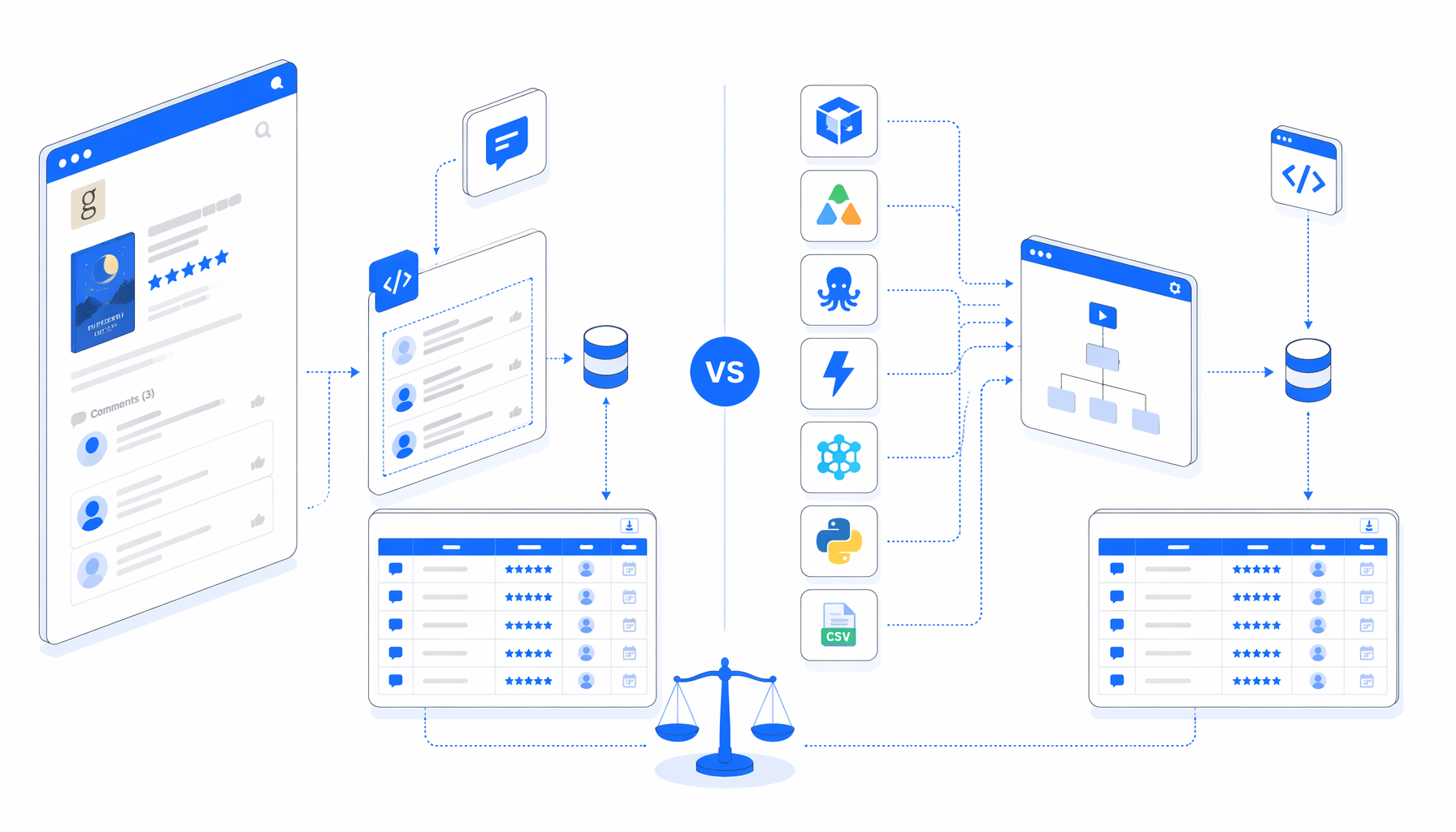
The best Goodreads comments scraper is not just the tool that returns one demo row. For book-review research, the right choice depends on hosting, pricing, code ownership, CSV quality, and how much control you need when Goodreads changes the page. This comparison covers UScraper, Apify, Octoparse, Thunderbit, ParseHub, open-source scripts, and Python tutorials.
Comparison frame
What Goodreads review scraping has to solve
Goodreads review pages combine reader language, rating labels, dates, reviewer names, and like counts around a specific book. A practical Goodreads reviews scraper has to wait for review cards, expand long comments, preserve the source page, handle pagination, and expose failures when a prompt or layout variant appears.
The API route is not a clean escape hatch for new projects. Goodreads' help center says it no longer issues new developer keys for its public API, so most teams compare visual scrapers, hosted marketplace actors, and custom scripts.
The real question is not "can this tool scrape Goodreads?" It is "which workflow produces rows your team can verify, store, afford, and use responsibly?"
Before running any tool, review the current Goodreads terms, robots guidance, and your legal basis. Browser visibility is not permission to republish, resell, or train models on reader comments.
Side-by-side
Goodreads scraper alternatives compared
| Option | Best fit | Hosting | Code needed | Output shape | Pricing shape | Main trade-off |
|---|---|---|---|---|---|---|
| UScraper + Goodreads Comments Scraper | Analyst-led Goodreads comments to CSV | Local desktop app | Low | Local CSV with 8 review fields | Free template plus desktop license | Best for supervised batches, not fleet-scale crawling |
| Octoparse Goodreads Comments Scraper | No-code users who want a hosted template | Vendor cloud | Low | CSV, Excel, or SaaS export paths | Subscription tiers and cloud resources | Convenient, but data and runs live in vendor infrastructure |
| Apify Goodreads Reviews Scraper | Developers who need hosted actors, datasets, and API access | Apify cloud | Low to medium | Dataset, JSON, CSV, API | Platform credits plus actor-specific pricing can apply | Strong automation, but costs and storage are cloud-metered |
| Thunderbit Goodreads template | Fast AI-assisted extraction | Browser extension / SaaS workflow | Low | Tables and connected exports | SaaS plan or credit model | Quick setup, less parser control |
| ParseHub | Generic visual scraping projects across many sites | Vendor app and cloud options | Low to medium | CSV, JSON, API exports | Free and paid subscriptions | Flexible, but project cleanup and limits matter |
| Open-source Goodreads scraper or Python tutorial | Research teams with engineering support | Your environment | High | Whatever you build | Engineering time plus infrastructure | Maximum control, maximum maintenance |
Where UScraper wins
When UScraper is the better Goodreads reviews scraper alternative
UScraper wins when the job is controlled, reviewable, and CSV-first. The Goodreads Comments Scraper template imports as an editable workflow graph: Navigate -> Wait for Page Load -> Wait for Review Cards -> Expand Comments -> Structured Export -> Loop Continue. That is easier to audit than a black-box job that only returns a finished dataset.
The bundled workflow starts from explicit Goodreads review page URLs. Structured Export appends each visited page into goodreads_comments_scraper_reviews.csv with current_page, book_title, author, username, rating, comment_time, comment_content, and likes.
UScraper wins when the operator wants a local desktop app, an inspectable visual flow, and a CSV file written to a selected folder.
Hosted tools win when recurring jobs need remote scheduling, run logs, storage, queues, and API handoff without a user supervising a desktop run.
It depends. Octoparse and Thunderbit are convenient for SaaS setup. UScraper is stronger when local custody and selector visibility matter more.
Scripts win when engineers need tests, custom retries, database writes, proxy orchestration, and versioned parser logic.
Where cloud wins
When Apify, Octoparse, Thunderbit, ParseHub, or scripts make more sense
Choose Apify when developers want hosted actors, datasets, API access, and integrations such as the Apify Zapier integration. The Apify pricing page notes that Store actors may be free or rented, and actor runs consume platform usage credits.
Choose Octoparse when your team approves vendor-cloud no-code scraping and wants templates such as the Goodreads Comments Scraper. Choose Thunderbit for AI-assisted fields and connected exports. Choose ParseHub for a general-purpose visual scraper.
Choose Python when the dataset belongs in an engineered pipeline with tests, queues, retries, database writes, and owned parser maintenance.
Pick UScraper when the deliverable is a spreadsheet for reader-language analysis or editorial notes.
Decision criteria
How to compare price, hosting, code, and output
Use this checklist before choosing a Goodreads comments scraper:
| Question | Favor UScraper if... | Favor another option if... |
|---|---|---|
| What output do you need? | A reviewable local CSV with known columns | API delivery, managed datasets, or app triggers are required |
| Who operates the workflow? | Analysts need visible browser QA and no code | Engineers own parser code and infrastructure |
| Where can the run happen? | Local execution and folder-level CSV custody matter | Vendor-cloud execution is approved |
| How predictable must price be? | A desktop license and free template are easier to justify | Usage credits or SaaS subscriptions are acceptable |
| How much scale is needed? | One book, one author list, or a modest research batch | Large recurring crawls need queues, storage, and monitoring |
UScraper is intentionally narrow: known URLs in, Goodreads review rows out. That is useful for internal research and limiting for large data products.
Policy
Legal and access checks before scraping Goodreads comments
Goodreads comments are user-generated content. Automated collection can raise issues under platform terms, robots guidance, copyright, privacy law, anti-circumvention rules, and research ethics. Keep batches modest, document URLs and page ranges, avoid redistributing raw comments without permission, and do not bypass login walls, CAPTCHA pages, rate limits, or bot checks.
FAQ
Goodreads comments scraper FAQ
It depends on scale, custody, output, and maintenance. Use UScraper for local CSV exports, Apify for hosted actors, Octoparse or Thunderbit for SaaS no-code, ParseHub for a generic visual builder, and Python for parser control.
Next step
Start with the Goodreads Comments Scraper template
If your use case is a controlled research CSV, start with Goodreads Comments Scraper, import the JSON into UScraper, and validate one book review page before widening the URL list. For adjacent workflows, browse the template library, check pricing, or return to the blog for more scraper comparisons and tutorials.