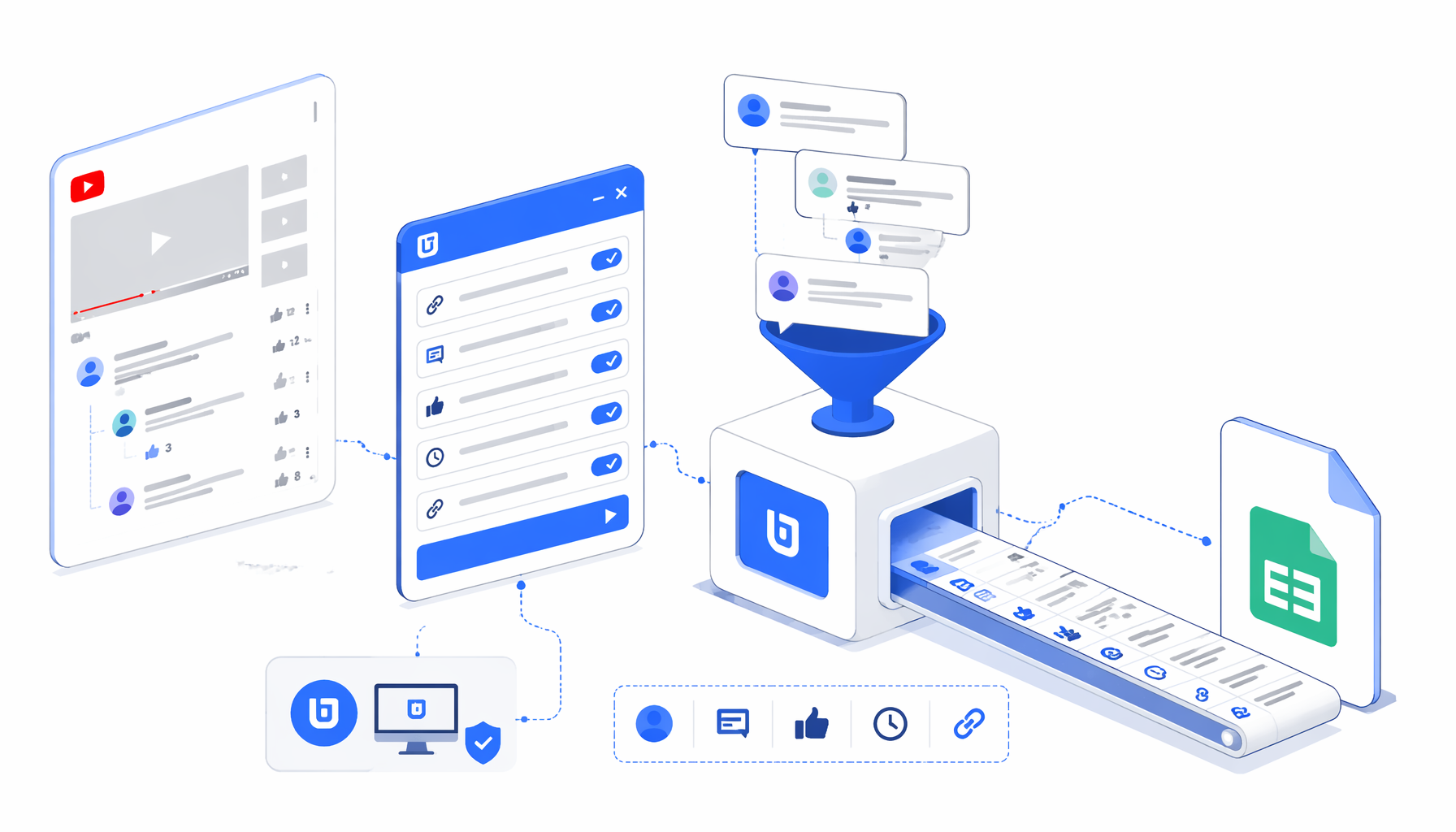
This tutorial shows how to scrape YouTube comments and visible replies into CSV with the YouTube Comments and Replies Scraper template for UScraper. You will import the workflow, set video URLs, validate rows, and understand where the official API path fits.
Before you start
Prerequisites and compliance checks
You need the UScraper local desktop app, public YouTube video URLs you are allowed to review, and a folder for the CSV export. Start with one or two normal videos before adding campaign or competitor lists.
This workflow is for visible public comment research, not bypassing platform controls. Public pages can still be limited by YouTube terms, robots rules, copyright, privacy law, and local regulations.
The practical test is simple: if a human cannot load the comments and replies in the browser session without special access, the scraper should not be expected to export them.
API context
YouTube comments API pagination, replies, and limits
The official YouTube Data API is the structured route. The commentThreads.list endpoint returns comment threads for a video when you pass videoId. The comments.list endpoint retrieves replies with parentId. Both list methods support maxResults up to 100, and the pagination guide explains the nextPageToken loop.
Many "youtube comments scraper python" tutorials are API tutorials: request a page, store nextPageToken, request the next page, and repeat. UScraper is a YouTube comments API alternative for supervised CSV exports without pagination code.
Workflow anatomy
What the YouTube comments and replies scraper does
The bundled JSON is the authoritative workflow sample. It sets a 1920 by 1080 viewport, navigates through the video URL list, waits for the watch page, injects a browser script, waits for synthetic export rows, and runs Structured Export in append mode.
The script scrolls for up to 65 passes, clicks visible controls, stops when loaded comments stabilize, and creates hidden data-uscraper-comment-row elements for export.
| Workflow block | What it does | What to check |
|---|---|---|
| Set Window Size | Opens the browser at a stable desktop viewport | Keep the size unless your page needs a different responsive layout. |
| Navigate | Loops through your YouTube watch URLs | Replace the sample URLs with approved video links. |
| Wait for Element | Confirms the watch page rendered | If this fails, the page may be blocked, unavailable, or still loading. |
| Inject JavaScript | Scrolls, expands replies, and creates export rows | Validate one video after YouTube layout changes. |
| Structured Export | Writes custom CSV columns from row attributes | Confirm save folder, filename, headers, and append mode. |
| Loop Continue | Advances to the next video URL | Use it only after the first export looks correct. |
Runbook
How to scrape YouTube comments and replies to CSV
Import the template
Open the YouTube comments and replies template, download the JSON, and import it.
Paste video URLs
Replace the sample Navigate URLs with public https://www.youtube.com/watch?v=... links. Keep one video per loop input.
Confirm the export path
In Structured Export, set the save folder and confirm youtube-comments-replies-scraper.csv.
Run one validation video
Run a single URL first. Watch whether comments load, read-more buttons expand, reply drawers open, and hidden export rows are created.
Scale the URL list carefully
Add more videos only after the first CSV rows match the browser. Keep notes for blocked or skipped URLs.
After the first run, sort by video_url. Standalone comments have blank reply fields; reply rows repeat the parent fields.
Output
CSV columns produced by the scraper
The export is spreadsheet-first: source fields, parent comment fields, reply fields, visible totals, crawl time, and a comment permalink when YouTube exposes one.
| Column | Meaning |
|---|---|
video_url, video_title | Source video and visible title. |
comment_user, content, comment_time | Parent comment author, text, and publish label. |
like_count, dislike_count | Visible like count and unavailable dislike placeholder. |
reply_user, reply_content, reply_comment_time | Reply author, text, and publish label. |
reply_like_count, reply_dislike_count, reply_count | Reply engagement fields and loaded reply count. |
post_comment_count, CrawlTime, comment_url | Visible total count, export time, and comment link. |
Quality checks
Validation and common issues
YouTube pages lazy-load aggressively, so keep the browser beside the CSV and check rows near the start, middle, and end of the run.
| Symptom | Likely cause | Fix |
|---|---|---|
| Empty CSV | Comments never loaded or a gate screen appeared | Open the video manually and rerun one URL. |
| Parent comments export but replies are blank | Reply drawers did not open | Confirm replies are visible and rerun a smaller batch. |
| Duplicate rows | Append mode reused an old file | Clear the CSV or use a project-specific filename. |
| Low row count | YouTube did not load every comment | Treat the file as a best-effort visible export. |
For recurring projects, log video URLs, run date, CSV filename, row count, skipped URLs, and selector or wait changes.
Choosing a path
Best YouTube comments scraper path for your use case
There is no single best YouTube comments scraper for every job. Choose based on access model and maintenance.
| Approach | Best for | Trade-off |
|---|---|---|
| YouTube Data API | Approved apps and repeatable schemas | Requires API setup, pagination, and policy review. |
| Python scraper scripts | Developer control over parsing and storage | You own maintenance and blocking behavior. |
| UScraper template | Supervised local CSV without code | Browser-visible page state matters. |
| Hosted scraper products | Scheduling and managed infrastructure | Usually usage-based and cloud-routed. |
For a spreadsheet review, the UScraper template is usually shortest. For product features, start with the official API.
FAQ
Frequently asked questions
Public visibility does not mean unrestricted reuse. Review terms and laws; do not bypass gates or collect private data.
Next step
Download the YouTube comments and replies scraper
Use the YouTube Comments and Replies Scraper template as the import path, then validate one CSV before running a larger list. For neighboring workflows, browse all UScraper templates or the UScraper blog.