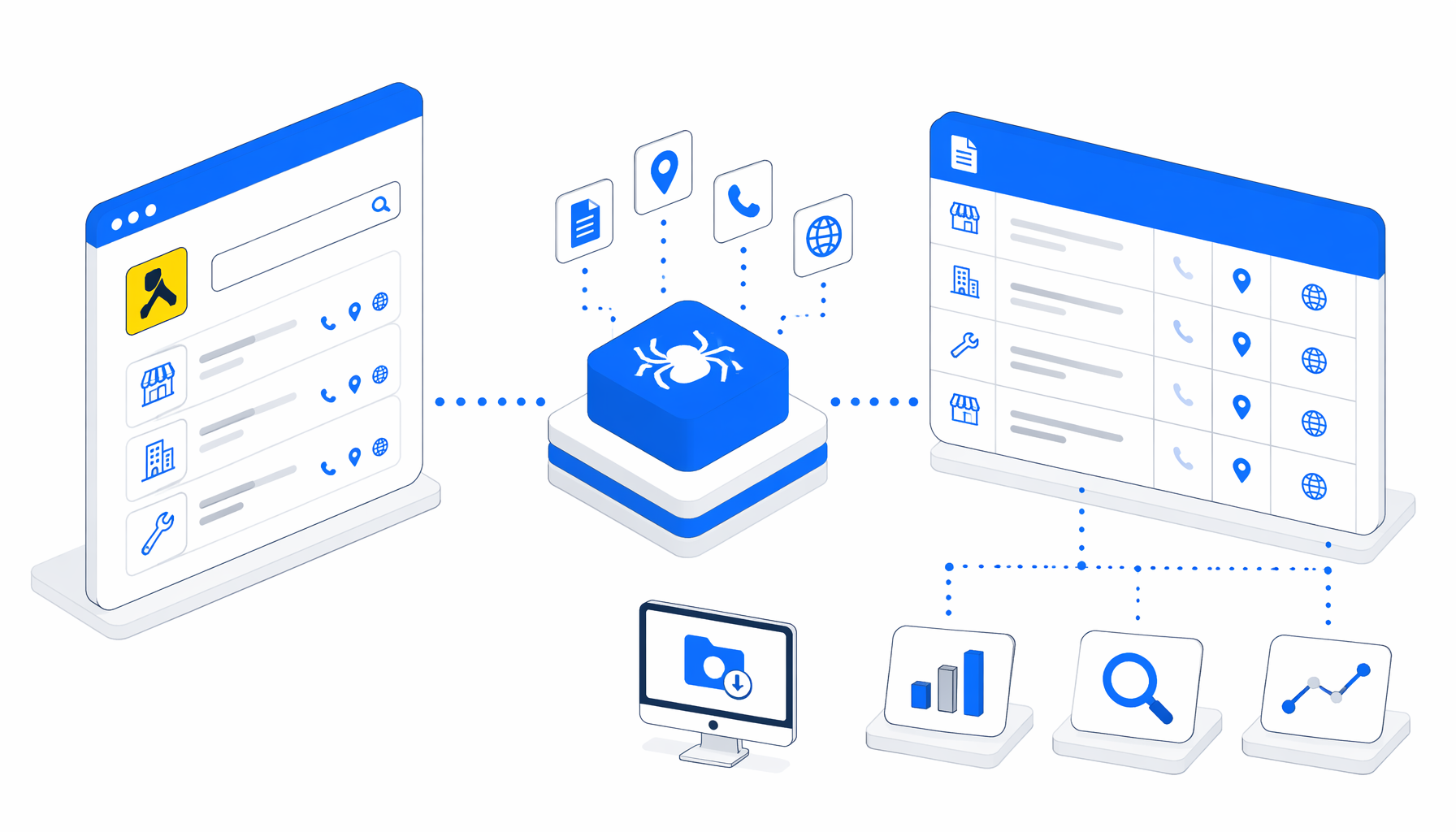
A YellowPages Canada scraper is useful when the goal is not "download the whole directory." It is useful when a team already has approved YellowPages.ca business detail URLs and needs a clean CSV export for research, SEO, newsroom checks, monitoring, or local lead review. The YellowPages Canada Scraper for CSV Export turns that narrow job into an inspectable local desktop app workflow.
Use-case frame
Why scrape Canadian business listings into a CSV?
YellowPages.ca is built for browsing Canadian businesses, products, services, addresses, phone numbers, websites, and reviews. That is useful in a browser, but it becomes slow when a team needs to compare many records, keep source URLs, deduplicate profiles, or hand a spreadsheet to another team.
That is the real pain behind searches like how to scrape Yellow Pages Canada, yellowpages ca scraper tutorial, and scrape Canadian business listings. The user usually does not need an abstract web crawling project. They need a repeatable table from specific business pages they are allowed to inspect.
A directory profile without its source URL, category, location, and collection date is weak evidence. A CSV row with those fields can be checked, filtered, and corrected later.
Before automation, review the live YellowPages.ca directory, current robots.txt, and Yellow Pages Canada terms of use. Public page access is not the same thing as permission to reuse or redistribute data.
Pain to outcome
Common YellowPages Canada scraper workflows
The problem
A researcher has twenty browser tabs open and no consistent way to compare businesses by city, category, phone, or website.
What you do instead
Export one row per approved business detail URL.
The CSV keeps business_name, detail_url, address fields, phone, website, category, rating signals, and description together.
The problem
An SEO team needs local entity examples, but manual copy-paste leaves out source context.
What you do instead
Use the export as a brief-building table.
Filter by category, city, province, website availability, and description text before writing local landing pages or competitor notes.
The problem
A newsroom or analyst needs to verify claims about local business coverage without turning screenshots into a spreadsheet by hand.
What you do instead
Create an auditable sample, then verify rows against live pages.
Keep the source URL and run date beside each row so editors can re-open examples before publishing.
The problem
A monitoring team wants to revisit the same businesses over time, but each manual pass misses different fields.
What you do instead
Re-run the same URL list and compare CSV exports.
Changes in phone, website, current status, rating count, or profile availability become review signals instead of scattered notes.
Personas
Who uses a YellowPages Canada extractor?
| Persona | Typical question | Useful CSV outcome |
|---|---|---|
| Market researchers | Which businesses appear in this category and province sample? | Business name, category, address parts, phone, website, rating fields, and source URL. |
| SEO teams | What local entities and service categories should a content brief reference? | Category text, city, province, website availability, description snippets, and canonical profile URLs. |
| Newsrooms | Do the examples in a story still exist, and what source page backs each one? | A documented working sheet with detail URLs, names, locations, status fields, and collection context. |
| Agencies | Which local businesses should be reviewed before outreach or CRM enrichment? | A spreadsheet that can be deduplicated, annotated, verified, and imported after compliance review. |
| Operations teams | Which candidate suppliers or locations should be screened next? | Address, phone, website, category, and description fields for internal qualification. |
The workflow is intentionally modest. It is not a full search-results crawler, a commercial data resale feed, or an API replacement. It is a local desktop app run for controlled YellowPages.ca detail URLs.
How the template helps
From YellowPages.ca pages to structured export
The bundled JSON uses a readable path: Navigate -> Wait for Page Load -> Wait for Element -> Element Exists -> Structured Export -> Sleep -> Loop Continue. Navigate holds the input URLs. The wait blocks let each page render. The Element Exists block checks for a LocalBusiness-style detail page before export. Structured Export appends the fields into the CSV. If the page is unavailable or not a valid detail page, the false branch waits briefly and advances.
{
"fileName": "yellow-pages-canada-scraper-product-listing.csv",
"rowSelector": ".page__container[itemtype='http://schema.org/LocalBusiness']",
"validPageCheck": ".page__container[itemtype='http://schema.org/LocalBusiness'], h1 .merchantName, .merchantName",
"mode": "append"
}
That shape matters because business directory projects fail when bad inputs quietly create bad rows. A known detail URL loop is easier to QA: every row points back to the page that produced it.
Spreadsheet-ready deliverable
Export to CSV for Excel, Sheets, CRM cleanup, enrichment review, or internal research workflows.
Controlled input loop
Start from a vetted URL list instead of assuming every category search page has stable pagination and fields.
Local desktop custody
The stock workflow writes to a folder you configure in the desktop app; it does not send the CSV to a hosted scraping dashboard.
Validation before export
The condition block checks for a business detail container so unavailable pages do not become misleading blank records.
Output shape
What the YellowPages Canada CSV includes
yellow-pages-canada-scraper-product-listing.csvColumn
keyword
The what parameter from the current URL, such as supermarket.
Column
location
The where parameter from the current URL, such as Canada.
Column
business_name
Visible business name from the merchant heading.
Column
detail_url
The exact YellowPages.ca URL opened during the run.
Column
canonical_url
Canonical business URL when exposed by the page.
Column
address
Visible address text plus separate city, province, and postal code columns when available.
Column
telephone
Primary visible phone number.
Column
website_url
Outbound website link when present on the listing.
Column
rating
Rating value or label when the profile exposes one.
Column
description
Business description or details text when available.
Additional columns include city, province, postal_code, category, website_text, rating_count, current_status, and editors_pick. Treat blank cells as QA signals. A blank website might mean the business has no visible website, the page layout changed, or the run hit a prompt or unavailable state.
Workflow examples
Concrete use cases for YellowPages.ca business data
Local market mapping
Build a vetted list of business detail URLs for one city and category, export profile fields, then group rows by category, province, website availability, or rating count.
SEO entity research
Use names, categories, descriptions, and location fields to understand how local competitors describe services before drafting briefs or landing page outlines.
Newsroom verification
Collect a small documented sample for a story, keep source URLs with every row, and re-open profiles before publication to confirm names, addresses, and status fields.
Vendor discovery
Screen Canadian suppliers or service providers by city, category, phone, and website before sending rows into a procurement or CRM review process.
Directory QA monitoring
Re-run the same URL list on a schedule you are allowed to use, then compare missing profiles, changed phone numbers, website changes, and rating count movement.
For a step-by-step setup, use the YellowPages Canada scraper tutorial. If you are still choosing tooling, compare YellowPages Canada scraper alternatives. The broader blog library and template library cover related directory, search, and contact extraction workflows.
Guardrails
Compliance and quality checks before export
| Guardrail | Why it matters |
|---|---|
| Review current policy pages | Terms, robots guidance, privacy rules, database rights, and marketing laws can affect collection and reuse. |
| Keep batches small at first | Five to ten URLs are enough to confirm selectors, prompts, blanks, duplicates, and output paths. |
| Do not bypass controls | Stop or handle the page manually where allowed if YellowPages.ca shows CAPTCHA, rate limits, login prompts, or access warnings. |
| Preserve source URLs | Every exported row should keep detail_url and, when available, canonical_url for audit and correction. |
| Validate before outreach | Phone numbers, websites, ratings, and descriptions should be checked before CRM import, resale, or outbound campaigns. |
The safest first run is deliberately boring: import the YellowPages Canada Scraper for CSV Export, replace the sample URLs with a few approved detail pages, run one URL, compare the CSV against the browser, then scale only after the rows match your expectations.
FAQ
Frequently asked questions
A YellowPages Canada scraper is useful for researchers, SEO teams, newsrooms, agencies, and monitoring teams that need a controlled CSV from approved YellowPages.ca business detail URLs. It is best for auditable research batches, not for bypassing access controls or redistributing directory data without permission.