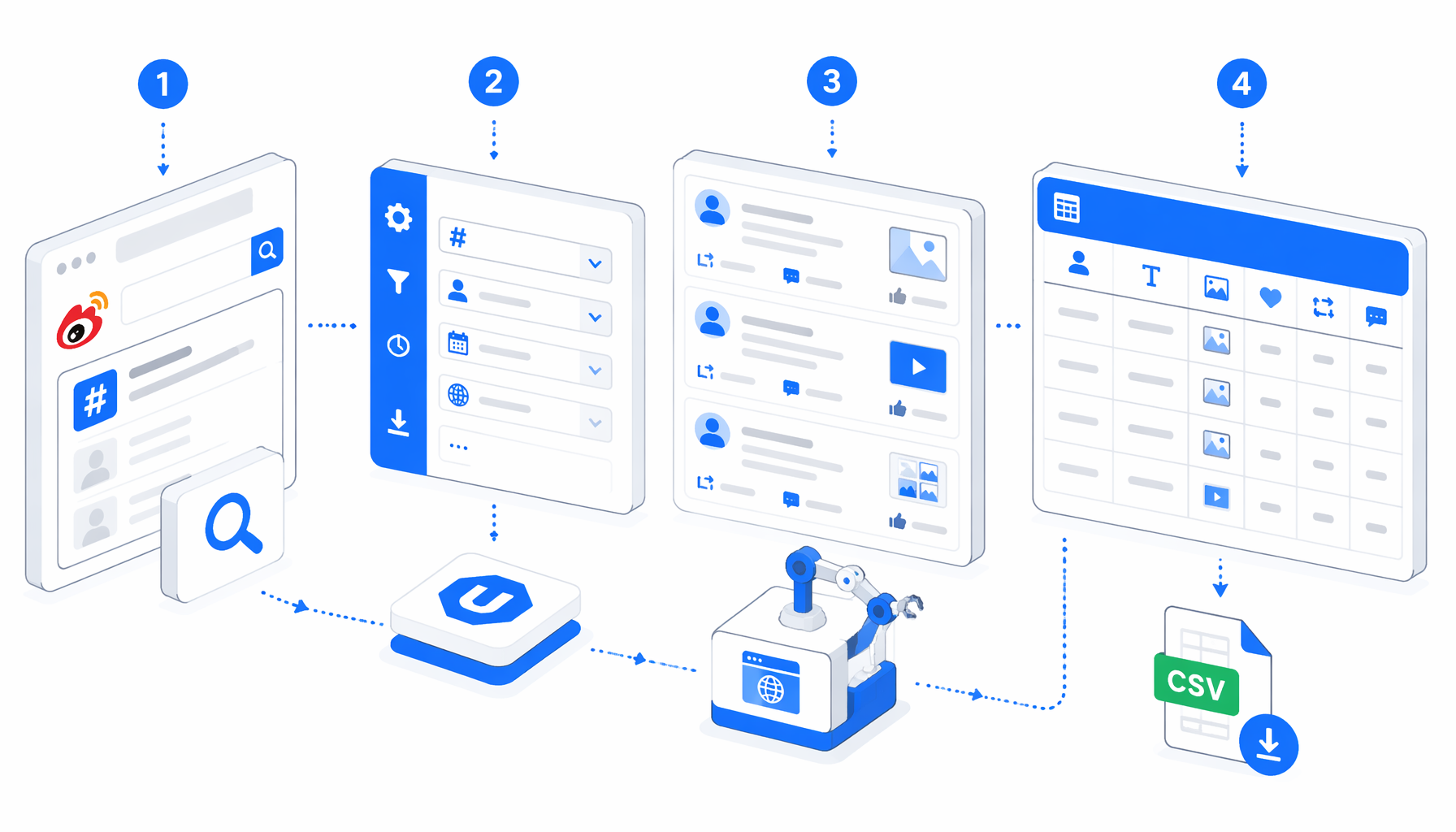
This tutorial shows how to scrape Weibo posts by keyword into CSV with the Weibo Post Info Scraper for Keyword Posts template for UScraper. You will prepare mobile Weibo search URLs, import the workflow, set the export path, run one keyword, and validate the rows before adding more searches.
Before you start
Prerequisites and Weibo access checks
You need UScraper installed as a local desktop app, one or more Weibo keyword search URLs, and a folder for CSV exports. Start with one keyword URL that opens manually in the same browser session. If the page asks for login, verification, or CAPTCHA, resolve that in the browser first.
This guide covers keyword-search result pages you can already view. It does not cover private messages, private profiles, credential capture, CAPTCHA bypassing, or bulk collection beyond your allowed use. Review Weibo's current terms and local privacy rules before exporting post content for reporting, resale, enrichment, or AI training.
Treat the browser as the source of truth. If the current session cannot load post cards for the keyword search, the CSV export will not have reliable rows to collect.
Workflow anatomy
What the Weibo keyword scraper template does
The companion JSON is the authoritative workflow definition. Its main path is Navigate -> Wait for Page Load -> Wait for Element -> Inject JavaScript -> Sleep -> Structured Export -> Loop Continue -> End. Navigate holds the keyword URL list. Wait for Element checks for .card9.weibo-member cards. The injected JavaScript scrolls the mobile search page until content height stabilizes, then Structured Export reads the loaded cards into CSV.
The workflow is best-effort. It does not call an official Weibo API, log in for you, or guarantee every post for a keyword. It captures browser-visible result cards, which is useful for supervised research, social listening samples, campaign QA, and trend monitoring.
| Export area | CSV fields | Why it matters |
|---|---|---|
| Search traceability | keyword, url, current_time | Shows which keyword URL produced the row and when it was collected. |
| Post identity | username, post_time, weibo_url | Keeps each exported row tied to a visible post and author label. |
| Post content | content, image, video_url | Preserves the visible text plus first detected media or video link. |
| Engagement | forward_count, review_count, like_count | Gives analysts quick filters for reach, discussion, and momentum. |
Runbook
How to scrape Weibo posts by keyword to CSV
Import the template
Open Weibo Post Info Scraper for Keyword Posts, download the JSON, and import it into UScraper.
Prepare keyword URLs
Use m.weibo.cn/search URLs with an encoded q parameter. Keep one URL per keyword so the exported keyword column stays traceable.
Replace Navigate URLs
Paste your approved search URLs into navigate.urls[]. Preserve the loop connection so every keyword appends to the same CSV.
Confirm the export path
In Structured Export, check weibo-keyword-post-info-scraper.csv, headers, append mode, and a project-specific save folder.
Run one keyword
Run a single search, wait for the scroll loader to finish, then open the CSV and compare rows against the browser.
Scale carefully
Add the remaining keyword URLs only after the first export validates. Keep batches modest and save the input URL list beside the CSV.
After the first run, sort by keyword, weibo_url, and current_time. A single keyword can create many rows, while a quiet keyword may produce only a few visible cards.
Validation
Validate Weibo post rows before analysis
Validation matters because keyword search pages are dynamic. Keep the browser tab open beside the CSV and check several rows manually before using the export for reporting.
| Symptom | Likely cause | Fix |
|---|---|---|
| No rows exported | Weibo did not render .card9.weibo-member cards | Open the search manually, resolve login or verification, then rerun one keyword. |
Blank keyword | The search URL did not include a readable q parameter | Rebuild the mobile search URL and keep the keyword encoded in the URL. |
| Missing media links | The card has no media, media lazy-loaded late, or markup changed | Scroll manually, increase waits, then inspect the current card structure. |
| Counts look wrong | Weibo abbreviated, localized, or changed the control bar text | Compare against the visible card and update the selector if needed. |
| Duplicate rows | Append mode reused an old CSV or the same URL appeared twice | Clear the CSV or dedupe by keyword, weibo_url, username, and content. |
Options
UScraper vs Weibo APIs, Python scripts, and hosted tools
The right Weibo collection method depends on permission, volume, engineering capacity, and where the data may travel.
| Option | Best fit | Trade-off |
|---|---|---|
| UScraper template | No-code keyword research, local CSV exports, visible browser QA | Best for supervised batches, not unattended high-volume crawling. |
| Official Weibo API access | Approved applications with documented endpoint coverage | Requires credentials, endpoint fit, quota handling, and developer work. |
| Hosted scrapers or APIs such as Octoparse, Apify, or Piloterr | Managed infrastructure, scheduling, datasets, and API-style delivery | Search inputs and outputs usually pass through a third party. Pricing and limits vary by provider. |
| Open-source or Python projects such as dataabc/weibo-search or custom scripts | Teams that need code-level control over auth, parsing, retries, and pipelines | Highest maintenance burden when Weibo changes access flows or markup. |
If you searched for "scrape Weibo with Python", start by deciding whether you actually need custom code. For a research CSV from a known set of keyword searches, the UScraper template is faster to inspect and easier to hand to non-developers. For production systems, official API access or a maintained engineering pipeline may be more durable.
Common issues
Common Weibo keyword scraping issues
Most failures are access issues, URL issues, or over-scaling. Open the exact mobile search URL manually first, keep the search term in the q parameter, and use one encoded URL per keyword. If Weibo slows, gates, or varies results, reduce batch size and pause instead of forcing more runs.
FAQ
Weibo keyword scraper FAQ
Weibo posts may be visible in a browser, but automated collection can still be limited by Weibo terms, login rules, copyright, privacy law, and local regulations. Use modest research batches, avoid bypassing access controls, and get legal review before republishing, selling, enriching, or training models on exported data.
Next step
Download the Weibo post info scraper template
Download the JSON from Weibo Post Info Scraper for Keyword Posts and keep this guide open for validation. For neighboring social workflows, browse all UScraper templates, or read more tutorials on the UScraper blog.