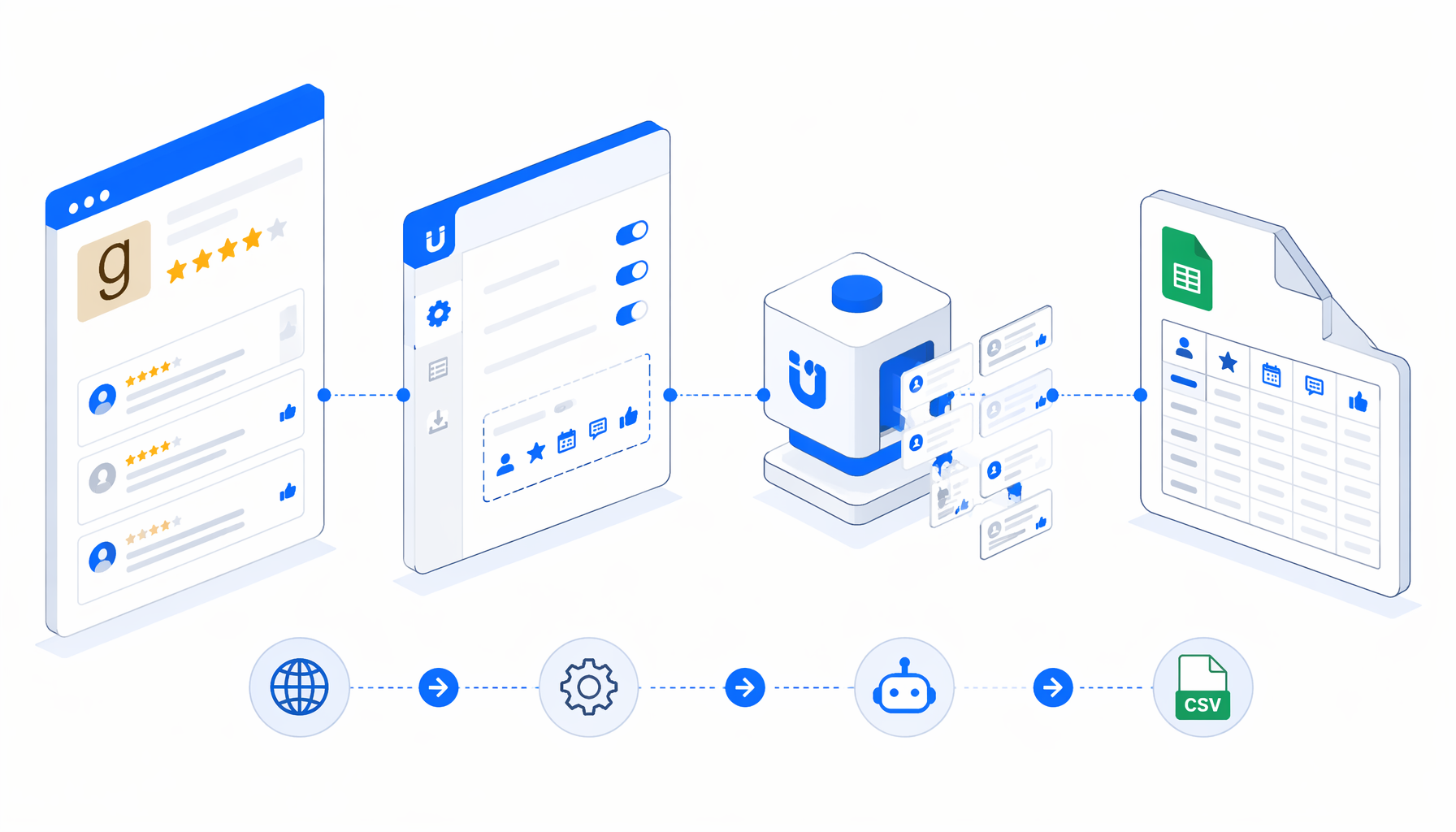
This tutorial shows how to scrape Goodreads comments to CSV with the Goodreads Comments Scraper template for UScraper. You will import the workflow, replace the sample review-page URLs, set the export path, validate one page, and troubleshoot common issues before widening the run.
Scope
Prerequisites and policy checks
You need UScraper as a local desktop app, a Goodreads book review URL list you are allowed to process, and a folder where the CSV can be saved. Start with one book and one or two pages. Goodreads review pages vary by login state, locale, layout experiment, and anti-abuse checks, so a small validation batch is the fastest way to learn whether your selectors still match the live page.
This guide covers visible public review listings only. It does not cover private account pages, login automation, CAPTCHA bypassing, republishing reader comments, or training models on exported review text. Before you run a batch, read the current Goodreads API note, Goodreads robots guidance, and Goodreads terms.
Treat review text as user-generated content. Export only what your research plan needs, keep runs modest, and stop when Goodreads shows a block, challenge, or login wall.
Workflow
How the Goodreads comments scraper workflow works
The companion JSON is intentionally direct: Navigate -> Wait for Page Load -> Sleep -> Wait for Review Cards -> Expand Comments -> Sleep -> Structured Export -> Loop Continue. Navigate owns the finite URL list, Structured Export appends rows into one CSV, and Loop Continue advances to the next ?page=N URL.
The sample workflow ships with pages 1 through 10 for one Goodreads book. Replace those URLs with the book and page range you want to analyze. Keeping pagination as explicit URLs makes audits easier because every row carries current_page.
| Workflow block | Job | What to verify |
|---|---|---|
| Navigate | Opens each Goodreads review URL | Replace sample URLs with your approved scope. |
| Wait blocks | Let review cards render | Watch for slow pages, prompts, or missing cards. |
| Inject JavaScript | Clicks visible "show more" controls | Confirm long comments expand before export. |
| Structured Export | Writes row-scoped fields to CSV | Confirm headers, append mode, and save folder. |
| Loop Continue | Moves to the next URL | Check that duplicate URLs are not in the list. |
Runbook
How to scrape Goodreads comments to CSV
Import the template
Open Goodreads Comments Scraper, download the JSON, and import it into UScraper.
Replace the sample URLs
Edit Navigate with the Goodreads review pages you are approved to collect. Use a finite ?page=N list, such as pages 1 through 3, before trying a longer range.
Set the export path
In Structured Export, confirm goodreads_comments_scraper_reviews.csv, headers enabled, append mode, and a project-specific save folder.
Run one page first
Execute a single URL while watching the browser. Check that review cards appear, long comments expand, and no access prompt replaces the content.
Validate and scale carefully
Compare a few CSV rows against the live page. If the fields match, expand the URL list and keep the same validation habit for each new book.
Output
CSV fields for Goodreads ratings and comments
No CSV sample ships in the bundle, so treat the JSON workflow definition as the source of truth. The field map below summarizes the export shape: one row per visible Goodreads review card, with page context repeated for filtering and QA.
| Column | Meaning | Validation tip |
|---|---|---|
current_page | Page number parsed from the URL | Confirms loop progress and page coverage. |
book_title | Title from heading or document title fallback | Compare against the browser title. |
author | One or more author names | Watch coauthor joins and empty pages. |
username | Reviewer display name | Spot-check against the card header. |
rating | Goodreads rating label | Confirm labels like "really liked it" map correctly. |
comment_time | Visible review date | Dates may be absent on some layouts. |
comment_content | Expanded review text | Make sure "show more" ran before export. |
likes | Visible like count | Empty can be normal when no count is shown. |
goodreads_comments_scraper_reviews.csvColumn
current_page
Source page number from the URL.
Column
book_title
Book title from the page or title fallback.
Column
author
Author names joined into one cell.
Column
username
Reviewer display name.
Column
rating
Goodreads rating label.
Column
comment_time
Visible review date.
Column
comment_content
Expanded review body text.
Column
likes
Parsed like count.
The core Structured Export block uses a row selector with multiple Goodreads review-card fallbacks. The excerpt below is shortened, but it shows the operational intent: wait for review cards, expand visible comment text, then export row-scoped fields.
{
"project": {
"name": "Goodreads Comments Scraper"
},
"blocks": [
{
"title": "Navigate",
"config": {
"urls": [
"https://www.goodreads.com/book/show/17851885-i-am-malala/reviews?page=1",
"https://www.goodreads.com/book/show/17851885-i-am-malala/reviews?page=2"
]
}
},
{
"title": "Wait for Element",
"config": {
"selector": "article.ReviewCard, div.ReviewCard, div.review, [data-testid='reviewCard']"
}
},
{
"title": "Structured Export",
"config": {
"rowSelector": "article.ReviewCard, div.ReviewCard, div.review, [data-testid='reviewCard']",
"fileName": "goodreads_comments_scraper_reviews.csv",
"fileMode": "append",
"columns": [
{ "name": "current_page", "input_type": "js" },
{ "name": "book_title", "input_type": "js" },
{ "name": "author", "input_type": "js" },
{ "name": "username", "input_type": "js" },
{ "name": "rating", "input_type": "js" },
{ "name": "comment_time", "input_type": "js" },
{ "name": "comment_content", "input_type": "js" },
{ "name": "likes", "input_type": "js" }
]
}
}
]
}
Validation
Common issues when scraping Goodreads comments
Goodreads scraping usually fails for mundane reasons: the page did not fully render, text stayed collapsed, the layout changed, or a platform prompt replaced the expected review cards. Keep the browser visible while testing, and do not turn a one-page problem into a ten-page bad export.
| Symptom | Likely cause | Fix |
|---|---|---|
| No rows exported | Review cards did not appear | Open the URL manually, then rerun one page. |
| Short comments only | "Show more" controls did not expand | Keep the JavaScript block and add a longer sleep. |
| Blank ratings | Rating markup changed | Update the rating selector fallback. |
| Repeated rows | Old CSV or duplicate URLs | Start a fresh file or dedupe downstream. |
| Run stops mid-list | Rate limit, block, or access challenge | Pause, reduce volume, and review policy. |
Alternatives
Choose no-code, Python, or hosted Goodreads scrapers
Use UScraper when you want a goodreads scraper no code workflow, browser-visible validation, and a local CSV export. It is the fastest lane for modest research batches where you want to inspect selectors before trusting the data.
For this post, the recommended path is simple: import the Goodreads Comments Scraper template, validate one page, and expand only as far as your permission and research plan allow. For adjacent workflows, browse the UScraper template library or the UScraper blog.
FAQ
Goodreads comments scraper FAQ
Public visibility does not automatically grant permission for automated collection. Review Goodreads terms, robots guidance, copyright, privacy rules, and your own legal basis before running a scraper. Keep batches modest and do not bypass access controls, login prompts, rate limits, or CAPTCHA pages.
Next step
Download the Goodreads comments scraper template
Open Goodreads Comments Scraper, import the JSON into UScraper, and keep this tutorial open while you validate the first CSV. After that, use Templates for related scraping workflows and Blog for more no-code export tutorials.