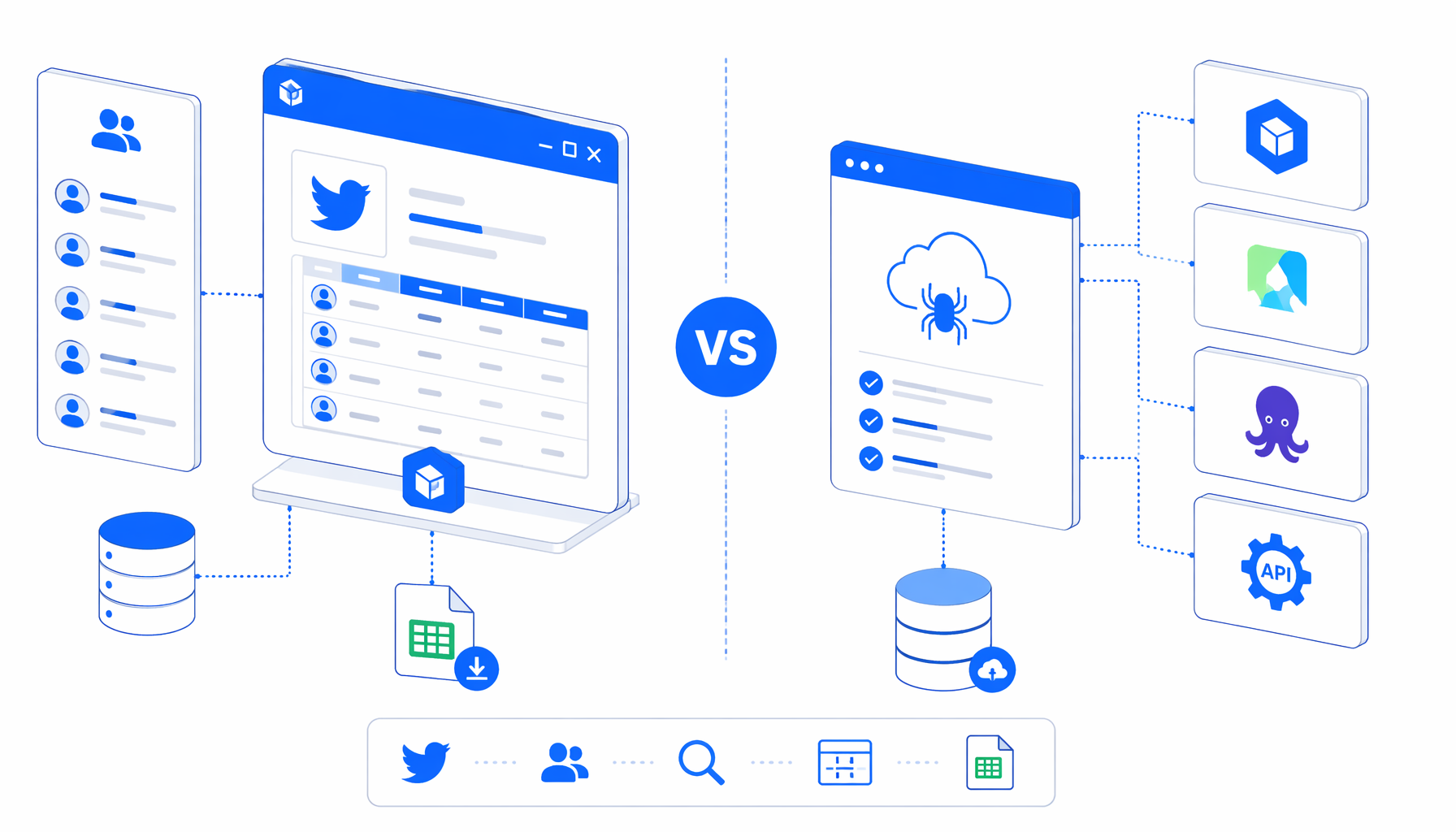
The best Twitter follower scraper depends on the job: a local CSV export, a hosted dataset, a coded pipeline, or a governed X API integration. This comparison shows where UScraper's Twitter Follower and Following Scraper fits beside Octoparse, Apify, scripts, scraper APIs, and the official X API.
Decision frame
What Twitter follower scraper alternatives differ on
Searches like twitter following export tool, how to scrape twitter followers, octoparse twitter scraper alternative, and x api followers scraping alternative all point at the same need: turn X relationship pages into something a team can analyze.
The useful comparison is where the browser runs, whether the output is CSV or an API dataset, how pricing is metered, who handles login state, and how much maintenance your team can own.
A Twitter follower scraper decision is mostly an operations decision: local review, no-code cloud scraping, hosted actor infrastructure, engineering-owned code, or official API access.
For production systems, keep the official X API pages for follows endpoints, user lookup, and rate limits in the evaluation. For spreadsheet-first work, start with output shape.
Side by side
Twitter follower scraper alternatives compared
| Option | Best fit | Hosting | Code | Output | Pricing model | Main trade-off |
|---|---|---|---|---|---|---|
| UScraper + Twitter Follower and Following Scraper | Supervised follower and following exports | Local desktop app | Low | CSV with owner fields, list type, followed handle, bio, URL, avatar, verified flag | Free template; app licensing applies | Local and visual, not a hosted scheduler |
| Octoparse follower template | No-code Octoparse users | Vendor cloud/platform | Low | Cloud table, CSV, Excel, JSON-style exports | SaaS plan and task limits | Fast setup, less local custody |
| Octoparse Twitter/X scraper | Broader X scraping tasks | Vendor cloud/platform | Low | Structured template export | SaaS plan and task limits | Useful if already standardized on Octoparse |
| Apify followers actors and following actors | Hosted actors, datasets, APIs | Vendor cloud | Low to medium | Dataset, JSON, CSV, Excel, API | Usage, compute, proxy, or actor pricing | Strong automation, vendor-hosted execution |
| Official X API | Governed app integrations | X platform APIs | Medium | JSON API responses | Developer plan, endpoint access, rate limits | Best for products, slower for quick CSV |
| twscrape, Scweet, and scripts | Engineering-owned pipelines | Your environment | Medium to high | Whatever you build | Developer time plus infrastructure | Flexible, but maintenance is yours |
| Managed scraper APIs | Large data programs | Vendor infrastructure | Low to medium | API or dataset delivery | Request, record, proxy, or plan pricing | Usually too much for a small analyst export |
UScraper fit
When UScraper is the best Twitter following export tool
UScraper is strongest when the export is review-heavy and spreadsheet-bound. The template opens X list pages such as /verified_followers and /following, waits for dynamic content, scrolls visible user cells, writes temporary rows, and exports twitter-follower-list-scraper.csv.
The CSV keeps owner profile fields beside every captured relationship row, so merged exports still show which profile and list produced each followed account.
UScraper wins when an analyst wants a visible run and local CSV output.
UScraper wins when navigation, waits, collection, export, and loop blocks should be inspectable.
Cloud tools win when jobs need schedules, logs, datasets, webhooks, and API delivery.
The X API wins when a product needs formal platform access review.
Competitor fit
Apify Twitter followers scraper vs Octoparse vs scripts
Use Apify when the job looks like infrastructure. Marketplace actors, datasets, logs, APIs, and cloud runs make sense when a remote process must run repeatedly.
Use Octoparse when the team already prefers no-code cloud scraping and wants a guided template path. Octoparse's own Twitter follower template notes that X may only display a limited number of followers or following rows on the page, which is the same constraint any browser-based export must respect.
Use scripts when engineering control is the priority. Libraries such as twscrape and Scweet shift the work to accounts, retries, throttling, storage, tests, secrets, and policy review.
Use the official X API when the integration needs a sanctioned path. It is not the fastest twitter followers to CSV route, but it is the better starting point for long-running products.
Pick by job
Best Twitter follower scraper by use case
| Use case | Pick first | Why |
|---|---|---|
| One-off follower sample export | UScraper | Local visual run, quick CSV, manual validation |
| Creator or competitor shortlist | UScraper | Keeps owner profile and list type attached to every followed account |
| Daily follower monitoring | Apify or another hosted runner | Scheduling, remote execution, logs, and datasets |
| Existing Octoparse workflow | Octoparse | Familiar no-code cloud designer and template ecosystem |
| Product integration | Official X API | Governed access path, API behavior, and rate-limit planning |
| Custom research pipeline | Scripts | Maximum control if engineers can maintain it |
If the deliverable is a spreadsheet for an analyst, UScraper is often the clean lane. If the deliverable is an always-on data product, use a hosted tool, managed provider, scripts, or the API.
Output
What the UScraper Twitter follower scraper exports
The template is built for a transparent CSV rather than a black-box dataset. The export JSON defines the actual flow:
{
"project": {
"name": "Twitter Follower Following Scraper",
"description": "Best-effort X/Twitter follower and following scraper"
},
"navigate": [
"https://x.com/elonmusk/verified_followers",
"https://x.com/elonmusk/following"
],
"export": {
"rowSelector": "#uscraper-x-follow-results .scraped-follow-row",
"fileName": "twitter-follower-list-scraper.csv",
"fileMode": "append"
}
}
| Field group | Columns |
|---|---|
| Owner profile | User_Name, User_ID_handle_, User_URL, User_Avatar_URL, User_Bio |
| Owner metrics | User_Type_verified_or_not_, User_Follower_count, User_Following_count, User_List_Type |
| Captured account | Follow_Name, Follow_ID, Follow_URL, Follow_Avatar_URL, Follow_Bio, Follow_Type_verified_or_not_ |
If X redirects to login or hides follower cells, the workflow writes a diagnostic fallback row instead of silently creating an empty file.
FAQ
Common questions about Twitter follower scraper alternatives
Use UScraper for supervised local CSV exports, Apify for hosted actors and datasets, Octoparse for no-code cloud tasks, scripts for engineering-owned pipelines, and the official X API for governed integrations.
Next step
Download the Twitter follower scraper template
If you want the local CSV route, open the Twitter Follower and Following Scraper template, import the workflow into UScraper, and run one approved profile list first. For setup details, read the step-by-step Twitter follower scraper tutorial, browse the template library, or scan the UScraper blog.