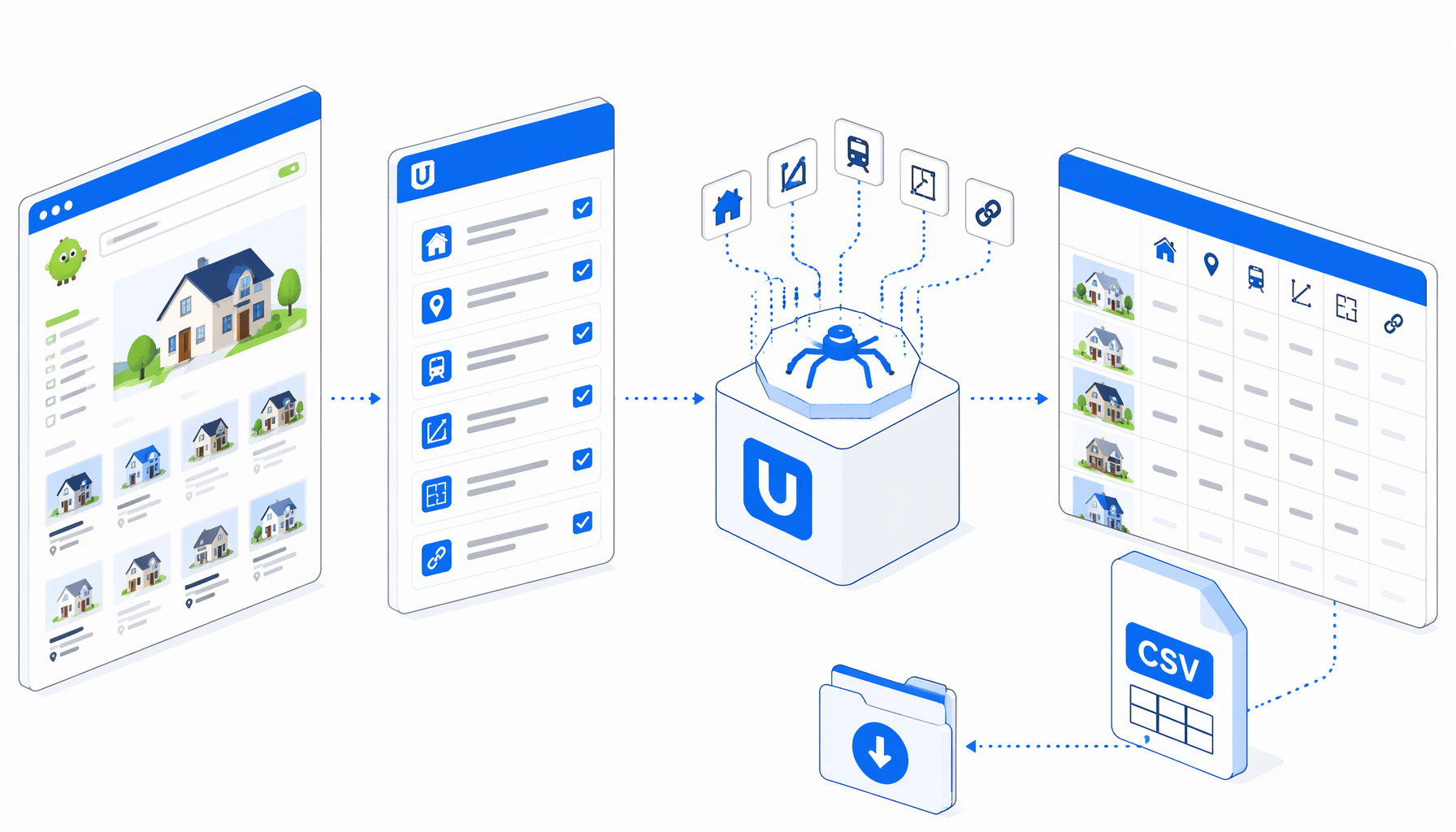
This tutorial shows how to scrape SUUMO detached-house listing pages into CSV with the SUUMO Detached House Listing Scraper template. You will prepare a result URL, import the workflow, set the export path, validate Japanese real estate fields, and handle pagination without writing a custom crawler.
Before you start
Prerequisites for scraping SUUMO listings
You need UScraper installed as a local desktop app, the free SUUMO Detached House Listing Scraper template, a local folder for the CSV, and a SUUMO detached-house result page you are allowed to process. The bundled workflow starts from a Sapporo used detached-house search, but you can replace that URL with another prefecture, city, ward, price band, or station-filtered result page.
Start with one result page. A small first run proves that SUUMO loads normally in the browser, the .property_unit cards are visible, the export folder is writable, and Japanese text survives the CSV workflow. Once the first page checks out, expand the same search rather than mixing multiple markets in one file.
Review SUUMO's current terms of use and robots directives before automation. Public visibility is not the same as permission to collect, store, enrich, republish, or resell real estate data.
Treat the first export as both a technical test and a policy check. Keep batches modest, stop when an access challenge appears, and keep source URLs beside the CSV for audit.
Workflow
How the SUUMO detached house scraper works
The JSON export is the authoritative workflow definition. In plain English, the listing scraper runs this sequence:
Navigate -> Wait for Page Load -> Wait for .property_unit
-> Structured Export -> Check for 次へ -> Click -> Wait -> repeat
The workflow extracts data from result-page cards instead of relying on detail pages. That choice matters because property detail URLs can expire, redirect, or disappear as inventory changes. Listing cards still give analysts the core fields needed for a first-pass market sheet: title, URL, price, location, train access, land area, layout, building area, build date, agent signal, phone number, and source page.
| Workflow stage | What it does | What to verify |
|---|---|---|
| Navigate | Opens the starting SUUMO used detached-house result page | Replace the bundled Sapporo URL with your approved search |
| Wait for Element | Waits for .property_unit listing cards | The browser shows real property cards before export |
| Structured Export | Appends visible card fields into CSV | Filename, headers, append mode, and save folder are correct |
| Element Exists | Checks for the Japanese 次へ pagination link | Final page ends cleanly when the link is absent |
| Click and loop | Moves to the next result page and repeats extraction | Rows continue from the next page without overwriting |
Runbook
How to scrape SUUMO detached house listings to CSV
Import the template
Open SUUMO Detached House Listing Scraper, download the JSON workflow, and import it into UScraper.
Prepare the result URL
Build your SUUMO detached-house search manually, then copy the result URL. Preserve filters such as city, ward, price, layout, age, station, and property type.
Replace Navigate
Paste your approved result URL into the Navigate block. For the first validation run, use a search with a manageable number of pages.
Confirm the export path
In Structured Export, check suumo-detached-house-listing-scraper.csv, headers, append mode, and the local save folder.
Run one page and compare
Watch the browser load the listing cards, then compare the first CSV rows against the visible property name, price, address, train access, land area, building area, agent, and phone number.
Scale after QA
Expand to the full result set only after pagination, row count, Japanese text, and blank-field behavior make sense.
Because the workflow follows the next-page link, the starting URL controls your scope. A broad citywide search may produce many pages; a narrow station or price-filtered search is easier to QA and rerun.
Export shape
SUUMO property data extraction fields
The bundle does not include a static CSV sample, so use the workflow definition and your first run together. The JSON defines the intended columns; the validation run proves those columns still match the current SUUMO layout.
suumo-detached-house-listing-scraper.csvColumn
property_name
Listing title from the visible card heading.
Column
property_link
Absolute SUUMO detail URL when the card exposes one.
Column
price
Published sale price text.
Column
location
Address or location field from 所在地.
Column
train_access
Rail line, station, walking time, or bus access.
Column
land_area
Land area from 土地面積.
Column
layout
Layout such as 3LDK, 4LDK, or 5LDK.
Column
building_area
Building area from 建物面積.
Column
built_date
Build date or age text from 築年月.
Column
agent_name
Agency or company detected near the phone number.
Column
customer_review_comment_count
Review or comment count when visible.
Column
phone_number
Published contact phone number when available.
Column
page_url
Original result page URL that produced the row.
For validation, sort by page_url, then compare a few rows against the browser. Active cards should usually contain a name, price, location, and at least one area field. Blank optional values are normal when SUUMO does not publish a field on a card; blank core values are a selector or page-load signal.
Tool choice
Best SUUMO scraper option: local workflow, cloud scraper, or API
Searches such as best SUUMO scraper, Octoparse SUUMO alternative, and SUUMO scraper API often describe different jobs. Choose the route based on control, scale, and rights.
Use UScraper when you want a local desktop workflow, visible browser QA, and CSV output from known SUUMO result pages.
The practical wedge for this tutorial is narrow on purpose: choose a SUUMO result page, export a reviewable CSV, validate it manually, and only then expand the run.
Troubleshooting
Common SUUMO scraping issues
| Symptom | Likely cause | Fix |
|---|---|---|
| Export file is empty | .property_unit did not appear or the page was not a matching result page | Open the URL manually and confirm listing cards exist |
| Pagination stops early | Final page reached, consent page appeared, or the 次へ selector changed | Inspect the browser state before changing the XPath |
| Repeated rows | Append-mode rerun or duplicate source pages | Dedupe by property_link and page_url, then clear test files |
| Price or area columns are blank | Label text changed or the card omits that field | Compare one card and update only the affected selector |
| Japanese text looks broken | Spreadsheet opened the CSV with the wrong encoding | Import the CSV as UTF-8 instead of double-clicking it |
FAQ
SUUMO scraper FAQ
SUUMO pages can be visible in a browser and still be governed by terms, robots directives, copyright, privacy rules, database rights, and real estate data rules. Review current policies, avoid bypassing access controls, keep runs modest, and get legal review before commercial reuse.
Next step
Download the SUUMO detached house scraper template
Use SUUMO Detached House Listing Scraper as the download path, then keep this tutorial open while you validate the first CSV. For adjacent workflows, browse all UScraper templates or return to the UScraper blog.