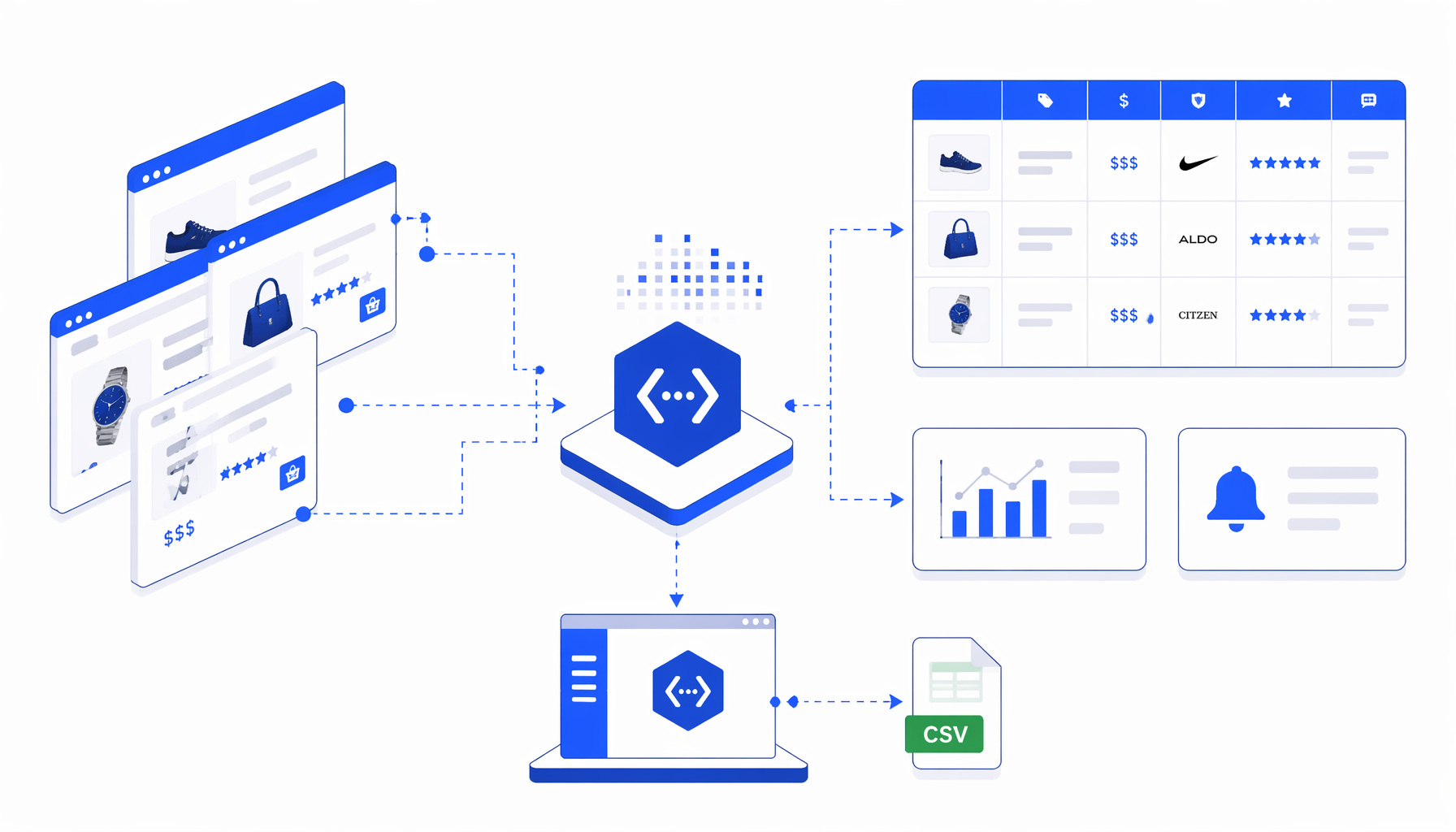
The Liverpool Details Scraper template turns reviewed Liverpool.com.mx PDP URLs into a CSV with product, image, code, price, brand, reviews, color, and rating fields for research, newsrooms, SEO, catalog QA, and monitoring.
Use-case frame
Why Liverpool product data needs a workflow
Liverpool Mexico is a high-visibility ecommerce source for retail research, but its product pages are built for shoppers, not spreadsheets. Manual copying works for five products; it breaks when a newsroom needs traceable examples, an SEO team needs category language, or a pricing analyst needs the same URL list every week.
For market context, pair product-level rows with Liverpool's annual report, the AMVO online sales study, Similarweb traffic checks, and Semrush visibility checks. Those sources explain demand and visibility; they do not replace page-level product evidence.
A product price is not a research record unless it includes the source URL, run date, field names, and enough QA notes to explain blanks or page changes.
Before automation, check Liverpool's current robots.txt, product-detail sitemap, terms and conditions, and privacy notice. A sitemap helps discovery; it is not permission to reuse data for every purpose.
Personas
Who uses a Liverpool product scraper?
| Persona | Pain | CSV outcome |
|---|---|---|
| Retail researchers | Assortment checks are scattered across product tabs. | Compare product names, codes, brands, colors, prices, ratings, and review counts. |
| Newsrooms | Ecommerce stories need examples that editors can verify. | Keep product rows beside source URLs, screenshots, and reporting notes. |
| SEO teams | Category briefs need real product phrasing, not guessed keywords. | Export titles, brands, colors, and product URLs for copy and search intent analysis. |
| Price monitoring teams | Weekly checks get noisy when analysts copy values by hand. | Re-run the same URL list and compare current price, original price, rating, and reviews. |
| Catalog QA teams | Supplier sheets and live PDPs drift over time. | Flag missing images, changed codes, blank brands, and inconsistent product names. |
Workflow
How the template turns PDP URLs into CSV rows
The bundled JSON workflow is intentionally small: Navigate -> Wait for Page Load -> Sleep -> Structured Export -> Loop Continue. Navigate contains the multi-input URL list. Wait and Sleep give product modules time to render. Structured Export maps visible page values into named columns. Loop Continue advances through the next product URL and appends the next row.
| Workflow block | What it does | Use-case impact |
|---|---|---|
| Navigate | Opens each Liverpool PDP URL from the input list. | Keeps the run tied to a reviewed research sample. |
| Wait for Page Load | Waits for the document to finish loading. | Reduces blank rows from slow product pages. |
| Sleep | Adds a short pause before export. | Gives images, price modules, and review widgets time to settle. |
| Structured Export | Writes custom fields to CSV in append mode. | Produces one spreadsheet-ready file for the whole sample. |
| Loop Continue | Moves to the next URL. | Prevents the run from stopping after the first product. |
liverpool-detalles-scraper.csvColumn
Producto
Visible product title.
Column
Producto_URL
Source PDP for audit.
Column
Imagen_URL
Primary product image URL.
Column
Codigo_de_producto
Visible product code or URL identifier.
Column
Opiniones
Review count when exposed.
Column
Precio
Current price text.
Column
Precio_original
Original price when both prices exist.
Column
Color
Visible color value.
Column
Marca
Brand label.
Column
Calificacion
Normalized rating when available.
Scenarios
Four concrete Liverpool scraping workflows
Build a research sample
Select PDP URLs from a category, campaign, or brand set. Export product, price, brand, rating, and review fields, then attach the CSV to the research brief.
Support newsroom evidence
For a story about ecommerce pricing, assortment, or product availability, keep the CSV as an evidence index. Pair rows with screenshots and manual editorial checks.
Prepare SEO briefs
Export real product titles, brand labels, color words, and product URLs. Use them to identify category language, naming patterns, and content gaps without scraping private pages.
Monitor a stable URL list
Re-run the same approved PDP URLs weekly or monthly. Compare price, original price, reviews, rating, and blank fields between snapshots.
The workflow is strongest when the input list is curated. It is not meant to guess every product Liverpool sells, bypass verification prompts, or replace an official data agreement. If a URL returns a 404, placeholder assets, or a challenge screen, the export may leave fields blank rather than inventing values.
Alternatives
Liverpool scraper alternative: local CSV vs hosted tools
Searches like best Liverpool scraping tool, Liverpool scraper alternative, and how to scrape Liverpool usually hide a trade-off: local CSV, hosted dataset, API, or managed feed?
Use UScraper when analysts want editable visual blocks, visible browser QA, and CSV files saved to a chosen local folder.
UScraper is the practical choice when the deliverable is a checked CSV from known PDP URLs. Hosted platforms are better when your requirement is remote scheduling, API delivery, managed proxies, or very large recurring runs.
Governance
QA and compliance before scale
Use responsible scraping practices before expanding a Liverpool details run. Zyte's ecommerce scraping guidance and data compliance materials are useful background for access, rate limits, data minimization, and review steps. Document why you collect the data, who can access the CSV, where it is stored, and whether redistribution is allowed.
| Check | Why it matters |
|---|---|
| Confirm URL scope | Use product-detail pages, not account, checkout, login-only, or restricted pages. |
| Validate one row per URL | The expected shape is one PDP URL becoming one CSV row. |
| Treat blanks as QA events | Blanks can mean old URLs, slow modules, layout changes, or verification screens. |
| Keep run notes | Save input URLs, run date, template version, file name, and selector edits. |
| Review data rights | Decide allowed storage, sharing, enrichment, reporting, and commercial reuse. |
Browse adjacent retail workflows in the template library, read the companion Liverpool scraper tutorial, or compare hosted options in the Liverpool scraper alternatives guide.
FAQ
Liverpool product scraping FAQ
Start from reviewed PDP URLs, import the template, run a small validation batch, and export one CSV row per product page. Keep source URLs, run dates, and QA notes beside the data.
Next step
Download the Liverpool Details Scraper
Use the Liverpool Details Scraper template when your team has a defined PDP URL list, a clear research question, and a need for local CSV output. Run a small validation batch first, then expand only after the exported rows match the browser.