agencia Centro Homes | Vivienda luminosa con terraza, ascensor y reforma reciente. |
https://www.idealista.com/inmueble/103585272/ | Chalet independiente | 725.000 euro | Las Rozas, Madrid | Inmobiliaria Norte | Parcela amplia, garaje, piscina y zonas verdes. |
https://www.idealista.com/inmueble/102356410/ | BLOCKED_BY_DATADOME_OR_CAPTCHA | Idealista returned a DataDome/CAPTCHA or anti-bot interstitial. |
Common issues and fixes
Stop the run and inspect the page manually. The template is designed to record the condition, not work around it. Slow down, reduce the URL list, and use approved access routes when you need reliable production collection.
FAQ
Frequently asked questions
Is it legal to scrape Idealista property detail pages?
Idealista pages may be visible in a browser and still be governed by terms, robots directives, database rights, copyright, privacy law, and local real estate rules. Keep runs modest, avoid bypassing access controls, and get legal review before commercial reuse.
Do I need the Idealista API for this tutorial?
No. This tutorial uses supplied property detail URLs and Structured Export. Use official Idealista API access or licensed data routes when you need approved usage rights, redistribution, or production-scale integration.
What does the Idealista details scraper export?
The workflow writes idealista-detalles-scraper.csv with URL_ingresadas, Titulo, Precio, Características_destacadas, Ubicación, Comentario_del_anunciante, Características_básicas, Edificio, Equipamiento, Certificado_energetico, Ref, Profesional, Contacto_URL, Imagen, Página_URL, and Hora_actual.
Why did the CSV say BLOCKED_BY_DATADOME_OR_CAPTCHA?
That row means Idealista returned an anti-bot interstitial, CAPTCHA, unavailable page, or page structure without expected selectors. Stop, inspect manually, and do not attempt to bypass access controls.
How many Idealista property pages should I scrape at once?
Start with one to three URLs, validate the CSV, then expand only when required fields match the browser. Practical scale depends on permission, pacing, page availability, DataDome or CAPTCHA checks, and selector maintenance.
Next steps
Use Idealista Details Scraper as the download path for this tutorial, then browse the broader UScraper template library for adjacent real estate workflows. For more no-code scraping tutorials, keep the UScraper blog open while you validate each new CSV export.