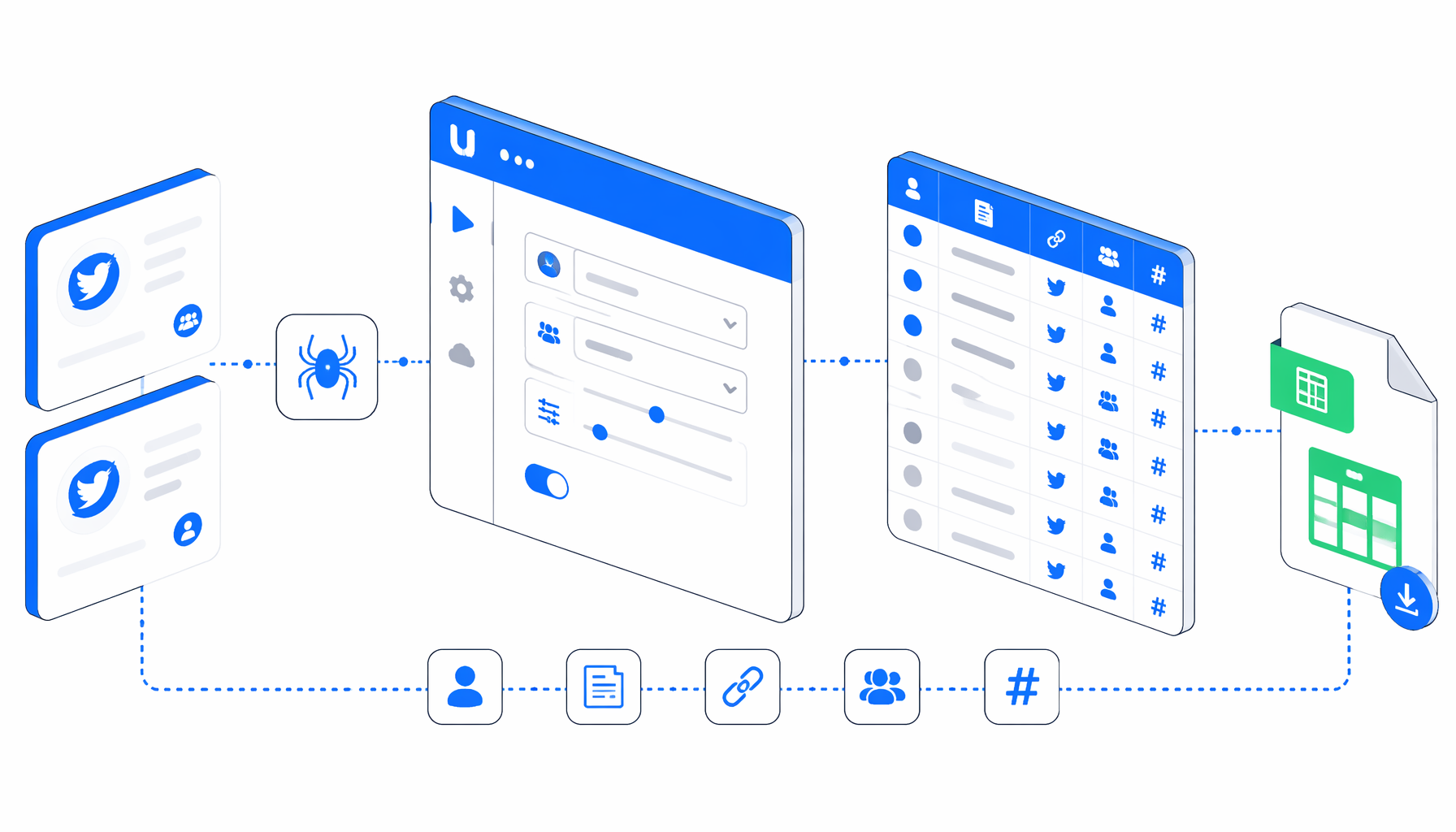
This tutorial shows how to scrape Twitter followers and following lists into CSV with the Twitter Follower and Following Scraper template for UScraper. You will prepare profile list URLs, run a validation pass, set the export path, and review the CSV before scaling.
Before you start
Prerequisites before you scrape Twitter followers
Use this workflow for bounded relationship research, not broad crawling. You need UScraper as a local desktop app, a browser session that can open the target list pages, approved profile handles, and a CSV folder.
The companion Twitter follower scraper template is the download path. This article explains the workflow, export fields, and validation steps when X only exposes a limited visible sample.
For engineering teams, the official route starts with X user lookup, follows endpoints, authentication, access level, and rate-limit review. Keep the official X API pages for user lookup, followers and following endpoints, and rate limits in your decision notes.
Choose the path
Twitter follower scraper vs X API vs code
Different teams mean different trade-offs. A marketer may need a spreadsheet from a few profile lists. A data engineer may need sanctioned API access and audit logs. A researcher may need a run that can be checked against the browser.
Use UScraper when you need a supervised CSV export from visible follower or following pages. The template is no-code, editable, and useful for small account sets where a human can validate the first run.
The practical rule: if the output becomes a recurring product feed, use an official or contract-backed path first. If it is a supervised research export from a short list of visible pages, a local desktop workflow can be faster to validate.
Workflow
How the Twitter follower and following scraper works
The export JSON is the authoritative workflow definition. The shape summary below explains the extraction intent without requiring you to read every block in the template file.
| Stage | What it does | What to check |
|---|---|---|
| Navigate | Loads configured URLs such as /verified_followers and /following | Replace sample URLs with approved profile list URLs |
| Wait and pause | Allows X to hydrate the page and render user cells | Empty output often means login, interstitial, or load friction |
| Inject JavaScript | Scrolls eight visible batches and creates temporary export rows | Increase waits only after one target validates cleanly |
| Structured Export | Reads #uscraper-x-follow-results .scraped-follow-row and writes CSV rows | Confirm filename, save folder, headers, and append mode |
| Loop Continue | Advances to the next configured list URL | Keep profile and list type attached to each row |
{
"project": {
"name": "Twitter Follower Following Scraper",
"description": "Best-effort X/Twitter follower and following scraper equivalent to the Octoparse template."
},
"blocks": [
{
"title": "Navigate",
"config": {
"urls": [
"https://x.com/elonmusk/verified_followers",
"https://x.com/elonmusk/following"
]
}
},
{
"title": "Inject JavaScript",
"config": {
"waitForCompletion": true,
"timeout": 10
}
},
{
"title": "Structured Export",
"config": {
"rowSelector": "#uscraper-x-follow-results .scraped-follow-row",
"fileName": "twitter-follower-list-scraper.csv",
"includeHeaders": true,
"fileMode": "append"
}
}
]
}
Runbook
Step-by-step: scrape Twitter followers to CSV
Import the template
Open the Twitter Follower and Following Scraper from the template library and import the JSON workflow into UScraper.
Prepare target list URLs
Use list URLs that already load in your browser, such as https://x.com/example/following or https://x.com/example/verified_followers. Start with one handle and one list type.
Confirm the browser session
Open the target list in the UScraper browser profile. If X asks for login, sign in only through the normal interface. Stop if the page shows verification, challenge, warning, or restricted states.
Set the export folder
In Structured Export, choose where twitter-follower-list-scraper.csv should be saved. Because append mode is enabled, keep test files separate from client or research batches.
Run one validation pass
Run one list URL. Open the CSV, compare several handles against the browser, and confirm that User_List_Type says verified_followers or following.
Scale slowly
Add the second list type, then add more profile URLs. Pause or split batches if pages load slowly, return fallback rows, or show fewer visible accounts than expected.
Output
CSV columns for Twitter followers and following lists
The workflow keeps owner profile fields beside every captured relationship row, so merged exports still show which account and source list produced each line.
| Field group | Columns |
|---|---|
| Owner profile | User_Name, User_ID_handle_, User_URL, User_Avatar_URL, User_Bio |
| Owner metrics | User_Type_verified_or_not_, User_Follower_count, User_Following_count, User_List_Type |
| Captured account | Follow_Name, Follow_ID, Follow_URL, Follow_Avatar_URL, Follow_Bio, Follow_Type_verified_or_not_ |
Use the first CSV as a QA artifact. Sort by User_List_Type, scan for empty Follow_ID values, remove fallback rows, and keep the raw file separate from cleaned spreadsheets.
Common issues and fixes
X/Twitter follower and following pages may be visible in a signed-in browser, but automated collection can still be limited by platform terms, privacy law, copyright, access controls, and local regulations. Use approved targets and get legal review before commercial reuse.
Next step
Download the Twitter follower scraper template
When you are ready to run the workflow, open the Twitter Follower and Following Scraper template, import it into UScraper, and validate one profile list before adding more accounts. For adjacent workflows, browse the UScraper templates library or the UScraper blog for other X/Twitter export tutorials.