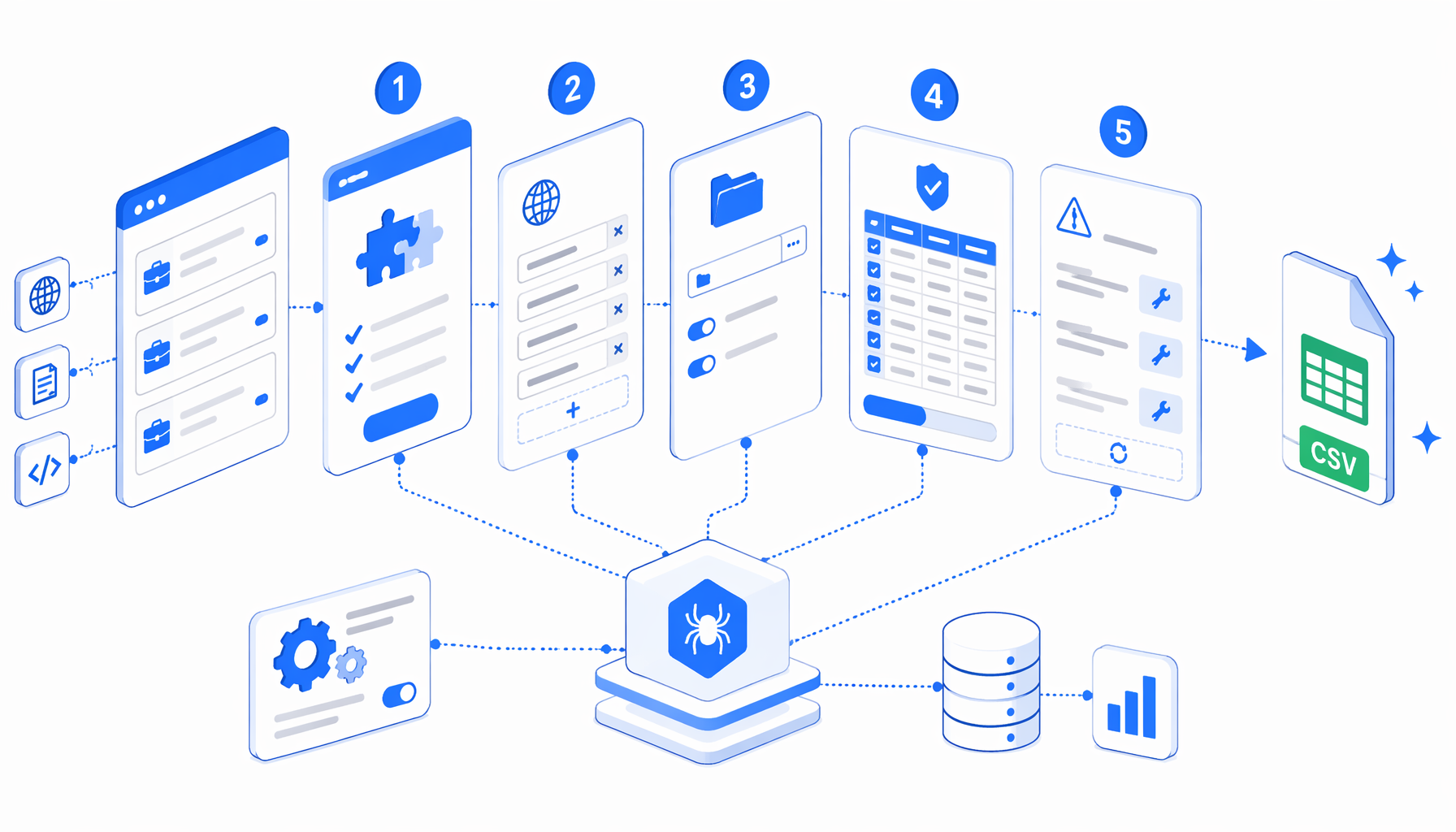
This Woman Type job scraper tutorial shows how to turn reviewed Woman Type job-offer pages into a clean CSV with UScraper. You will import the workflow, replace or extend the URL list, set the export path, validate the first rows, and handle the common issues that appear when scraping Japanese job postings.
Start from the Woman Type Job Details Scraper template instead of rebuilding the blocks by hand. The template is the maintained download path, while this guide explains the operating flow behind the JSON export.
Before you run
Prerequisites for scraping Woman Type jobs
You need the UScraper local desktop app, the downloaded Woman Type template JSON, a short list of active woman-type.jp/job-offer/... URLs, and a destination folder for the CSV. Keep your first run small: one to seven detail pages is enough to test page loading, selectors, export mode, and Japanese text rendering in your spreadsheet tool.
You should also review the live Woman Type site, the current robots.txt, and the official service terms before collecting data. This tutorial is for public job-detail research. It does not cover member pages, application forms, applicant records, login-only data, or bypassing consent and verification screens.
Treat the CSV as a focused research extract. Keep the source URL, collection date, and business purpose with every dataset you store.
Workflow shape
How the Woman Type job scraper works
The JSON export is simple by design. It sets the browser window size, opens each supplied detail URL, waits for the page load, waits until .inner.detail-top .company-name is visible, exports the configured fields from #contents, pauses for one second, and then uses Loop Continue to advance the multi-URL list.
| Block | What it does | Why it matters |
|---|---|---|
| Set Window Size | Opens the page in a stable desktop viewport | Reduces layout differences between runs |
| Navigate | Loops through the supplied Woman Type detail URLs | Keeps scope explicit and auditable |
| Wait for Page Load | Gives the browser up to 30 seconds to load | Avoids early empty exports |
| Wait for Element | Confirms the company name is visible | Proves the detail page reached the expected state |
| Structured Export | Writes custom columns to CSV | Normalizes job data for spreadsheet review |
| Sleep | Adds a one-second pause | Keeps the loop easier on the source site |
| Loop Continue | Moves to the next URL | Appends every approved page into one file |
The workflow does not try to discover every Woman Type listing. That is intentional. A URL-list scraper is easier to review for compliance, easier to reproduce, and easier to debug when a posting expires or the page layout changes.
Runbook
How to scrape Woman Type job details to CSV
Import the template
Open the Woman Type template page, download the JSON workflow, and import it into UScraper. Keep an untouched copy so you can compare later selector edits.
Review the URL list
Open the Navigate block. Replace stale sample URLs with current woman-type.jp/job-offer/... detail pages that your team has approved for collection.
Set the export folder
In Structured Export, confirm the file name woman-type-job-details-scraper.csv, include headers, append mode, and a project-specific save location.
Run a small batch
Start with one to seven pages. Watch for consent, unavailable listings, redirects, or pages that do not show the expected company-name element.
Validate before scaling
Open the CSV, compare several rows against the source pages, check Japanese text encoding, and dedupe by page_url if you rerun the same URLs.
If you are comparing tools, Octoparse publishes a Woman Type job details scraper template for its ecosystem. UScraper is the better fit when the analyst wants local file custody, visible block logic, and a CSV path controlled from the desktop app. A Python or Scrapy crawler can make sense when engineering owns long-term maintenance, tests, proxy rules, and deployment.
Output
What the Woman Type CSV includes
There is no bundled CSV sample, so treat the JSON workflow as the authoritative export shape and verify the first file yourself. The template exports these columns:
woman-type-job-details-scraper.csvColumn
job_category
Job family parsed from breadcrumbs or visible tags.
Column
page_number
The page query value when present, otherwise 1.
Column
job_title
Main job title from the detail heading.
Column
company_name
Employer name shown near the listing header.
Column
employment_type
Employment type text or icon alt text.
Column
working_time
Schedule or working-hours block.
Column
location
Workplace or assignment-location text.
Column
salary
Salary or compensation text as displayed.
Column
job_description
Role description block from the detail page.
Column
page_url
Full source URL for audit and deduplication.
The important JSON settings are the row selector, file mode, and JavaScript-backed columns:
{
"rowSelector": "#contents",
"fileName": "woman-type-job-details-scraper.csv",
"includeHeaders": true,
"fileMode": "append",
"columns": [
"job_category",
"page_number",
"job_title",
"company_name",
"employment_type",
"working_time",
"location",
"salary",
"job_description",
"page_url"
]
}
Validation
Common issues when scraping Woman Type job postings
Job-board pages change more often than static directory pages. Validate field quality before using the CSV for recruiting research, salary checks, market mapping, or downstream enrichment.
| Symptom | Likely cause | Fix |
|---|---|---|
| Empty CSV | The expected detail header did not appear | Open the URL manually, confirm it is still active, then increase waits if needed |
| Blank salary or hours | The posting omitted the field or used different wording | Leave blanks honest; do not invent normalized values |
| Repeated rows | Append mode ran against the same URLs twice | Dedupe by page_url and archive each batch by date |
| Wrong category | Breadcrumbs or tags changed on the page | Update the job_category JavaScript selector |
| Japanese text looks broken | Spreadsheet opened the file with the wrong encoding | Import as UTF-8 instead of double-clicking the CSV |
For applicant operations, separate job-posting research from candidate intake. Tools such as HITO-Link document automated import workflows for Woman Type applicants, but this UScraper tutorial is only about public job-offer details, not applications or personal candidate records.
Public visibility is not the same as permission. Review Woman Type terms, robots guidance, copyright restrictions, privacy obligations, and employment-data rules before automating collection. Keep batches modest, avoid login-only or applicant data, and do not bypass access controls.
Next step
Download the Woman Type Job Details Scraper template, run one approved detail URL, and inspect the CSV before expanding the list. For adjacent workflows, browse the UScraper templates collection or the blog for more job-board scraping tutorials.