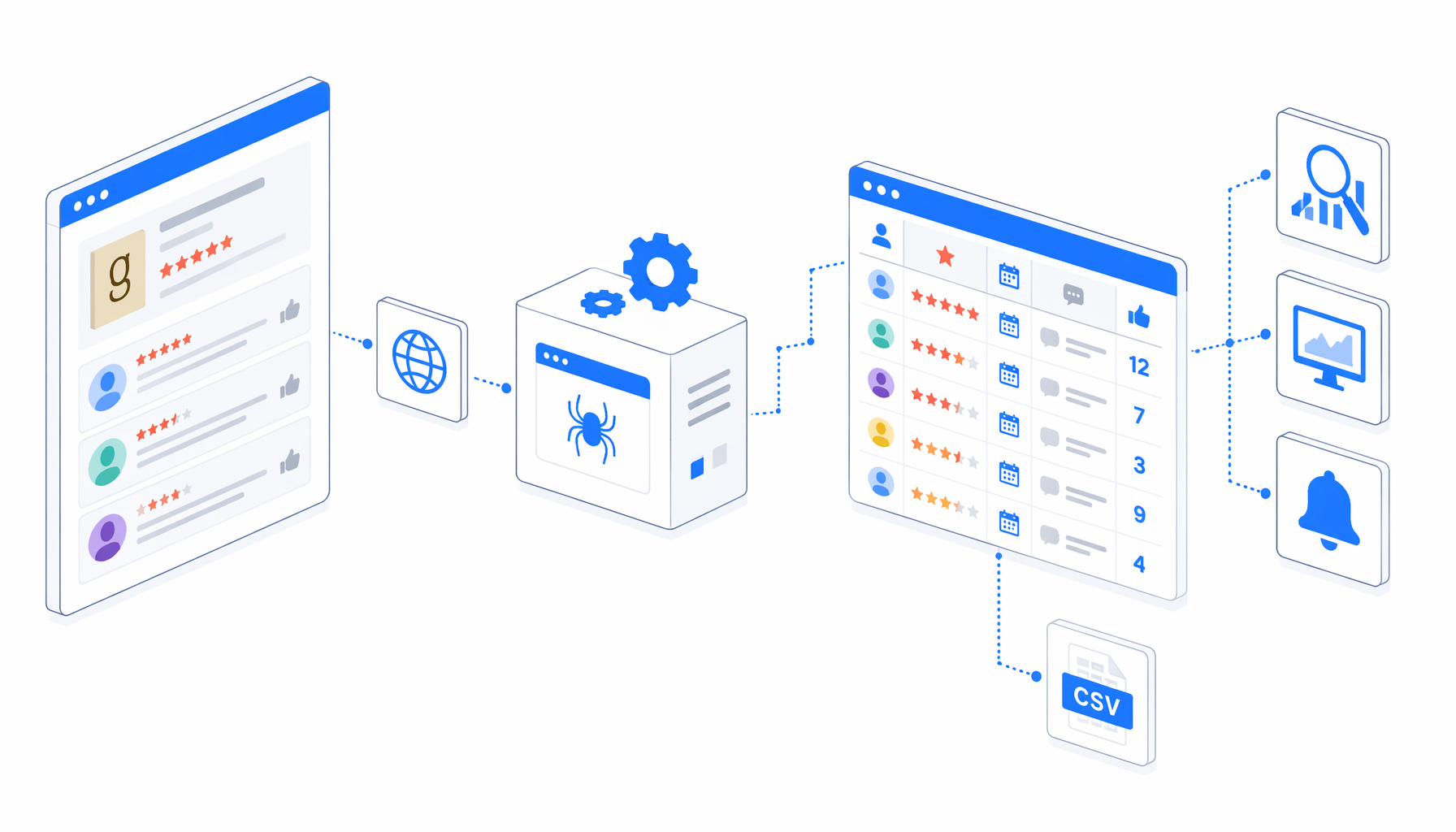
A Goodreads comments scraper is useful when a team needs more than a screenshot of reader reactions. Researchers, publishers, SEO teams, agencies, and newsrooms can use the Goodreads Comments Scraper template to turn selected review pages into a structured CSV with reviewer, rating, date, comment text, likes, book title, author, and page context.
Use-case frame
Why Goodreads review data needs structure
Goodreads reviews are rich because readers write in their own language. A single book page can contain praise, complaints, comparisons, audience signals, spoiler notes, and rating behavior in one place. The problem is that the web page is optimized for reading, not analysis. Copying comments manually breaks context, loses page numbers, and makes it hard to compare rating labels with the actual text.
The Goodreads comments scraper workflow solves that narrow problem: selected review pages in, one structured CSV out. It is not a general permission layer, a review republishing tool, or a workaround for platform controls. Before running any batch, review the current Goodreads terms, robots guidance, and the Goodreads note that it no longer issues new public API developer keys.
Treat the export as a controlled research artifact. Keep the URL list, page range, run date, and raw CSV together so every conclusion can be traced back to its source.
Personas
Goodreads review data analysis use cases
| Persona | Pain | Useful CSV outcome |
|---|---|---|
| Academic researchers | Review text is useful for qualitative coding, but manual capture is slow and inconsistent. | Export comment text with rating, date, book title, author, reviewer name, likes, and page number for an approved corpus. |
| Publishers and authors | Launch positioning depends on how readers describe similar books, not only star averages. | Compare reader language around themes, objections, pacing, audience fit, and emotional response. |
| Newsrooms | Reporting on author risk, fandom behavior, or review dynamics needs traceable examples. | Save selected public review rows with source page context before writing claims or requesting comment. |
| SEO and content teams | Book-list pages and buying guides need real vocabulary from readers, not keyword tools alone. | Cluster recurring phrases, comparison terms, audience labels, and pain points for briefs. |
| Monitoring teams | One-off checks miss changes in review mix, like counts, or recent comment patterns. | Run the same scoped page list over time and compare snapshots downstream. |
Workflow
How the template turns Goodreads pages into a CSV
The Goodreads Comments Scraper template is built around an explicit URL list. The sample workflow includes Goodreads review pages using ?page=N URLs. You replace those with the book and page range you are allowed to process, confirm the export folder, and run the visual workflow.
The graph is intentionally direct: Navigate -> Wait for Page Load -> Wait for Review Cards -> Expand Comments -> Structured Export -> Loop Continue. Structured Export appends each page into one CSV file, and the current_page field gives analysts a quick way to audit coverage.
| Workflow area | What it does | Why it matters |
|---|---|---|
| Page loading | Opens each known Goodreads review URL and waits for review cards. | Avoids mixing discovery with extraction, so scope stays visible. |
| Comment expansion | Clicks visible "show more" controls before export. | Reduces truncated review text when long comments are collapsed. |
| Structured export | Writes one row per visible review card with eight columns. | Produces a spreadsheet-ready output instead of loose copied text. |
| Loop control | Advances through the finite URL list. | Keeps pagination auditable and easy to stop. |
Fields
What the Goodreads reviews scraper exports
The bundled JSON workflow is the source of truth for the export shape. No sample CSV ships with the bundle, so validate your first page against the live browser before using the file for analysis.
goodreads_comments_scraper_reviews.csvColumn
current_page
Page number parsed from the Goodreads review URL.
Column
book_title
Book title from the page heading or document title fallback.
Column
author
Author names found on the book page.
Column
username
Reviewer display name from the review card.
Column
rating
Visible Goodreads rating label, such as really liked it.
Column
comment_time
Visible review date when present.
Column
comment_content
Expanded review text cleaned into one cell.
Column
likes
Visible like count parsed as a number.
Here is a shortened excerpt of the workflow definition. It shows the key mechanics: explicit review-page URLs, append mode, and the configured export columns.
{
"project": {
"name": "Goodreads Comments Scraper"
},
"navigate": {
"urls": [
"https://www.goodreads.com/book/show/17851885-i-am-malala/reviews?page=1",
"https://www.goodreads.com/book/show/17851885-i-am-malala/reviews?page=2"
]
},
"structured_export": {
"fileName": "goodreads_comments_scraper_reviews.csv",
"fileMode": "append",
"columns": [
"current_page",
"book_title",
"author",
"username",
"rating",
"comment_time",
"comment_content",
"likes"
]
}
}
Examples
Concrete workflows for research, SEO, and monitoring
Reader-language research
A researcher studying reception of memoirs can export selected review pages and code themes such as credibility, emotional intensity, classroom suitability, and repeated objections. The rating field helps separate praise from criticism without reducing the study to a star average.
Editorial and newsroom checks
Goodreads has published guidance about protecting review authenticity, including unusual activity and review bombing. For a newsroom, a CSV can support a cautious first pass: recent comments, visible likes, sampled pages, and claims that need direct verification.
SEO and content briefing
SEO teams can use Goodreads review data analysis to understand how readers describe genre, pacing, age fit, comparison titles, and frustrations. Feed the output into internal briefs and topic clusters, not copied public text.
Comparable-title monitoring
Publishers and agencies can monitor comparable books over time. Repeating the same page range lets the team compare recent comments, visible likes, and rating-language mix between snapshots.
Decision
When to use UScraper, Python, or hosted scraping tools
Use UScraper when the deliverable is a supervised local CSV, the page range is known, and analysts want visible workflow blocks without writing parser code.
For setup steps, read the companion Goodreads comments scraper tutorial. For tool selection, use the Goodreads scraper alternatives comparison.
FAQ
Goodreads comments scraper FAQ
Use it when researchers, publishers, SEO teams, agencies, or newsrooms need a reviewable CSV export from selected public Goodreads review pages. It is best for controlled analysis of reader language, rating labels, dates, and visible engagement.
Next step
Download the Goodreads comments scraper template
Use this workflow when you have a defined Goodreads review-page list and need a CSV teammates can inspect. Open the Goodreads Comments Scraper template, run one page, compare the CSV against the browser, and expand only after the fields match.
For adjacent workflows, browse the UScraper template library or return to the UScraper blog for more scraper tutorials, comparisons, and use cases.