This Pagine Gialle scraper tutorial shows how to turn reviewed PagineGialle.it shop or store detail URLs into a structured CSV with the Pagine Gialle Shop Detail Scraper for UScraper. You will prepare source URLs, import the workflow, confirm the local export path, validate the first rows, and decide when a local desktop app is a better fit than a hosted scraper or API.
Before you start
Prerequisites and source URLs
You need UScraper installed as a local desktop app, the free template JSON imported into your workspace, a writable CSV folder, and a short list of PagineGialle.it detail URLs your team is allowed to review. The sample workflow uses restaurant profile pages such as https://www.paginegialle.it/pizzeria-bisteccheria-triticum-roma. Here, "shop detail" means store or business profile detail pages, not private account pages, checkout flows, order history, or login-only marketplace data.
PagineGialle has multiple public surfaces: the main directory, the PagineGialle Shop marketplace, category pages, product pages, FAQ pages, and policy pages. Before scraping, review the current PagineGialle personal data and terms page, the PagineGialle robots.txt, and any terms that apply to your use case. These pages are policy context, not automatic permission.
Treat automation as a controlled research workflow. Do not bypass access controls, do not scrape private user data, and do not use a CSV for outreach or resale until your legal and compliance checks are done.
Workflow anatomy
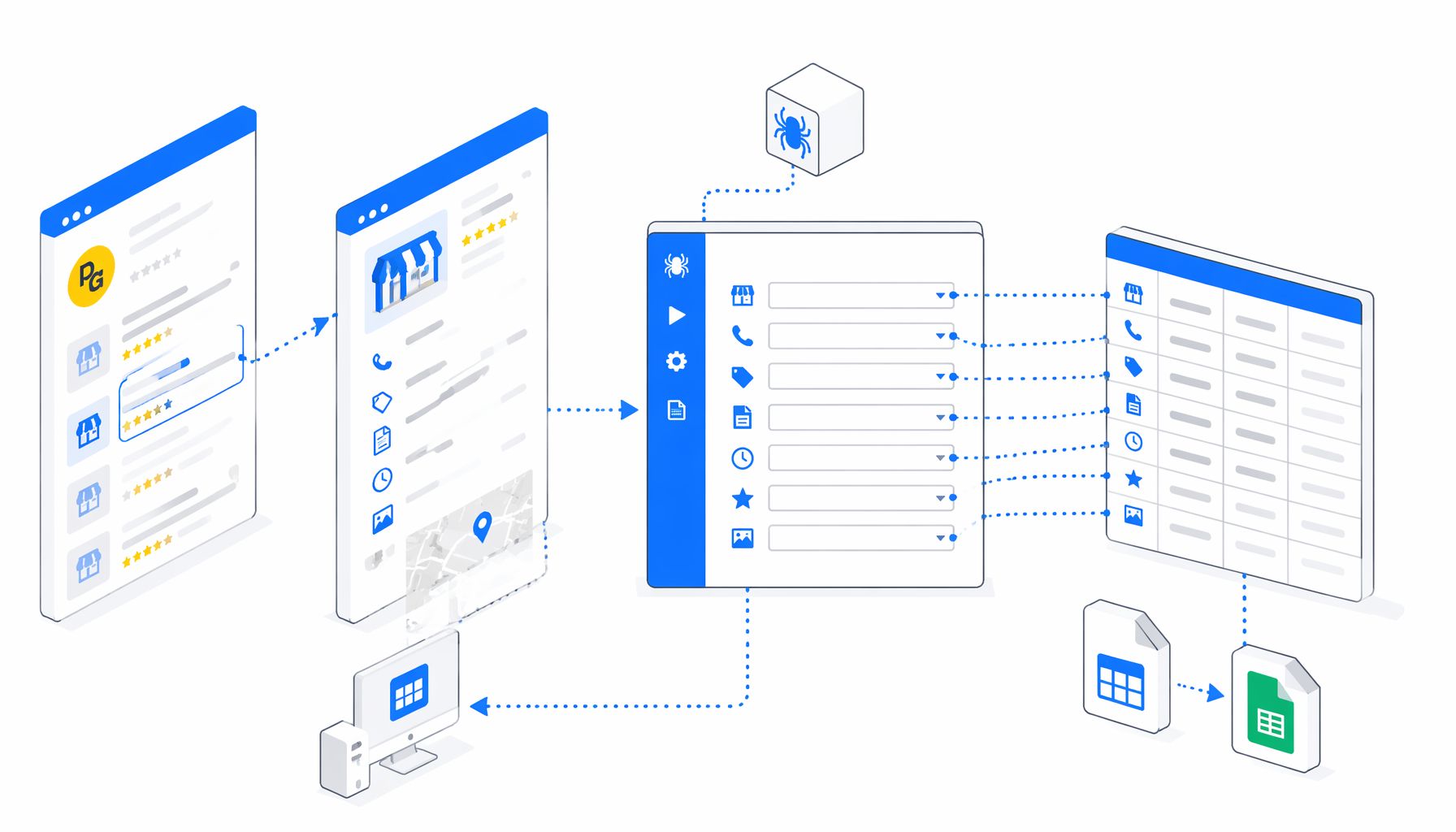
How the Pagine Gialle Shop Detail Scraper works
The JSON export is the authoritative workflow definition. It follows a clear browser automation path: Navigate -> Wait for Page Load -> safe consent click -> Sleep -> Wait for body -> removed-page check -> data cache script -> Structured Export -> Loop Continue.
Navigate stores the profile URLs. The first JavaScript block looks for a safe consent button and avoids preference-management controls. The removed-page check looks for the Italian deleted-page message so old URLs do not create junk rows. The second JavaScript block normalizes the page into window.__pgData, favoring JSON-LD and meta data before falling back to cleaned visible text. Structured Export then reads that object and appends a row.
| Workflow block | What to check | Why it matters |
|---|---|---|
| Navigate | One PagineGialle.it detail URL per item | One valid source URL should create one CSV row. |
| Consent script | Positive consent button only | Prevents the run from opening settings panels or clicking unrelated controls. |
| Removed-page check | The deleted-page text condition remains in place | Old profile URLs are skipped instead of producing misleading rows. |
| Data cache script | JSON-LD, meta, and text fallbacks | Different profiles expose name, address, hours, and services differently. |
| Structured Export | File name, folder, headers, append mode | Keeps every validated profile in one spreadsheet-ready file. |
Runbook
How to scrape PagineGialle detail pages to CSV
Import the template
Open the Pagine Gialle Shop Detail Scraper page, download the JSON workflow, and import it into UScraper.
Replace sample URLs
In Navigate, replace the sample restaurant pages with the PagineGialle.it detail URLs you have reviewed. Keep one URL per entry.
Keep the waits and checks
Leave the page-load wait, consent handler, body wait, and removed-page branch in place while testing. Increase waits before changing extraction logic.
Confirm the export folder
In Structured Export, review crawler_dettagli_negozi_paginegialle_v2.csv, headers, append mode, and your local save location.
Run and validate
Run a small batch, compare each row with the source page, deduplicate by URL_negozio, then add more URLs only after quality is consistent.
Append mode is useful for curated URL lists, but it can hide repeated test rows. For a clean validation run, write to a fresh folder or rename the output before restarting. Keep the source URL column so reviewers can return to the original profile quickly.
Output
What the CSV export includes
The template is for profile-level business research where a listing card is not enough. Each row represents one valid PagineGialle.it detail page and keeps contact, category, tax, and review fields together.
| CSV column | Meaning |
|---|---|
URL_negozio, Nome_negozio | Canonical source URL and business or shop name. |
Indirizzo, Numero_telefono | Address and phone values from schema, markup, or visible text. |
Astratto, Descrizione | Short meta summary and longer profile description when available. |
Servizio1, Servizio2, Servizio3 | First service labels split into separate review-friendly fields. |
Orari_di_apertura, Caratteristiche_e_servizi | Opening hours and combined service tags. |
Prodotti, Categorie | Product labels and category information when exposed by the profile. |
P_IVA, Codice_fiscale | VAT and tax identifiers parsed from page text. |
Valutazione, Recensioni_totali, URL_immagine | Rating, review count, and representative image URL. |
Validation
Validate rows before scaling
Do not treat the first export as production data. Open the CSV next to the source pages and review rows from the start, middle, and end of the run. PagineGialle profiles can differ by category, seller data quality, removed pages, consent state, layout, and structured JSON-LD coverage.
| Symptom | Likely cause | Fix |
|---|---|---|
| No business name | URL is removed, redirected, or did not render correctly | Open the URL manually and rerun one page after it loads normally. |
| Missing phone or address | The profile does not expose the field consistently | Treat the cell as unknown unless the source page visibly contains the value. |
| Empty services | Category-specific layout or labels filtered as navigation text | Check multiple profiles before loosening filters. |
| Blank VAT or tax ID | The page does not publish P. IVA or codice fiscale | Do not infer tax data from other sources inside this workflow. |
| Duplicate rows | Duplicate input URL or repeated append-mode test | Deduplicate by URL_negozio and rerun into a clean file. |
FAQ
Pagine Gialle scraper tutorial FAQ
Public PagineGialle.it detail pages can still be governed by site terms, robots guidance, database rights, privacy rules, and marketing regulations. Review official policies, avoid restricted content, collect only fields you have a lawful reason to process, and get legal review before commercial reuse.
For the maintained workflow, download the free Pagine Gialle Shop Detail Scraper template. To compare more local data workflows, browse the UScraper templates library or read more UScraper tutorials.