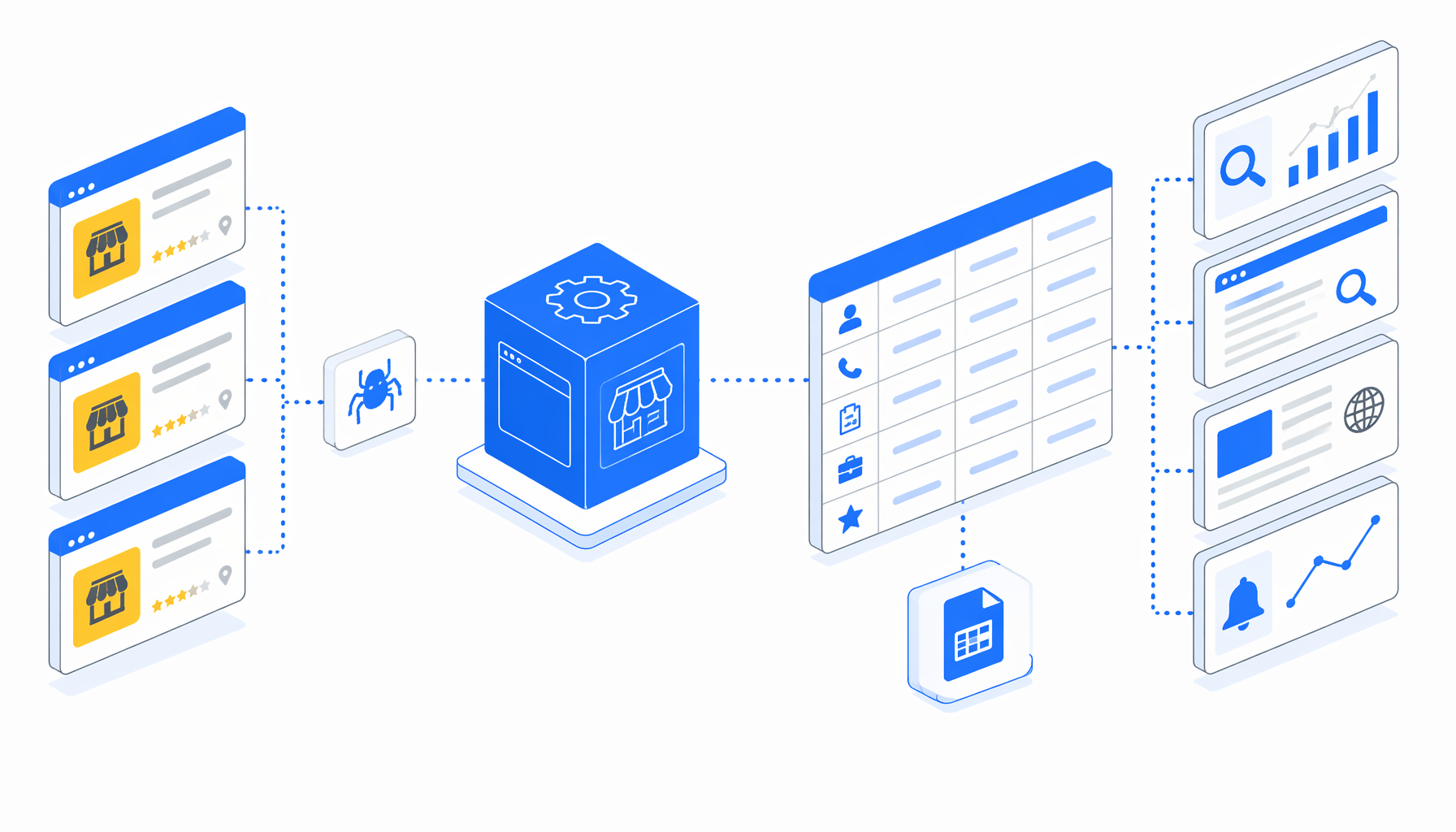
A Pagine Gialle Shop scraper is most useful when a team needs a controlled dataset from reviewed PagineGialle.it business or shop detail URLs. The Pagine Gialle Shop Detail Scraper template turns those pages into a local CSV with names, addresses, phones, descriptions, services, products, VAT IDs, ratings, review counts, and image URLs.
Use-case frame
Why Pagine Gialle Shop data matters
PagineGialle is no longer only a static yellow-pages-style directory. Italiaonline announced the PagineGialle Shop e-commerce platform in 2024, and the official PagineGialle Shop marketplace now sits beside directory pages, category indexes, seller onboarding, and product discovery surfaces. Useful business context is spread across many tabs.
The paginegialle shop detail scraper use case is about turning profile-level observations into rows. A newsroom can inspect whether restaurant profiles publish phone numbers and opening hours. An SEO team can compare category language across cities. A marketplace analyst can monitor seller-facing positioning from the PagineGialle Shop seller page, then collect supporting detail fields for a known sample.
A directory row is not automatically a lead. It is a source-backed business record that still needs review, consent-aware outreach rules, and a clear reason to process each field.
Personas
Who uses a Pagine Gialle shop scraper?
| Persona | Pain | CSV outcome |
|---|---|---|
| Market researchers | Local-business notes become inconsistent. | Export name, address, phone, category, products, services, ratings, and source URL. |
| Newsrooms | Reporters need dated evidence. | Keep profile text, phone, hours, rating, review count, and image URL together. |
| SEO teams | Category language changes by city and vertical. | Compare Categorie, Caratteristiche_e_servizi, Prodotti, and descriptions. |
| Monitoring teams | Removed pages and stale phones are easy to miss. | Re-run the same reviewed URL list and compare rows over time. |
| Agencies | Enrichment needs inspectable fields. | Export rows, deduplicate by URL, then validate before CRM import. |
Pain to outcome
From manual tabs to structured PagineGialle export
The problem
Researchers copy names, phones, and services by hand, then lose the page that produced each value.
What you do instead
Keep the canonical shop URL as the first CSV field.
Every exported row starts with URL_negozio, so QA can return to the source profile before reporting or outreach.
The problem
Old or deleted profile URLs create misleading blank rows in spreadsheets.
What you do instead
Skip removed pages before extraction.
The workflow checks for the removed-page message and continues the loop instead of appending junk data.
The problem
Profile layouts expose different fields in JSON-LD, meta tags, and visible text.
What you do instead
Normalize page data before export.
The extraction script builds window.__pgData from structured data first, then cleaned page-text fallbacks.
The problem
Teams need a file they can inspect without adding a hosted scraping vendor to the data path.
What you do instead
Run a local desktop app workflow and save CSV locally.
The bundled Structured Export block appends to crawler_dettagli_negozi_paginegialle_v2.csv in the configured folder.
The template follows a practical graph: Navigate -> Wait for Page Load -> safe consent click -> Sleep -> Wait for body -> removed-page check -> data cache script -> Structured Export -> Loop Continue. Names, phones, services, VAT IDs, ratings, and images can come from structured data, meta tags, or visible sections depending on the page.
Workflows
Concrete use cases for PagineGialle research
Local market mapping
Start with a curated list of profiles for one category, city, or seller segment. The CSV gives researchers a consistent row shape for names, addresses, phones, categories, service labels, products, review counts, and images.
SEO entity and category research
SEO teams can use pagine gialle and paginegialle exports to understand service wording across verticals. Descrizione, Caratteristiche_e_servizi, Prodotti, and Categorie help writers compare real directory language before creating local pages, audits, or taxonomies.
Newsroom and public-interest checks
A newsroom may need to inspect whether clinics, restaurants, repair shops, or professional services publish consistent contact and business identifiers. The scraper creates an auditable first pass; reporters still keep screenshots, timestamps, notes, and legal review outside the automation.
Seller and marketplace monitoring
Analysts can review the official category index, marketplace FAQs, and seller onboarding content, then run exports for approved businesses to compare profile completeness, service language, and review signals.
Output shape
What the PagineGialle shop detail scraper exports
No CSV sample was included in the bundle, so the JSON workflow definition is the authoritative sample of the export shape. One valid detail URL should append one CSV row with these fields:
| Export group | Columns |
|---|---|
| Source and identity | URL_negozio, Nome_negozio, URL_immagine |
| Contact and location | Indirizzo, Numero_telefono |
| Profile text | Astratto, Descrizione |
| Services and products | Servizio1, Servizio2, Servizio3, Caratteristiche_e_servizi, Prodotti, Categorie |
| Operations and identifiers | Orari_di_apertura, P_IVA, Codice_fiscale |
| Trust signals | Valutazione, Recensioni_totali |
| QA symptom | Likely cause | Analyst response |
|---|---|---|
| Blank VAT or tax field | The profile does not publish P. IVA or codice fiscale. | Leave it blank unless the source page visibly contains the value. |
| Missing phone | The page omits it, hides it behind interaction, or renders differently. | Reopen the source URL and validate before changing selectors. |
| Duplicate rows | The same URL was supplied twice or append mode was reused during testing. | Deduplicate by URL_negozio and rerun into a clean file for delivery. |
| Empty description | Meta data or profile text was absent on that page. | Treat it as a review flag, not a reason to invent a summary. |
Tool choice
PagineGialle scraper vs Octoparse, Apify, and cloud tools
Searches like paginegialle scraper vs octoparse, pagine gialle scraper alternative, and how to scrape paginegialle mix different jobs. Choose by custody, scale, scheduling, and workflow visibility.
| Route | Good fit | Trade-off |
|---|---|---|
| Hosted templates such as Octoparse, Apify, Thunderbit, or Scrapebit | Managed cloud runs, scheduling, APIs, proxies, or vendor-managed scraping. | Output passes through a third-party platform; pricing may scale with records, credits, or compute. |
| Custom code or open-source scripts | Engineering teams that want full control over requests, parsing, tests, and deployment. | Needs maintenance when layouts, consent flows, or controls change. |
| UScraper Pagine Gialle template | Analyst-led exports from reviewed detail URLs, visible workflow blocks, and a local CSV. | Best for curated research, not broad crawling or bypassing access controls. |
For step-by-step setup, read the companion Pagine Gialle scraper tutorial. To browse adjacent workflows, use the UScraper template library or the broader blog archive.
FAQ
Pagine Gialle shop scraper FAQ
Use it when researchers, SEO teams, newsrooms, agencies, or monitoring teams already have reviewed PagineGialle.it detail URLs and need a local CSV with business identity, contact, service, category, rating, tax, and source URL fields.