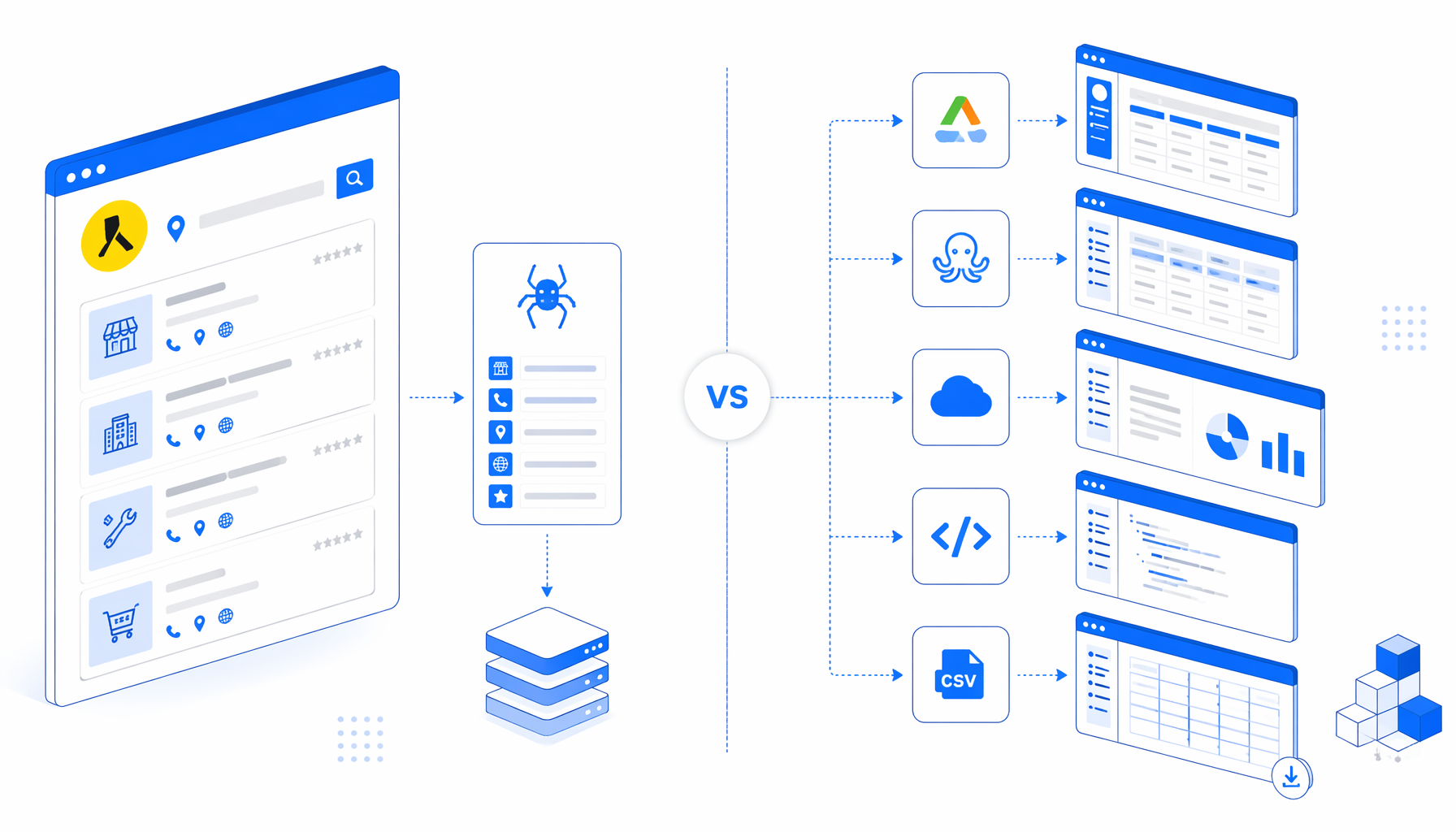
The best YellowPages Canada scraper is not automatically the largest marketplace actor or newest no-code template. For business listing research, compare where the browser runs, how pricing is metered, who maintains selectors, and whether the deliverable is a local CSV. This guide compares Apify, Octoparse, SaaS scrapers, scripts, and UScraper's YellowPages Canada Scraper for CSV Export.
Comparison frame
What a YellowPages Canada scraper has to solve
YellowPages.ca is a Canadian business directory, so a useful scraper has to preserve more than a business name. Good exports keep search context, source URL, canonical URL, address parts, phone, website, category, rating signals, status, and description together for later audits.
That is why "how to scrape YellowPages.ca" searches usually split into four lanes: marketplace actors, no-code SaaS templates, managed services, and local desktop app workflows. Each can work; fit matters more than logo.
Before comparing vendors, review the live YellowPages.ca site, current robots.txt, and terms of use. Technical access is not permission to reuse data.
The practical question is not "which tool can scrape YellowPages.ca?" It is "which workflow creates business listing rows your team can defend, maintain, and afford?"
Side-by-side
YellowPages Canada scraper alternatives compared
| Option | Best fit | Hosting | Code needed | Output shape | Pricing shape | Main trade-off |
|---|---|---|---|---|---|---|
| UScraper + YellowPages Canada Scraper | Local CSV from approved business detail URLs | Local desktop app | Low: visual blocks and selectors | CSV with business detail fields | Free template; app licensing applies | You own validation and selector upkeep |
| Octoparse product listing and details templates | Hosted no-code extraction by keyword/location or URL | Vendor workspace | Low | CSV/Excel-style exports | SaaS plans, task limits, and cloud usage | Convenient setup, less local custody |
| Apify YellowPages Canada actors | Cloud jobs, datasets, and API access | Apify cloud | Low to medium | Dataset, JSON, CSV, API | Platform usage plus actor/runtime cost | Strong orchestration, metered infrastructure |
| GetOdata, Spider, WebAutomation-style hosted scrapers | Vendor-packaged extraction without building parsers | Vendor cloud | Low | Downloadable or dashboard data | Tool-specific credits or subscriptions | Fast to try, vendor quality varies |
| ParseHub-style visual builders | Custom visual scraping projects | Vendor cloud | Low to medium | CSV, JSON, integrations | Tiered SaaS | Flexible, but setup and limits depend on page complexity |
| GitHub scripts and custom code | Engineering teams that want full parser control | Your infrastructure | High | Whatever you build | Engineer time plus proxies/rendering | Maximum control, maximum maintenance |
Apify vs Octoparse vs UScraper
How the main choices differ in practice
Apify fits developer pipelines. Actors can expose datasets and APIs for scheduled runs, downstream jobs, webhooks, and cloud logs. The trade-off is hosted execution and usage-shaped cost.
Octoparse fits hosted no-code teams. Its Yellow Pages Canada listing and detail templates cover common visual workflows. The trade-off is that task state and cloud execution sit inside a SaaS environment.
UScraper runs in a local desktop app. The block graph is visible, and Structured Export writes CSV to the configured save folder. That fits analysts who need to inspect waits, branches, and selectors before each batch.
Where UScraper wins
Why the local desktop app template is useful
The companion workflow is deliberately narrow. It loops through configured YellowPages.ca business detail URLs, waits for the body, checks for a LocalBusiness-style container, exports configured columns, sleeps, and advances. If a URL is unavailable or not a detail page, the false branch continues instead of appending a misleading blank row.
{
"workflow": "Navigate -> Wait for Page Load -> Wait for Element -> Element Exists -> Structured Export -> Sleep -> Loop Continue",
"fileName": "yellow-pages-canada-scraper-product-listing.csv",
"rowSelector": ".page__container[itemtype='http://schema.org/LocalBusiness']",
"mode": "append"
}
The CSV includes keyword, location, business_name, detail_url, canonical_url, address, city, province, postal_code, category, telephone, website_url, website_text, rating, rating_count, current_status, editors_pick, and description when those fields are visible.
That output shape is practical for market research, CRM cleanup, directory QA, vendor discovery, and local lead review because the source profile URL travels with each row.
Decision guide
Which YellowPages Canada scraper should you choose?
Choose Apify for cloud orchestration
Pick a hosted actor when the job needs API retrieval, datasets, webhooks, parallel runs, queueing, and cloud logs.
Choose Octoparse for hosted no-code work
Pick a visual SaaS template when operators want a managed workspace, cloud tasks, and spreadsheet exports.
Choose managed scrapers for vendor delivery
Pick GetOdata, Spider, WebAutomation, or similar services when packaged extraction is more important than workflow ownership.
Choose scripts for full control
Pick code when developers need versioned parsers, tests, retries, custom storage, and full request control.
Choose UScraper for local CSV review
Pick YellowPages Canada Scraper for CSV Export when analysts need an inspectable local desktop app workflow and row-by-row CSV review.
Governance
Compliance and quality checks before scaling
Use restrained pacing, do not bypass CAPTCHA or access controls, and stop if the site returns unusual responses. Review YellowPages.ca policy pages before exported records feed outreach, enrichment, resale, or public reporting.
Define a QA rule before scaling. Start with ten detail URLs from one category and location. Compare exported fields against live pages, then expand after names, phones, websites, and source URLs match.
The best choice depends on scale and governance. Use hosted actors or scraper APIs for scheduled cloud runs and API delivery. Use UScraper when an analyst needs a local CSV and a workflow they can inspect.