This tutorial shows how to scrape Liverpool product details into CSV with the Liverpool Details Scraper for UScraper. You will prepare product detail URLs, import the workflow, set the export folder, run a small validation batch, and review the fields before using the output for catalog QA, price research, or competitive monitoring.
Before you start
Prerequisites, source URLs, and policy checks
You need UScraper installed as a local desktop app, a folder where CSV exports can be written, and a reviewed list of Liverpool product detail pages. This guide is for PDP URLs such as /tienda/pdp/.../1169156316. It is not for checkout flows, private account pages, cart data, login-only prices, or CAPTCHA bypassing.
Use official references before automation. Liverpool publishes robots.txt, a sitemap index, and product-detail sitemap files such as 1pdp.xml. They explain URL patterns and crawl guidance, not blanket permission. Also review Liverpool's terms and conditions before saving or sharing exports.
Technical access is not the same as permission. Keep batches modest, do not bypass verification screens, and prefer official or contractual access when the data will drive production systems.
Workflow anatomy
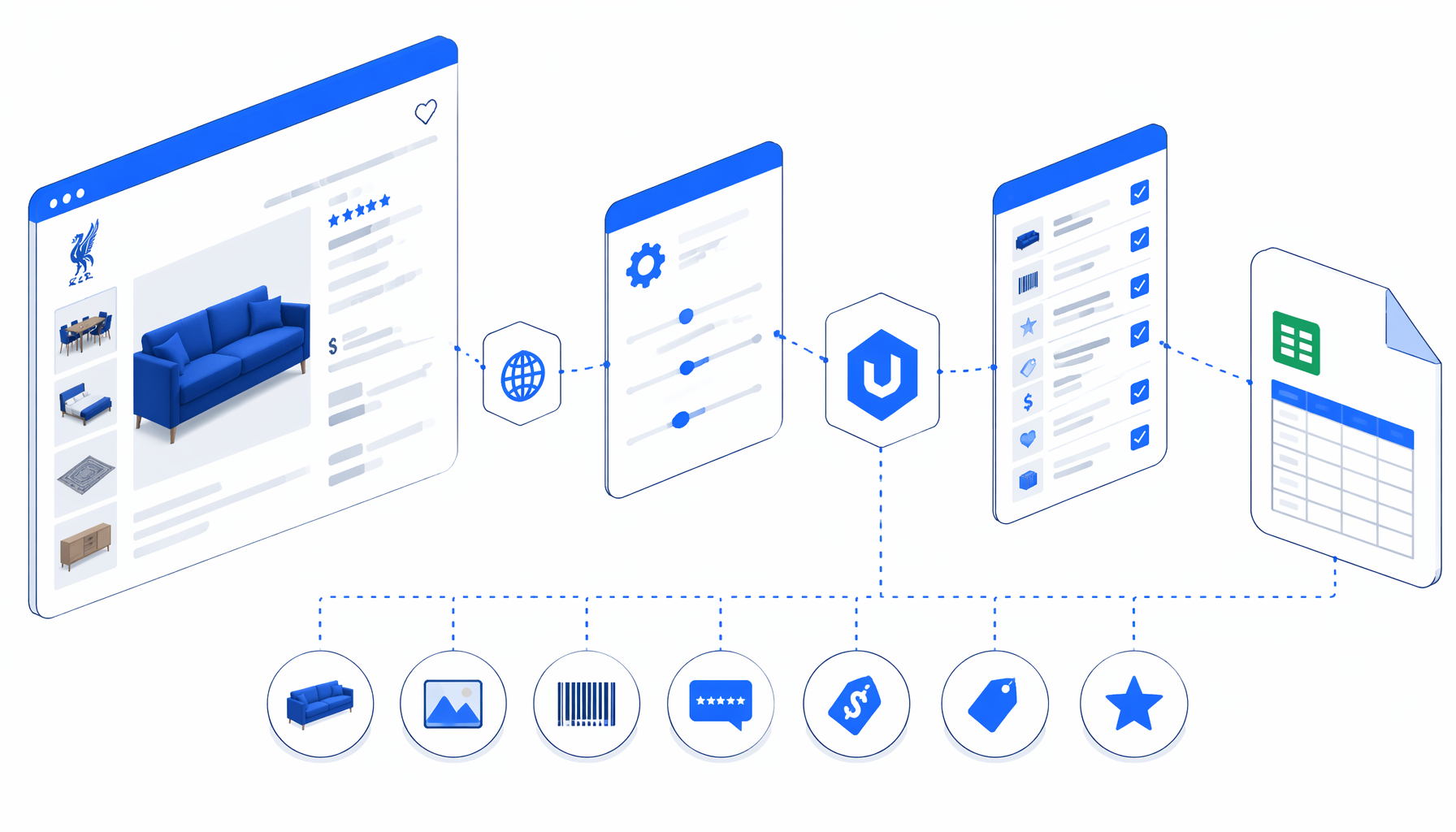
How the Liverpool product details scraper works
The JSON export is the authoritative workflow definition. The graph is intentionally compact: Navigate -> Wait for Page Load -> Sleep -> Structured Export -> Loop Continue.
Navigate contains the multi-input PDP URL list. Wait for Page Load allows the document to finish loading. Sleep adds a short buffer for dynamic product modules, image galleries, price text, review widgets, and brand labels. Structured Export reads from the page body and maps custom JavaScript selectors into CSV columns. Loop Continue advances to the next URL and appends the next product row to the same file.
| Workflow block | What to check | Why it matters |
|---|---|---|
| Navigate | One Liverpool PDP URL per input | One product detail page should create one CSV row. |
| Wait for Page Load | Keep the 45-second timeout while testing | Mixed categories and media-heavy PDPs can load slowly. |
| Sleep | Keep the 4-second buffer before export | Late price, image, review, and rating modules need time to settle. |
| Structured Export | File name, save location, headers, append mode | Keeps every URL in one spreadsheet-ready export. |
| Loop Continue | Last block in the URL loop | Prevents the run from stopping after the first product. |
Runbook
Scrape Liverpool product pages to CSV
Import the template
Open Liverpool Details Scraper, download the JSON workflow, and import it into UScraper.
Replace the sample URLs
In the Navigate block, replace the sample Liverpool PDP links with your approved product detail URLs. Keep a small first batch.
Keep the waits
Leave Wait for Page Load and Sleep in place while validating. Increase waits before changing selectors if pages are slow.
Confirm the export folder
In Structured Export, verify liverpool-detalles-scraper.csv, headers, append mode, and the local save location.
Run, inspect, then scale
Run a small batch, compare rows against live PDPs, then add more product URLs only after field quality looks consistent.
Append mode is useful for a controlled URL list, but it can surprise you during repeated tests. Use a clean folder or rename the file when you want a fresh validation run. Keep Producto_URL in every downstream worksheet so reviewers can return to the source page quickly.
Output
What the Liverpool details CSV includes
The template is designed for product-detail analysis where listing cards are not enough. Each row represents one supplied PDP URL, not one search result card.
| CSV column | Meaning |
|---|---|
Producto, Producto_URL, Imagen_URL | Product title, source PDP, and primary image URL. |
Codigo_de_producto, Marca, Color | Product code plus visible brand and color values. |
Precio, Precio_original | Current price and original price when both price modules exist. |
Opiniones, Calificacion | Visible review count and normalized rating. |
Use the CSV in spreadsheets, BI tools, catalog QA scripts, or pricing review sheets.
Validation
Validate prices, images, ratings, and blank cells
Do not treat the first file as production-ready. Open the CSV beside the source PDPs and review rows from the start, middle, and end of the run. Liverpool product pages can vary by category, inventory state, promotion, region, layout experiment, or verification prompt.
| Symptom | Likely cause | Fix |
|---|---|---|
| Blank product name | PDP did not render, URL returned 404, or a challenge page loaded | Open the source URL manually, then rerun one product after the page loads normally. |
| Missing price | Product unavailable, promotion module changed, or price text loaded late | Increase waits and compare the row against the live PDP before changing extraction logic. |
| Placeholder image | Old URL, lazy gallery issue, or fallback asset | Check Imagen_URL in the browser and keep invalid images out of catalog imports. |
| Empty brand or color | The current page does not expose the field or uses a category-specific layout | Treat blanks as unknown and update selectors only after checking multiple PDPs. |
| Duplicate rows | Duplicate input URL or rerun appended to the same file | Deduplicate by Producto_URL and product code. |
FAQ
Liverpool product scraper FAQ
Public product pages can still be governed by site terms, robots guidance, anti-bot controls, copyright, privacy rules, and local law. Review the current rules, collect only what you are allowed to use, keep volumes modest, and do not bypass access controls.
For the maintained workflow, download the free Liverpool Details Scraper template. To browse more retail workflows, visit the UScraper templates library or the broader UScraper blog for comparison and tutorial posts.