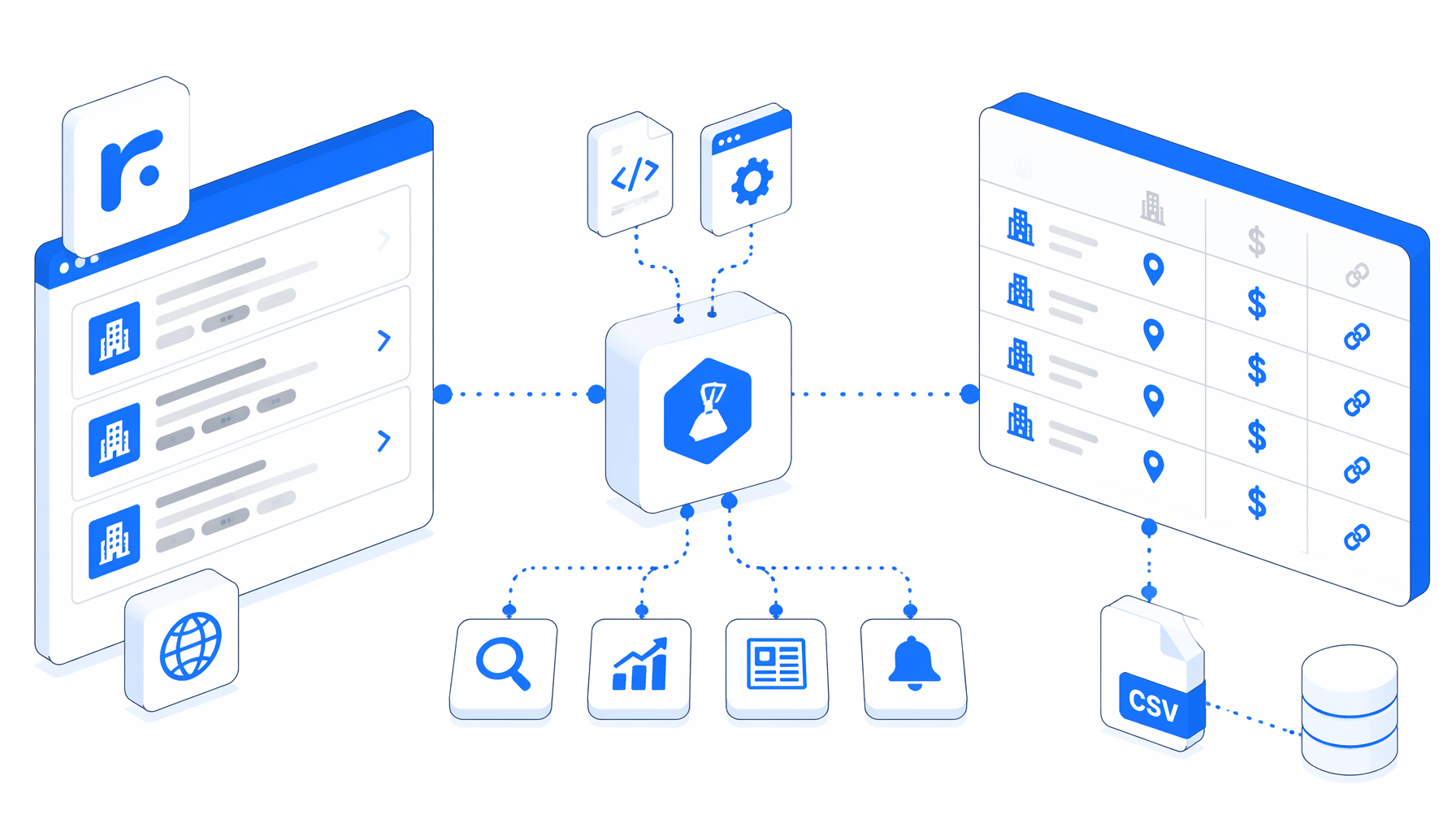
A Rikunabi NEXT job scraper is useful when a team needs a narrow, auditable hiring-data snapshot, not an uncontrolled crawl. The Rikunabi NEXT Job Scraper by URL template opens reviewed job-detail URLs, extracts visible job and company sections, and appends one structured row per page into CSV.
Use-case frame
When Rikunabi NEXT job data needs structure
Manual job-board research does not fail because one page is hard to read. It fails because the tenth page is copied differently from the first, source URLs disappear, and salary or requirement text gets normalized before anyone has checked the original wording. That is risky for recruiting benchmarks, labor-market research, SEO content planning, and newsroom analysis.
Rikunabi NEXT is a live job-search site, so the best first workflow is scoped: gather a reviewed list of current job-detail URLs, run a small batch, validate the CSV, and keep every row tied to the original page. Start from the official Rikunabi NEXT site, review the current robots directives, and check the official terms and privacy help page before automation.
Treat job-posting data as a dated research extract, not a permanent copy of Rikunabi NEXT. Keep the source URL, collection date, and business purpose attached to the dataset.
Personas
Rikunabi NEXT job scraper use cases by team
| Persona | Pain | CSV outcome |
|---|---|---|
| Recruiting researchers | Salary, benefits, and requirement language are hard to compare by hand. | Export 給与, 待遇福利厚生, 求めている人材, and ページURL for role benchmarking. |
| Labor-market analysts | Online job advertisements need traceable collection notes before analysis. | Keep posting period, location, company facts, industry, and source URL in a repeatable row shape. |
| SEO and content teams | Hiring pages reveal role wording, demand signals, and category language. | Compare job titles, requirement phrases, location terms, and company categories before writing market pages. |
| Newsrooms | Public-interest reporting needs a defensible sample, not a messy spreadsheet. | Build a source-linked dataset that reporters can spot-check before publication. |
| Monitoring teams | Competitor hiring changes are easy to miss when pages expire. | Re-run approved URL lists or refreshed URL sets and compare dates, salary text, and job descriptions. |
Online job-advertisement data is already used in labor-market research. For context, compare this workflow with the Bank of Japan paper on regular-worker labor markets using online job advertisement data, the ILO paper on methodological issues in online labour-market data, and OECD guidance on scraping publicly accessible data responsibly.
Workflow
From research pain to structured Rikunabi NEXT export
The template is intentionally narrow. It does not promise to discover every job on Rikunabi NEXT. It loops through a multi-URL Navigate list, waits for the page to load, waits for visible body text and the application CTA text, sleeps briefly, then runs Structured Export in append mode. The JSON workflow is the authoritative definition; the article version is the operating model.
Define the research question
Decide whether you are comparing salary bands, location coverage, skill requirements, benefits language, employer profiles, or hiring frequency.
Collect reviewed job URLs
Add only current next.rikunabi.com/viewjob/... pages that open normally in a browser and match the project scope.
Run a small CSV batch
Start with 5 to 10 URLs. Check Japanese text encoding, blank fields, section boundaries, and the ページURL column before expanding.
Analyze a raw copy first
Keep the first CSV untouched. Normalize salary, location, industry, and benefits in a separate worksheet or database table.
| Export group | Fields to inspect | Why it matters |
|---|---|---|
| Employer identity | 会社名, 会社ホームページ, 企業ページ, 業種 | Helps connect postings to company research and deduplication. |
| Job content | 仕事の内容, 求めている人材, 勤務地, 給与 | Supports role comparison, skill analysis, and compensation checks. |
| Work conditions | 勤務時間, 休日休暇, 待遇福利厚生 | Useful for recruiting benchmarks and benefits-language monitoring. |
| Company facts | 代表者, 資本金, 売上高, 従業員数, 事業所 | Adds context when the page exposes company profile sections. |
| Audit trail | 掲載期間, ページURL | Keeps time and source evidence attached to every row. |
Examples
Concrete Rikunabi NEXT data workflows
Recruiting benchmark snapshots
A recruiting team can collect a controlled set of job pages for a role family, export salary, location, required profile, hours, holidays, and benefits, then compare wording across employers. The CSV should not be treated as the final compensation model. It is the evidence layer that lets a recruiter ask better questions before making a hiring recommendation.
Labor-market and policy research
Researchers can use a Rikunabi NEXT jobs CSV as a small source-linked sample inside a broader methodology. The key is documentation: input URLs, collection date, field definitions, missing-value rules, and a note that job postings reflect the publishing platform and collection scope. The World Bank paper on online job-posting data for labor-market policy is useful background for why methodology matters.
SEO and content planning
SEO teams can study how employers describe technical skills, managerial seniority, remote-work expectations, locations, and industries. That does not mean copying job descriptions. It means extracting patterns, validating them, and using them to write more accurate market pages, glossary entries, or hiring guides.
Newsroom and public-interest checks
Journalists may need a bounded sample of public job pages for a story about wage ranges, benefits language, staffing shortages, or regional hiring. The scraper helps create a reviewable table, but reporters still need screenshots, editorial notes, legal review, and manual verification before publication.
Use UScraper when an analyst wants a local desktop workflow, CSV custody, and explicit control over the URL list. Octoparse has a Rikunabi NEXT template for no-code users. Apify actors fit hosted execution and API workflows. Python fits teams prepared to own code, testing, storage, throttling, and maintenance.
FAQ
Rikunabi NEXT scraper FAQ
Who should use a Rikunabi NEXT job scraper?
Recruiting researchers, labor-market analysts, SEO teams, newsrooms, and monitoring teams should use one when they need a controlled CSV from reviewed job-detail URLs instead of manual copy and paste.
What fields matter most in a Rikunabi NEXT jobs CSV?
The most useful fields are company name, company website, Rikunabi company page, contact block, posting period, job description, required profile, location, salary, working hours, holidays, benefits, company facts, industry, and source page URL.
Is UScraper a Rikunabi NEXT scraper alternative to Python?
Yes, for analyst-led URL batches. Python is better when an engineering team wants full control over crawling, retries, storage, tests, and long-term maintenance. UScraper is better when the goal is a visible local desktop workflow that exports selected job pages to CSV.
Is it legal to scrape Rikunabi NEXT job pages for research?
Public visibility does not automatically grant permission for automated collection. Review Rikunabi NEXT terms, robots directives, privacy obligations, copyright rules, and employment-data restrictions. Keep runs modest, use reviewed URLs, and do not bypass access controls.
Where should teams keep Rikunabi NEXT export evidence?
Keep the CSV with the input URL list, collection date, business purpose, scraper version, and validation notes. The page URL column should stay with every row so analysts can audit source pages before publishing, enriching, or sharing the data.
Next step
Open the Rikunabi NEXT Job Scraper by URL, import the workflow, and run a short validation batch. For setup details, use the companion how-to guide, or browse the wider UScraper template library and blog for adjacent job-board workflows.