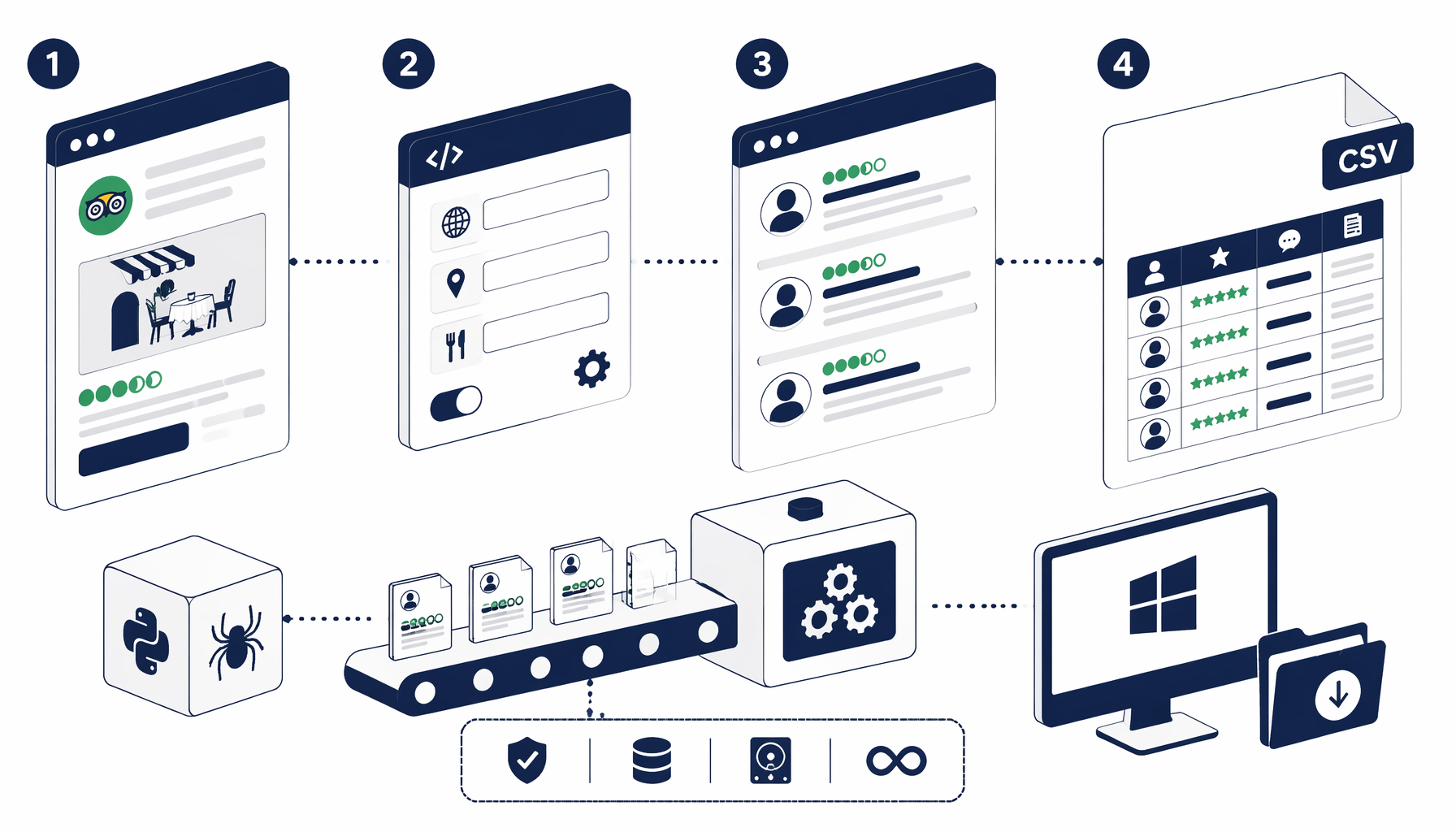
If you need TripAdvisor restaurant review rows—reviewer, bubble rating, title, body text, and supplementary lines—in one append-friendly CSV, this tutorial walks through prerequisites, the bundled automation graph, and how to validate exports when markup shifts. When you want the fastest path from article to runnable flow, import the JSON from Trip Advisor Restaurant Scrapper Export and align selectors to the live DOM you see today.
Before you start
Prerequisites and scope
You should run UScraper on Desktop, keep a restaurant reviews URL you can open manually in a conventional browser session, and reserve disk space for a growing spreadsheet. This guide is informational: it explains how analysts extract rows that render visibly on listing-style pages—not how to circumvent paywalls, scrape authenticated extranets, or redistribute TripAdvisor content against policy.
TripAdvisor publishes Terms of Use that discuss automated access and how their content may be used. The developers hub and Content API documentation describe partner-grade ingestion when HTML selectors are too brittle for your roadmap. Treat this post as a desktop workflow map sitting beside those official channels.
Compliance first: Technical steps below assume you have permission for the pages you automate and that your retention, attribution, and downstream use respect TripAdvisor’s current agreements plus applicable law—mirroring how mature data teams treat any consumer marketplace surface.
Workflow anatomy
What the bundled JSON defines
The companion export defines a Navigate → Sleep → Structured Export → Inject JavaScript (scroll) → Element Exists (Next) graph. When Next exists, a second Inject JavaScript node clicks through and the connection loops back to Sleep so each page gets a fresh wait before extraction; when Next disappears, control flows to End and your CSV stops growing intentionally.
The Structured Export block ships targeting one row per review via rowSelector plus columns such as Reviewer, Rating (often resolved through SVG title text), Title, Description, and Other Info. Default output uses trip-advisor-review.csv, includeHeaders enabled, and fileMode: append so multi-page sessions accumulate without rewriting headers between passes—ideal when analysts download incremental slices during a single supervised session.
| Column | Role in the UI | Validation tip |
|---|---|---|
| Reviewer | Display name on the card | Spot-check against hover cards or profile links when visible. |
| Rating | Bubble / star summary | Blank may mean lazy SVG not captured yet—rerun after longer Sleep. |
| Title | Short review headline | Compare with on-page heading selectors TripAdvisor exposes via data-test-target. |
| Description | Expandable review body | Ensure “read more” expansion fired if your DOM snapshot truncates text. |
| Other Info | Supplementary chips or metadata | Treat as optional context—normalize downstream rather than in-graph. |
Authoritative sample: Download
trip_advisor_restaurant_scrapper_export.jsonfrom the template detail page whenever you need exact block IDs, connector topology, and baseline selector strings—the MDX article explains intent; the JSON remains the machine-readable contract.
Pick your path
Three ways teams capture TripAdvisor listings and reviews
Best when researchers want no-code iteration, CSV custody on disk, and workflows they can diff like any other automation asset inside Git.
- Pros: Tune waits visually, append CSV rows safely, avoid per-record billing for small audits.
- Cons: You maintain selectors whenever TripAdvisor ships new review markup.
Begin at Trip Advisor Restaurant Scrapper Export, import the JSON, replace placeholder navigation with a real restaurant reviews URL, then refresh Structured Export mappings before enabling pagination.
Execution
Run the export end-to-end
Configure, prove one page, then loop
- Collect a compliant reviews URL — Paste the restaurant page whose reviews list you may automate into the Navigate block (replace any placeholder such as
https://example.com). - Import the JSON bundle — Download from Trip Advisor Restaurant Scrapper Export and load it so Sleep durations and Structured Export wiring appear instantly.
- Dry-run Structured Export — Confirm
rowSelectorwraps exactly one card per row and each column resolves non-null text on the first screenful. - Verify CSV append settings — Keep headers on the first write, leave append enabled for subsequent passes, and choose an output path your analysts can audit.
- Re-enable scroll + pagination — The sample injects scroll-to-bottom JavaScript, checks for
[aria-label="Next page"], clicks when present, or ends gracefully when pagination stops. - Spot-check five random rows — Open matching reviews in the browser to ensure titles, ratings, and bodies line up with what diners actually published.
Import the template
Grab trip_advisor_restaurant_scrapper_export.json from the template library entry so Navigate → Sleep → Structured Export edges stay intact.
Match locale-specific markup
TripAdvisor ships regional templates; revalidate selectors whenever you switch countries or languages.
Pause pagination for QA
Disconnect the loop temporarily, export a single page into trip-advisor-review.csv, and inspect delimiter safety before scaling up.
Tune Sleep honestly
Waiting a few extra seconds beats racing skeleton placeholders that yield empty Description cells.
Log each successful Next click
Track page indices externally if auditors ask how many screens fed the CSV—append timestamps or counters via sibling tooling if needed.
Quality gates
Validate, dedupe, and troubleshoot
Sort by Reviewer + Title before deduping—TripAdvisor sometimes surfaces refreshed copies after filtering tweaks. Rating cells that rely on SVG title attributes break silently when TripAdvisor swaps aria patterns; fall back to textual snippets only after confirming accessibility parity.
If Structured Export suddenly emits zero rows, assume rowSelector drift before blaming IP reputation: reopen DevTools, locate the wrapper that still surrounds one review card, paste the updated selector, and rerun.
Local desktop export vs hosted TripAdvisor marketplace actors
| Dimension | UScraper on Desktop | Typical cloud TripAdvisor actors |
|---|---|---|
| Data custody | Remains in folders you administer | Often processed inside vendor infrastructure |
| Cost model | One-time desktop licensing posture | Subscription or usage metering |
| Selector upkeep | Visible edits inside Structured Export | Still required beneath hosted abstractions |
| Best fit | Analysts proving comps locally | Teams buying managed extraction globally |
Neither column removes your obligation to scrape ethically, honor TripAdvisor policies, and escalate to partner APIs when contracts demand it.
FAQ
Frequently asked questions
Laws vary by jurisdiction and use case. Many teams limit automation to data they can see without bypassing authentication, pace requests gently, and avoid uses that conflict with TripAdvisor terms or intellectual-property rules. Read TripAdvisor’s current Terms of Use (including sections on automated access and content use), compare against your counsel’s guidance, and prefer the official developer program or Content API when you need redistribution rights at scale.
Related links and next steps
- Import the workflow JSON from Trip Advisor Restaurant Scrapper Export—shortest path from reading to running on Desktop.
- Browse the full template library for adjacent marketplace exports when TripAdvisor is only one stop in a wider audit.
- Read more tutorials on Blog and cross-link related clusters when you document downstream enrichment.
When trip-advisor-review.csv opens cleanly in Excel, validates under spot checks, and survives another TripAdvisor UI tweak because you refreshed selectors proactively, you retain a transparent, local pipeline anchored to the same zero-cost template you imported on day one.