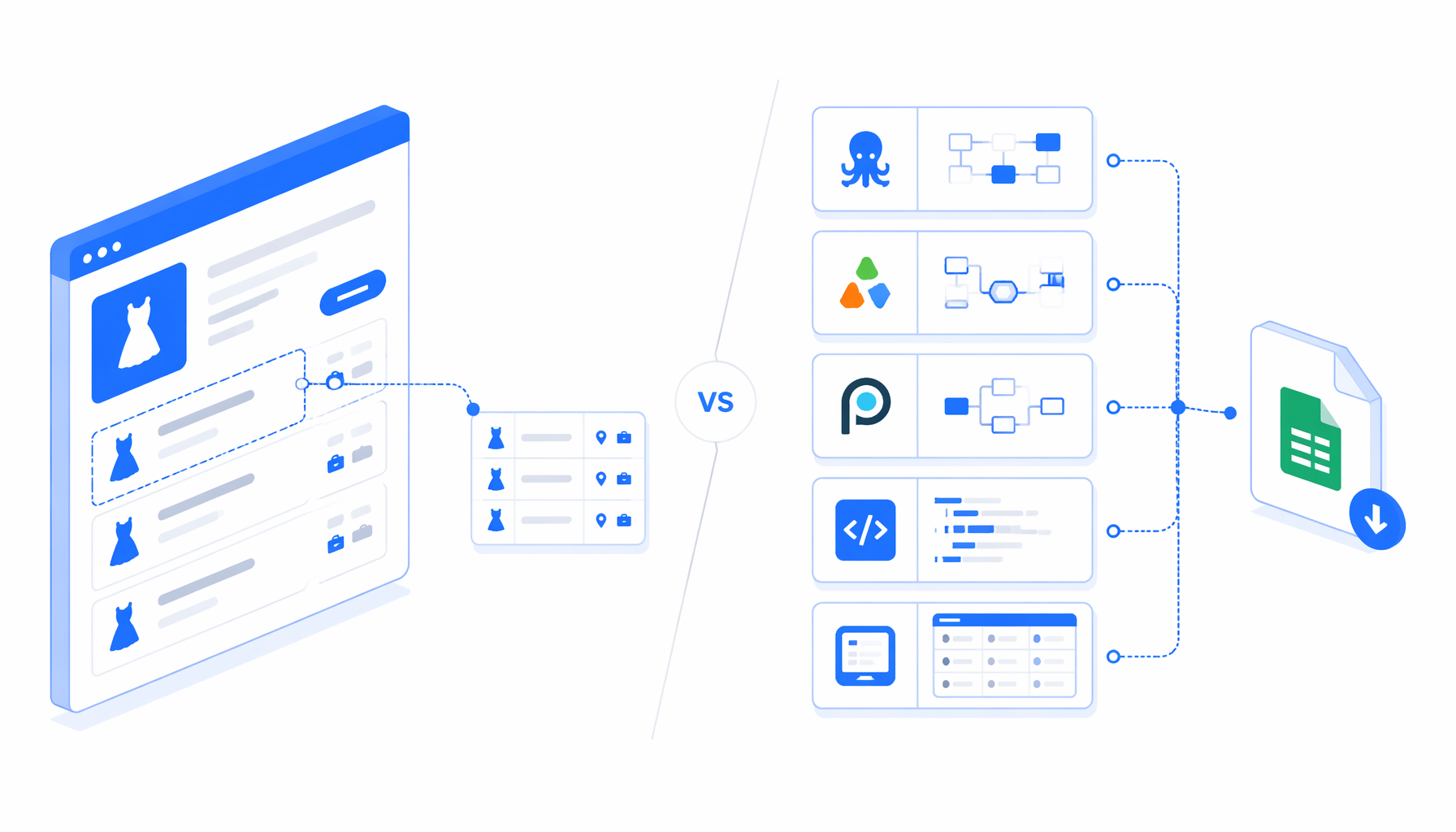
The best Woman Type job scraper is not automatically the tool with the largest marketplace or the most cloud features. For hiring research, the right choice depends on hosting, price model, code ownership, selector visibility, and whether the final deliverable is a clean CSV your team can audit. This comparison covers Octoparse, Apify marketplace actors, no-code SaaS scrapers, Scrapy scripts, and UScraper's Woman Type Job Details Scraper template.
Comparison frame
Woman Type scraper alternatives: what you are really comparing
Searches for how to scrape Woman Type usually come from recruiting operations, labor-market research, compensation benchmarking, or data QA teams. A useful workflow has to preserve Japanese text, handle expired postings, and keep the source URL attached to every row.
The practical choice is less about "can this tool scrape a page?" and more about the operating model:
- Runtime: local desktop app, hosted SaaS, marketplace cloud, or your own code.
- Maintenance: business user, vendor template, or engineering team.
- Pricing: subscription, credits, records, proxy usage, or developer time.
- Output: CSV, hosted dataset, JSON API, or custom database.
- Policy review: check the current Woman Type robots.txt and service terms.
The best Japanese job scraper is the one that fits your governance and output requirements, not the one with the longest feature list.
Side-by-side
Job scraping tools comparison for Woman Type data
| Option | Best fit | Hosting | Code needed | Output shape | Pricing shape | Main trade-off |
|---|---|---|---|---|---|---|
| Octoparse Woman Type template | No-code teams that prefer a hosted template | Vendor cloud | Low | CSV, Excel, or cloud task exports | SaaS plan, task, and cloud limits | Convenient template ecosystem, but rows and task history live in a hosted workflow |
| Apify marketplace actors | Teams already running scraping jobs through actors and APIs | Apify cloud | Low to medium | Dataset, JSON, CSV, API | Platform usage, actor pricing, runtime, and storage | Strong automation layer, but Woman Type coverage depends on available actors or custom build |
| ParseHub or Browse AI | Generic visual scraping and monitoring | Vendor cloud | Low | CSV, Sheets-style exports, integrations | SaaS tiers, pages, robots, or credits | Good for broad no-code extraction, less tailored to Woman Type detail fields |
| Scrapy or Python scripts | Engineering-owned job-board pipeline | Your infrastructure | High | Any database, file, queue, or API | Developer time plus hosting/proxy cost | Maximum control, highest maintenance burden |
| Spreadsheet/manual copy | One-off review of a few jobs | Browser only | None | Manual sheet | Staff time | No scraper risk, but slow and inconsistent |
| UScraper + Woman Type template | Reviewed detail URLs to local CSV | Local desktop app | Low | CSV with 10 job-detail columns | Free template; app licensing applies | Best for visible local workflow, not fleet-scale hosted crawling |
This is not a universal ranking. Octoparse fits teams already using no-code cloud tasks. Apify fits actor APIs, datasets, and scheduled jobs; its marketplace also includes adjacent Japanese job-board actors for MyNavi, Rikunabi, Doda, and general jobs. Scrapy fits when the crawler becomes product infrastructure.
Octoparse vs Apify
Octoparse vs Apify vs UScraper for Woman Type
Octoparse has the clearest direct alternative because it publishes a dedicated Woman Type job details scraper template. That helps teams that want a point-and-click cloud workflow, template discovery, and integrations such as Zapier-connected automations. The trade-off is SaaS custody, so review retention, limits, billing rules, and access.
Apify is different. It is stronger as a developer-friendly marketplace and automation layer than as a direct Woman Type template comparison. If you need API calls, datasets, run logs, webhooks, and scheduled actors, Apify can fit. If you need approved detail pages exported to a spreadsheet, it may be more platform than the job requires.
UScraper is narrower. The Woman Type Job Details Scraper template opens a known URL list, waits for the detail header, runs Structured Export, sleeps, and loops. The export is the goal.
UScraper Woman Type Job Details Scraper
Snapshot- Tagline
- Local desktop workflow for reviewed Woman Type detail URLs
- Pricing
- Template is free to import; UScraper app licensing applies
- Hosting
- Runs locally in the desktop app
- Best for
- CSV-first hiring research, visible selectors, and local file custody
- Less ideal for
- Massive hosted crawling, managed proxies, and API-first data products
{
"fileName": "woman-type-job-details-scraper.csv",
"fileMode": "append",
"rowSelector": "#contents",
"columns": [
"job_category",
"...",
"page_url"
]
}
Where each wins
When each Woman Type scraper option is the better fit
UScraper wins when the team wants source URLs and exported rows to remain in a local desktop workflow, with the output written to a chosen folder.
Apify or a SaaS scraper wins when recurring cloud runs, API access, remote datasets, webhooks, and shared task management are required.
It depends. Octoparse, Browse AI, ParseHub, and UScraper can all reduce code. The deciding factor is whether you prefer hosted operation or local workflow control.
Scrapy or custom scripts win when engineers need versioned code, tests, queues, storage models, monitoring, and custom retry logic.
Choose UScraper when a recruiter, analyst, or operations person has a reviewed list of woman-type.jp/job-offer/... URLs and wants a repeatable CSV. Choose hosted no-code when scheduling matters more than local custody. Choose Apify for a broader automation stack. Choose Scrapy for a maintained internal dataset.
Prefer a URL-list workflow you can explain: which pages opened, which fields exported, where the file saved, and how often the run happened.
Decision guide
Which Woman Type scraper should you pick?
Pick Octoparse for a direct hosted Woman Type template. Pick Apify if your workflow depends on actors, datasets, APIs, and scheduled runs across job boards. Pick ParseHub or Browse AI for general no-code scraping or monitoring. Pick Scrapy if developers will maintain production crawler code.
Pick UScraper if the assignment is simpler: import the template, replace sample URLs with approved Woman Type detail pages, confirm the export path, run the loop, and review the CSV. Start from the Woman Type Job Details Scraper template, then use the how-to guide for setup or browse the template library for related job-board scrapers.
FAQ
What is the best Woman Type scraper alternative?
It depends on hosting, scale, code ownership, and output. Use UScraper for a local desktop workflow that exports approved detail URLs to CSV. Use Octoparse or Browse AI for hosted scraping, Apify for actor automation, and Scrapy when engineers own the crawler.
How does UScraper compare with Octoparse for Woman Type?
Octoparse publishes a Woman Type job details scraper template in its hosted ecosystem. UScraper runs locally, keeps the workflow visible, and writes woman-type-job-details-scraper.csv to a folder you control.
Should I use Apify for Woman Type job data?
Use Apify when you need hosted actors, API-driven runs, datasets, scheduling, or adjacent Japanese job-board actors. For Woman Type, confirm whether a maintained actor exists and whether pricing fits your run volume.
Can I scrape Woman Type jobs with Scrapy?
Yes, if the use case is permitted and the team can maintain selectors, pacing, retries, storage, and tests. Scrapy is often better for production pipelines, but heavier than a no-code template for analyst-led CSV work.
What does the UScraper Woman Type template export?
The template exports job_category, page_number, job_title, company_name, employment_type, working_time, location, salary, job_description, and page_url into woman-type-job-details-scraper.csv. For more articles and adjacent workflows, return to the UScraper blog or the templates collection.