This Rikunabi NEXT scraping tutorial shows how to turn a reviewed list of job-detail URLs into a clean CSV using UScraper. The goal is not to crawl all of Rikunabi NEXT. It is to collect selected /viewjob/ pages, export the visible job and company fields, validate the rows, and keep the workflow understandable enough for recruiting, market research, and data operations teams.
The fastest path is the Rikunabi NEXT Job Scraper by URL template. Import it from the template page, replace the sample URLs with current approved job pages, and use this guide as the operating checklist before you run a batch.
Before you run
Prerequisites for scraping Rikunabi NEXT job pages
You need the UScraper local desktop app, the downloadable template JSON, a short list of current next.rikunabi.com/viewjob/... URLs, and a destination folder for CSV output. You should also have a spreadsheet editor that can open UTF-8 Japanese text without corrupting characters.
Start with 5 to 10 URLs, not hundreds. Rikunabi NEXT listings can expire, sample URLs from older tutorials may now return 404, and pages can differ by job category. A small test batch tells you whether the selector logic still matches the current page structure before you rely on the export.
Treat the CSV as a focused research extract, not a permanent mirror of Rikunabi NEXT. Keep the source URL, collection date, and business purpose with every dataset.
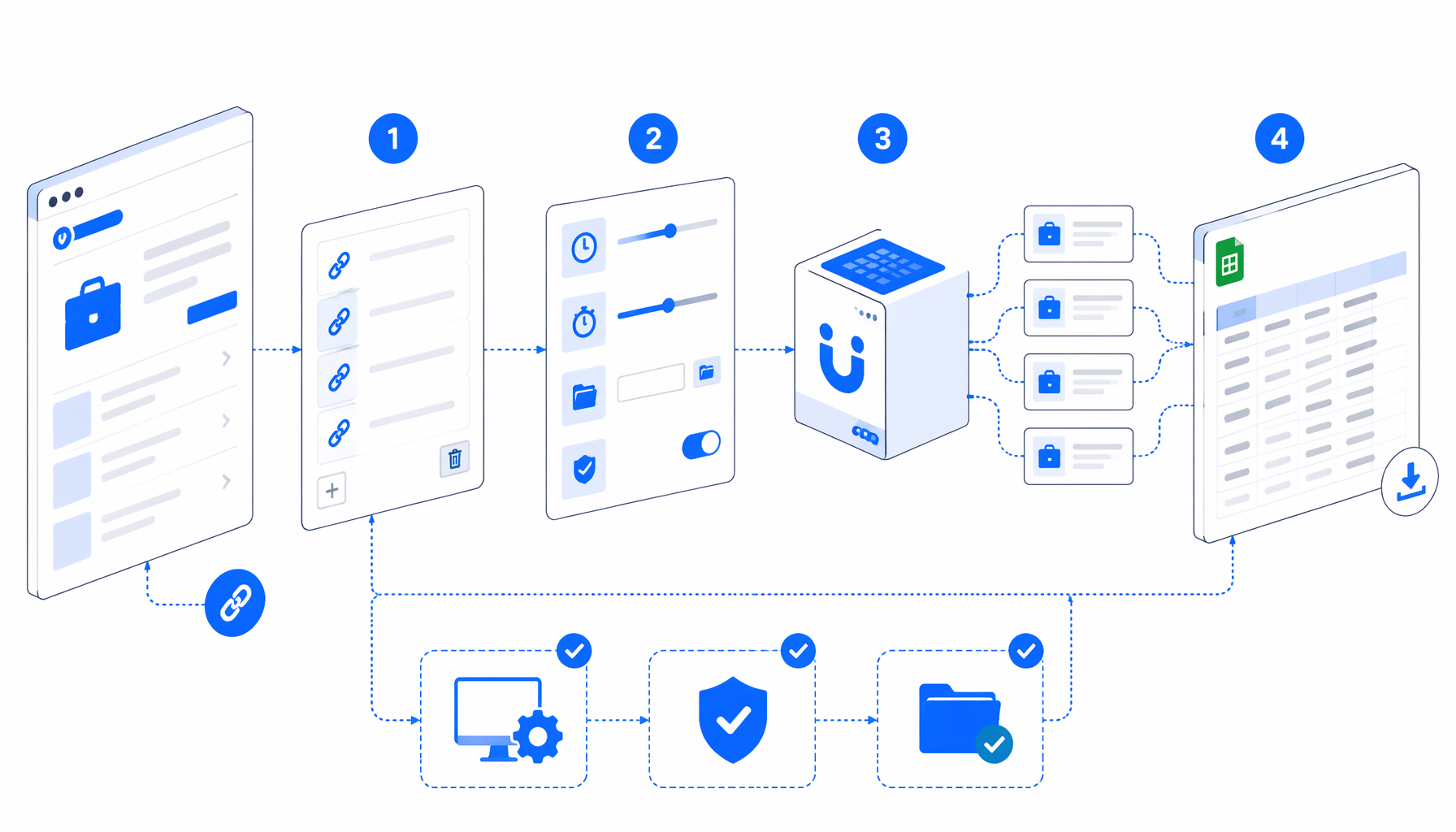
Workflow shape
How the Rikunabi NEXT scraper template works
The template is a by-URL workflow. It does not discover every listing from search results. Instead, the Navigate block contains a multi-URL list of reviewed job pages, and Loop Continue advances through that list until each page has passed the same waits and export step.
| Block | What it does | Why it matters |
|---|---|---|
| Navigate | Opens each supplied /viewjob/ URL | Keeps scope explicit and auditable |
| Wait for Page Load | Lets the browser finish the initial render | Reduces partial rows from slow pages |
| Wait for Element | Confirms body is visible | Prevents exporting before the page exists |
| Wait for Text | Looks for 応募画面へ進む | Confirms the detail page has loaded a real job state |
| Sleep | Adds a short settle delay | Helps late text and layout sections hydrate |
| Structured Export | Writes custom columns to CSV | Creates one normalized job row |
| Loop Continue | Advances the URL list | Repeats the same extraction reliably |
The JSON export is the authoritative workflow definition. In summary, it extracts the current job summary and labeled detail sections before recommendation modules, related-search blocks, and footer content.
{
"project": {
"name": "Rikunabi NEXT Job Scraper by URL"
},
"blocks": [
{ "title": "Navigate", "config": { "urls": ["https://next.rikunabi.com/viewjob/..."] } },
{ "title": "Wait for Page Load", "config": { "timeout": 30 } },
{ "title": "Wait for Text", "config": { "text": "応募画面へ進む", "timeout": 20 } },
{
"title": "Structured Export",
"config": {
"fileName": "rikunabi_next_job_scraper_refined.csv",
"fileMode": "append",
"columns": ["会社名", "会社ホームページ", "勤務地", "給与", "ページURL"]
}
},
{ "title": "Loop Continue" }
]
}
Steps
How to scrape Rikunabi NEXT jobs by URL
Import the template
Open the Rikunabi NEXT template, download the JSON workflow, and import it into UScraper. Keep the original copy unchanged so you can compare later edits.
Replace the URL list
Open the Navigate block and paste only current, reviewed next.rikunabi.com/viewjob/... pages. Remove expired examples, search-result URLs, login pages, and recommendation links.
Set the export path
In Structured Export, choose the save folder and confirm the file name rikunabi_next_job_scraper_refined.csv. Append mode is useful for batches, but clear old test rows before production runs.
Run a small validation batch
Run 5 to 10 URLs first. Check that company, salary, location, working hours, benefits, and page URL fields are populated where the page actually contains those sections.
Scale cautiously
If the test rows look correct, add more URLs in manageable batches. Keep waits conservative, pause when verification appears, and archive each CSV with the collection date.
What fields the CSV should contain
The template is tuned for recruiting research where a single row needs both job details and company context. Some fields may be blank because the page does not publish that information, not because the scraper failed.
| CSV field | Validation tip |
|---|---|
会社名 and 会社ホームページ | Confirm company names are not pulled from recommendation cards |
企業ページ and 連絡先 | Check whether the original page exposes profile or contact text |
掲載期間 | Use this to identify stale rows during later analysis |
仕事の内容 and 求めている人材 | Spot-check long text for section bleed into the next heading |
勤務地, 給与, 勤務時間, 休日休暇 | Compare against the visible job summary before trusting salary benchmarks |
待遇福利厚生 | Expect long multiline content after spreadsheet import |
代表者, 資本金, 売上高, 従業員数, 事業所, 業種 | Useful for company enrichment, but availability varies |
ページURL | Required for audit trails and deduplication |
Validation
Common issues in a Rikunabi NEXT scraping tutorial
Replace it before the batch. Job-board URLs are temporary by nature, and older Octoparse samples or GitHub scraping examples often point to pages that no longer exist.
Rikunabi NEXT Octoparse, Apify, Python, and UScraper alternatives
Use the tool that matches your operating model. Octoparse offers a no-code template surface. Apify actors are practical when you need hosted runs, API examples, or Python and CLI integration. A custom Python scraper gives full control but puts maintenance, throttling, parsing, and compliance work on your team.
| Approach | Best fit | Trade-off |
|---|---|---|
| UScraper local desktop app | Analysts who want reviewed URL lists, local CSV custody, and editable no-code waits | You manage input URLs and validation |
| Octoparse Rikunabi NEXT template | No-code users who prefer a hosted template ecosystem | Less control over local file custody |
| Apify Rikunabi actor | Developers who want cloud actors, API calls, Python examples, or scheduled runs | Metered hosted execution and external data flow |
| Custom Python | Engineering teams with long-term scraper ownership | Highest flexibility, highest maintenance |
For this tutorial, UScraper is intentionally narrow: import, configure URLs, export CSV, validate, and repeat. That simplicity is useful when your workflow starts from approved job-detail URLs rather than broad search crawling.
FAQ
Rikunabi NEXT scraping FAQ
Is it legal to scrape Rikunabi NEXT job pages?
Public visibility does not automatically grant permission for automated collection. Check Rikunabi NEXT terms, privacy notices, robots guidance, copyright rules, and employment-data obligations before running a batch. Use reviewed URLs, modest pacing, and do not bypass access controls.
What data does this Rikunabi NEXT scraper export?
It exports one CSV row per job detail URL with company, homepage, company page, contact block, posting period, job description, requirements, location, salary, hours, holidays, benefits, company facts, industry, and page URL.
Do I need Python to scrape Rikunabi NEXT with UScraper?
No. Python examples are useful if you want custom code, but this workflow is built from no-code blocks: Navigate, Wait for Page Load, Wait for Element, Wait for Text, Sleep, Structured Export, and Loop Continue.
Why does a Rikunabi NEXT URL return a blank row or 404?
The listing may have expired, redirected, or rendered a different page state. Replace stale sample URLs, confirm each /viewjob/ page opens normally, increase waits for slow pages, and remove rows where the URL points to an unavailable listing.
How is UScraper different from Apify or Octoparse for this task?
Apify is useful for hosted actors, API access, and scheduled cloud runs. Octoparse is a no-code hosted-template alternative. UScraper is better when you want a local desktop app, CSV custody, and direct control over reviewed job-detail URLs.
Next step
Download the Rikunabi NEXT Job Scraper by URL, run a short validation batch, then browse the broader template library or the UScraper blog for adjacent job-board scraping workflows.