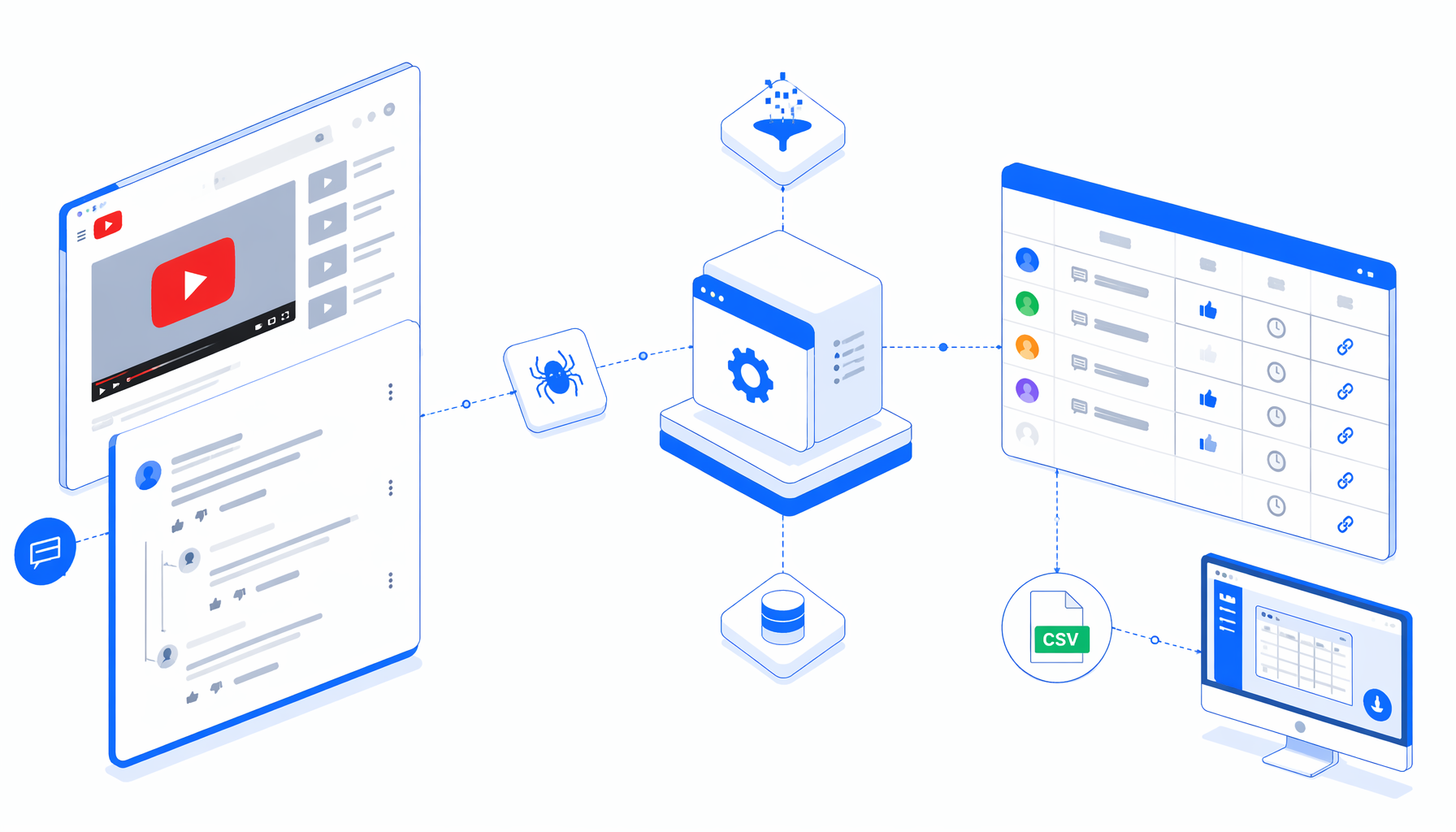
A YouTube comments scraper becomes useful when comments and replies need to move from the browser into a dataset. The YouTube Comments and Replies Scraper template turns known public watch URLs into a local CSV export with parent comments, visible replies, likes, timestamps, crawl time, and links.
Problem
Why YouTube comment replies are hard to analyze manually
Top-level YouTube comments are only half the conversation. Replies often contain corrections, creator follow-ups, audience disagreements, support details, and clarifications that change how the parent comment should be read.
The browser is a poor analysis surface. Comments lazy-load, reply drawers collapse, long comments hide behind read-more controls, and videos can return disabled comments, age gates, sign-in prompts, or region-specific behavior. That is why searches like how to scrape YouTube comments, scrape YouTube comment replies, and YouTube comments scraper tool usually come after manual review fails.
The useful dataset is not "a pile of comments." It is parent comment, reply text, source video, visible timing, engagement signals, and collection notes in one row model.
UScraper fits bounded, supervised exports. It does not promise every historical comment or bypass access controls. It turns the visible state of selected public videos into inspectable rows.
Personas
Who uses YouTube comments and replies data?
| Persona | Pain | Structured export outcome |
|---|---|---|
| Public-interest researchers | Parent comments and replies are separated. | Export thread context for coding, annotation, and audit trails. |
| Newsrooms | Public reaction changes quickly. | Preserve a dated sample editors can filter and spot-check. |
| SEO teams | Viewer questions hide under tutorials and competitor videos. | Mine repeated phrases, objections, and content gaps. |
| Creator teams | Support requests and ideas scatter across uploads. | Group comments by video, likes, and recurring needs. |
| Brand monitoring teams | Social listening needs conversation context. | Review launch, sponsor, and competitor videos with reply-aware rows. |
The common thread is a known source list. Use a YouTube search or video-list workflow for discovery, then run comments and replies after the sample is defined.
Workflow
How this template delivers structured YouTube comment exports
The JSON workflow is the authoritative sample. It sets a large viewport, loops through YouTube watch URLs, waits for the watch page, scrolls to lazy-load comments, clicks visible read-more and reply controls, creates hidden export rows, then writes them through Structured Export.
Set Window Size -> Navigate -> Wait for Page Load -> Wait for watch page
-> scroll and expand comments -> create export rows -> Structured Export
-> Loop Continue
The template creates one row for a standalone parent comment. When replies load, it repeats the parent fields and fills the reply fields, making the CSV easy to filter by video, parent commenter, or reply author.
Fields
Export shape for research, SEO, monitoring, and sentiment analysis
There is no separate CSV sample in the bundle. The exported JSON definition defines the workflow and the Structured Export columns.
| Export group | Columns | Why it matters |
|---|---|---|
| Source video | video_url, video_title | Keeps each row tied to the original watch page. |
| Parent comment | comment_user, content, comment_time, like_count, dislike_count | Preserves the top-level comment that anchors the thread. |
| Reply context | reply_user, reply_content, reply_comment_time, reply_like_count, reply_dislike_count, reply_count | Lets analysts see reply text beside the parent comment. |
| Audit fields | post_comment_count, CrawlTime, comment_url | Supports QA, reruns, source checks, and reporting notes. |
youtube-comments-replies-scraper.csvColumn
video_url
The source YouTube watch URL.
Column
video_title
Visible video title from the watch page.
Column
comment_user
Top-level comment author.
Column
content
Parent comment text after read-more expansion.
Column
comment_time
Visible publish label for the parent comment.
Column
like_count
Visible like count for the parent comment.
Column
reply_user
Reply author when replies are loaded.
Column
reply_content
Reply text paired with the parent comment.
Column
reply_count
Number of loaded replies attached to the parent thread.
Column
comment_url
Comment permalink when YouTube exposes one.
{
"rowSelector": "[data-uscraper-comment-row]",
"fileName": "youtube-comments-replies-scraper.csv",
"fileMode": "append",
"columns": [
"video_url",
"video_title",
"comment_user",
"content",
"comment_time",
"like_count",
"reply_user",
"reply_content",
"post_comment_count",
"CrawlTime",
"reply_count",
"comment_url"
]
}
Use cases
Concrete workflows for comment and reply analysis
Research coding
Export a defined sample, then label rows for topic, stance, sentiment, moderation category, or speaker role. Keep source URLs attached.
Newsroom review
Preserve a dated sample from videos tied to a public event. Editors can inspect reply chains before quoting or escalating a comment.
SEO question mining
Scrape tutorial, comparison, and competitor videos, then group repeated questions. Replies often reveal the follow-up intent.
Creator feedback triage
Review recent uploads, sort by likes, and tag feature requests, support issues, complaints, praise, and follow-up ideas.
Social listening and sentiment
Export launch, sponsor, or competitor videos for repeatable monitoring. Run sentiment analysis after deduplication and compliance review.
For setup, use the YouTube comments and replies tutorial. If you are choosing tooling, compare YouTube comments scraper alternatives or browse the template library.
Access path
YouTube comments API vs scraper for reply-aware work
The official route is the YouTube Data API. The commentThreads.list endpoint returns matching comment threads, comments.list can retrieve comment resources such as replies, and the API pagination guide explains page-token iteration.
| Route | Best fit | Trade-off |
|---|---|---|
| YouTube Data API | Approved apps, documented JSON, pagination, and integrations | Requires setup, credentials, schema work, and policy review. |
| UScraper template | Supervised local CSV exports from known watch URLs | Depends on rendered page state, selectors, and bounded scrolling. |
| Hosted scraper platform | Cloud schedules, APIs, datasets, and larger queues | Adds vendor custody, usage billing, and platform behavior. |
| Custom script | Owned storage, retries, tests, and parser control | Highest control and highest maintenance burden. |
Use the API for product features or sanctioned pipelines. Use the template when the deliverable is a reviewable spreadsheet and an analyst needs to see the browser flow.
QA
Validation checklist before analysis
- Save the source video list and explain why each video was included.
- Run one public video first and compare parent and reply rows against the browser.
- Record run date, template version, row count, blocked pages, and any selector edits.
- Treat blank reply fields as a data state, not as proof that no replies exist.
- Dedupe repeated test runs before coding, sentiment analysis, or AI enrichment.
- Stop on sign-in, age-gate, CAPTCHA, private video, payment, or unusual traffic screens.
The template creates rows; the runbook makes those rows easier to explain later.
FAQ
YouTube comments and replies scraper FAQ
Use it when researchers, newsrooms, SEO teams, creators, agencies, or brand monitors have defined public YouTube watch URLs and need parent comments plus visible replies in CSV.
Next step
Download the YouTube comments and replies scraper template
Use the YouTube Comments and Replies Scraper template when your team has a defined video list, a specific analysis question, and a need for local CSV output. Run one approved video first, validate parent and reply rows, then expand the batch. For neighboring workflows, browse the UScraper blog and all UScraper templates.