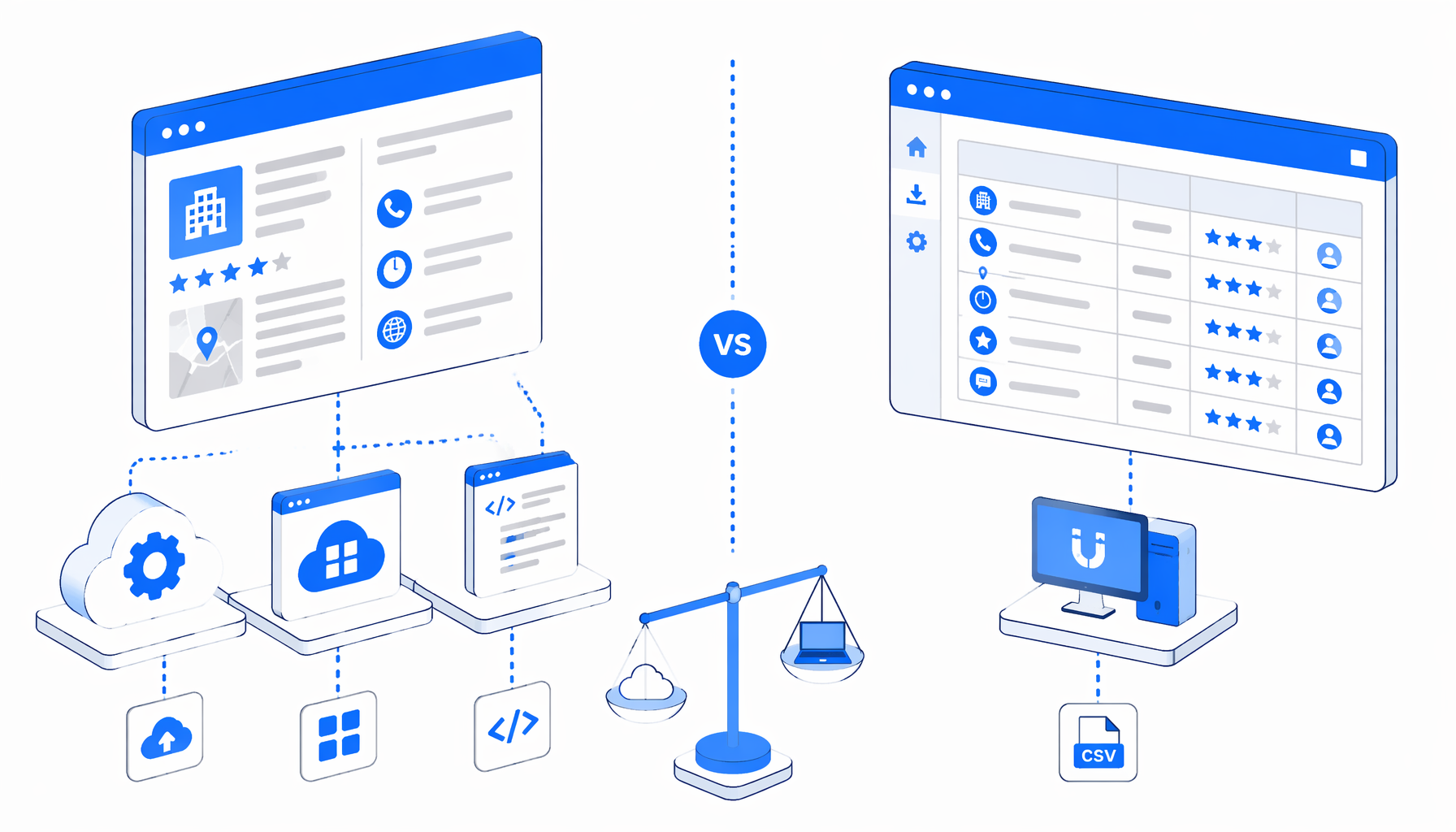
The best Superpages scraper depends on the job. Cloud actors, SaaS templates, AI scrapers, scripts, and the UScraper Superpages Scraper for Business Listings all trade off hosting, price, code, output, and data custody.
Comparison frame
What a Superpages scraper alternative must prove
Superpages is a local business directory, so searches like how to scrape Superpages, best Superpages scraper, and extract Superpages business data usually come from sales, local SEO, research, or data operations teams. The requirement is to collect names, phones, addresses, websites, ratings, categories, hours, and source URLs in a format someone can audit.
That is why a fair comparison should ask:
- Does the tool run locally, in a vendor cloud, or inside your own code?
- Does it export CSV, Excel, JSON, API responses, or hosted datasets?
- Can non-developers inspect the flow before running it?
- Is pricing based on a license, subscription, records, credits, or service contract?
- What compliance review is needed before collecting or using the data?
A Superpages scraper is also a data-governance choice. The export path, run history, source URL, and row QA process matter as much as the first successful scrape.
Review the official Superpages Terms of Use and legal notice before scaling. Public visibility does not automatically grant permission for commercial collection, resale, outreach, or republication.
Side by side
Superpages scraper alternatives compared
| Alternative | Best fit | Output model | Main trade-off |
|---|---|---|---|
| UScraper Superpages template | Analysts who want visible Superpages to CSV workflow logic | CSV from Structured Export | Best for supervised local runs, not cloud backend scale |
| Apify Superpages actor | Developers who want actors, APIs, datasets, and scheduled cloud runs | Dataset exports, API, CSV/JSON | Strong infrastructure, but hosted execution and custody |
| Octoparse Superpages template | No-code teams that prefer a SaaS template marketplace | CSV, Excel, JSON | Convenient templates, less local workflow custody |
| Web Scraper marketplace sitemap | Teams already using Web Scraper Cloud sitemaps | CSV, Excel, JSON | Clear sitemap model, still hosted cloud execution |
| Thunderbit or Bright Data | AI-assisted extraction or managed enterprise scraping | Spreadsheet exports, APIs, datasets | Useful at the right scale, heavier than a one-off CSV task |
| Python scripts or open-source scrapers | Engineers who own parser logic, queues, retries, and deployment | Custom CSV, JSON, database, or pipeline | Maximum control, maximum maintenance |
For most teams, the split is simple. Cloud tools win when the job must run unattended, at volume, or through an API. UScraper wins for a controlled export: one keyword and location set, a visible browser flow, a known file path, and a CSV a person will inspect.
Where UScraper fits
When UScraper is the better Superpages scraper
The Superpages Scraper for Business Listings is built for a spreadsheet-first workflow. It opens a Superpages search URL, waits for result cards, exports visible fields, checks for an enabled Next link, and appends additional pages into superpages-listing-scraper.csv.
That matters when a lead researcher, agency analyst, founder, or data ops person needs to see what the scraper is doing. The workflow is a JSON graph with blocks for navigation, waits, card detection, structured export, pagination, sleeps, and end control.
{
"project": {
"name": "Superpages Details Page Scraper Cloud"
},
"workflow": [
"Navigate to keyword/location search",
"Wait for Superpages result cards",
"Append Structured Export rows to CSV",
"Click enabled Next until pagination ends"
],
"output": "superpages-listing-scraper.csv"
}
| Export area | Example columns | Why it matters |
|---|---|---|
| Search context | keyword, location, detail_url | Keeps every row tied to the source query and profile URL. |
| Business identity | business_name, primary_category, categories | Supports dedupe, segmentation, and category QA. |
| Contact fields | telephone, website, email, fax, tollfree | Helps qualify records before enrichment or outreach planning. |
| Reputation and status | rating, review_count, opening_hours, description | Gives analysts enough context to score and filter leads. |
| Local detail | address, neighbourhoods, price_range | Adds market context for territory scans. |
Where cloud wins
When Apify, Octoparse, APIs, or scripts make more sense
Cloud platforms make sense when the run is no longer a supervised CSV task. Apify fits actor APIs, remote datasets, schedules, monitoring, and integrations. Octoparse fits teams already working inside its visual task system. Web Scraper Cloud fits sitemap-based extraction. Bright Data and similar providers fit buyers who want infrastructure, rendering, retries, and support wrapped around the scraper.
Scripts make sense for ownership. If engineers need custom proxy policy, queues, schema versioning, enrichment, storage, and retries, a Python or Playwright scraper can be worth it. It is rarely the fastest choice for a non-technical team that just needs Superpages leads in CSV.
UScraper wins when workflow, selectors, and export should stay in a local desktop app process.
Hosted tools win for recurring jobs, API access, datasets, throughput, and monitoring.
Depends. Many tools reduce code. The real difference is hosting model and workflow inspectability.
Scripts win when developers need to own selectors, queues, retries, parsers, and storage.
Decision guide
Which Superpages scraping tool should you pick?
Use UScraper if your goal is a controlled Superpages to CSV export, not a production data platform. Start with the Superpages scraper template, edit the keyword and location, run one page, inspect the CSV, then let pagination continue.
Use Octoparse if your team wants a SaaS template environment and is comfortable with hosted operation. Use Apify if developers need actor-style runs, APIs, schedules, and datasets. Use Web Scraper Cloud if sitemap workflows fit your stack. Use Thunderbit when AI-assisted field detection matters more than deterministic selectors. Use Bright Data or managed data services when reliability, proxies, and API delivery matter more than a one-off analyst export.
For adjacent reading, use the companion how-to guide, browse the full template library, or return to the UScraper blog for more scraper comparisons.
FAQ
Use hosted actors or APIs for cloud scale, SaaS tools for managed visual scraping, scripts for engineering control, and UScraper for local desktop app CSV exports.