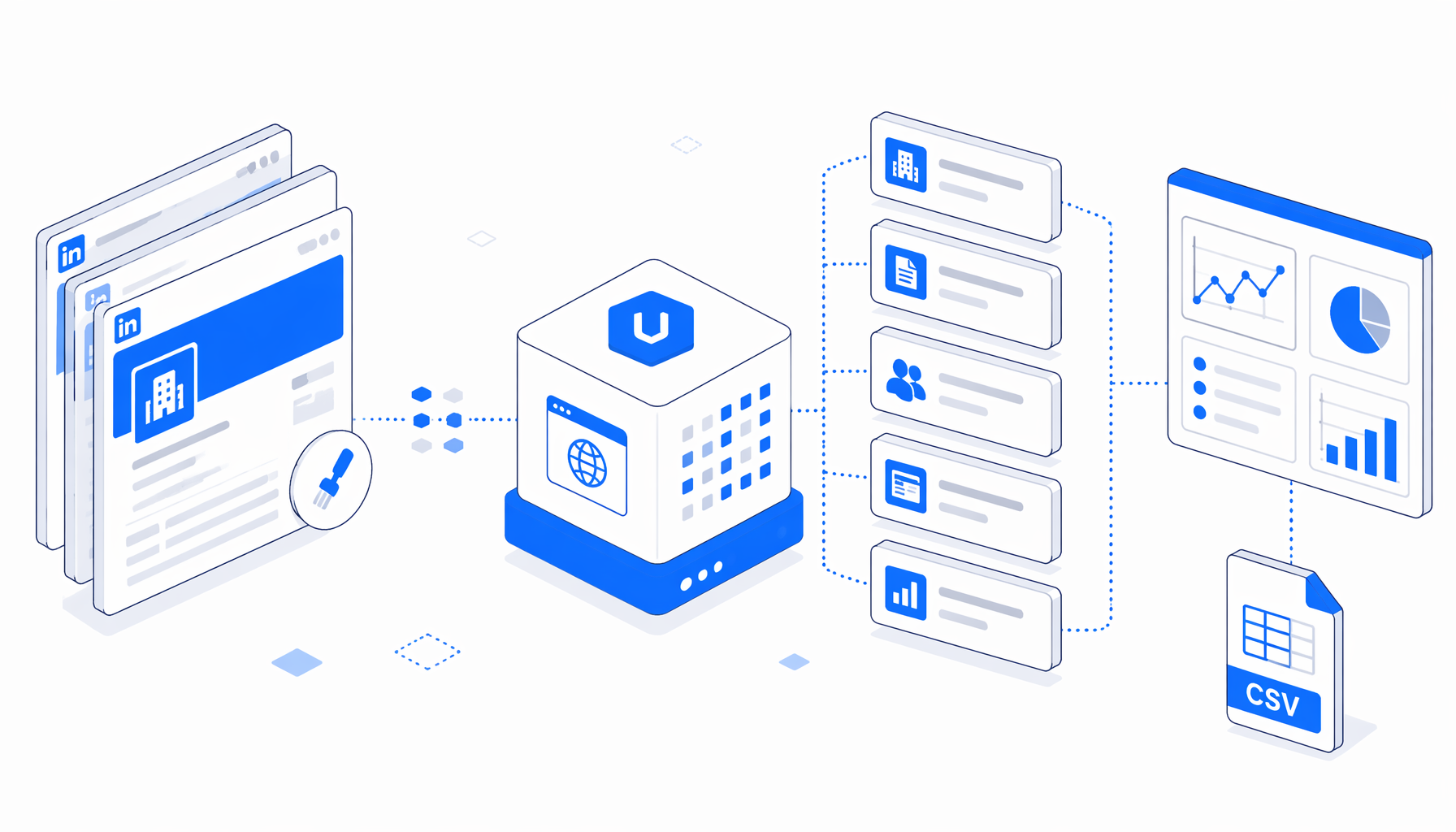
A LinkedIn company profile scraper is most useful when the team already knows which company pages it is allowed to review. The LinkedIn Company Profile Scraper template turns a visible company profile, About tab, People tab, and Posts tab into a structured CSV with profile fields, visible employee summaries, post context, and diagnostic status rows.
Use-case frame
How to scrape LinkedIn company pages without losing context
Manual LinkedIn company research breaks down when the same profile needs to be checked by a researcher, editor, analyst, or client. A useful row needs the source URL, scrape status, company intro, industry, website, size, headquarters, specialties, visible people signals, post text, links, dates, and engagement counts when visible.
That is the problem this template solves. It does not try to be a general permission layer or a hidden backend. It opens the page in a local browser session, checks whether LinkedIn has shown a login wall or security verification, writes a diagnostic row if access fails, and exports structured fields when the session can view the company page.
The valuable workflow is not "collect everything." It is "collect the visible fields needed for this research question, keep the URL beside every row, and verify the output before analysis."
Personas
Who uses LinkedIn company scraper tools?
| Persona | Pain | CSV outcome |
|---|---|---|
| Market researchers | Company snapshots are scattered across profiles, posts, and notes. | Export company name, industry, intro, website, size, headquarters, specialties, followers, and source URLs for comparison. |
| Newsrooms | Editors need dated evidence before publishing a business or labor-market story. | Keep source URLs, visible profile text, post references, and status fields beside screenshots and manual verification notes. |
| SEO and content teams | Competitive positioning research becomes unstructured copy-paste. | Compare About copy, specialties, company size language, locations, and recent themes across a controlled company list. |
| Agencies | Client discovery work needs a repeatable account-research file. | Turn approved LinkedIn company URLs into a reviewable CSV before CRM cleanup, enrichment, or outreach planning. |
| Monitoring teams | Company pages change, but browser checks do not leave a clean history. | Re-run the same approved pages and compare dated CSV snapshots for visible changes in profile, people, and posts. |
The template fits supervised research better than blind scale. A newsroom might check companies in a funding story, an SEO team might compare service positioning, and a sales operations team might review metadata before enrichment. Each workflow benefits from a small batch, clear purpose, and exported evidence.
Workflow
From pain to structured LinkedIn company export
The JSON workflow behind the template follows a conservative browser path. It sets a normal viewport, navigates to the company overview URL, waits, checks authwall and verification selectors, then branches. If access is blocked, the export still writes blocked_by_linkedin_authwall_or_security_verification so the CSV explains what happened. If access is available, it exports overview fields and visits the About, People, and Posts tabs.
One file for review
The workflow appends overview, about, people, posts, and diagnostic rows into linkedin-company-scraper.csv so analysts can filter by scrape_status.
Authwall diagnostics
Empty output is hard to audit. The template writes a status row when LinkedIn blocks unauthenticated access or shows verification.
Visible people signals
The People tab branch scrolls visible records and joins names, profile links, intros, and avatars into reviewable fields when the session can see them.
Post context
The Posts branch captures visible poster text, post body, post links, dates, images, likes, comments, and follower text when rendered.
Output
What the LinkedIn company scraper exports
No CSV sample is bundled with this template, so the workflow JSON is the authoritative export shape. The file name is linkedin-company-scraper.csv, headers are included on the first export, and later page branches append rows using the same broad field set.
linkedin-company-scraper.csvColumn
page_url
The LinkedIn company URL or tab URL opened during the run.
Column
scrape_status
Status such as ok_overview_page, ok_about_page, visible-loaded page states, or authwall diagnostics.
Column
company_name
Company title from the profile top card or configured fallback.
Column
industry
Visible industry text when exposed on the profile or About page.
Column
website
External website detected from the company page.
Column
company_size
Company size text or employee count when rendered.
Column
headquarters
Headquarters field from the About section.
Column
employee_name
Loaded visible employee names joined for the People row.
Column
employee_link
Visible LinkedIn profile links from people cards.
Column
post_body
Visible post text from loaded company post cards.
Column
posted_date
Date or sub-description text detected near visible posts.
Column
like_count
Visible reaction count parsed from post text when available.
Blank cells are not always bugs. Overview rows do not contain post fields, People rows do not contain About details, and diagnostic rows may only include the URL, status, fallback values, and login guidance.
Use cases
Concrete LinkedIn company page monitoring workflows
Competitor positioning research
SEO teams can run a short approved competitor list monthly and compare About descriptions, specialties, company size, headquarters, and post themes. The CSV makes it easier to separate repeated language from real positioning changes before writing briefs.
Newsroom and policy research
Reporters can use the scraper as a source ledger for companies referenced in a story. Pair the spreadsheet with screenshots, timestamps, editorial notes, and manual verification because a CSV is evidence for review, not a substitute for reporting.
Account research for agencies
Agencies can export company profile basics before discovery calls, partner audits, or CRM hygiene work. Every row keeps the LinkedIn page URL and status beside the browser-visible fields.
Hiring and headcount signal checks
Researchers sometimes monitor visible company text, people cards, and posts for hiring signals. Keep this narrow and review privacy obligations carefully, especially when personal profile links or employee summaries appear in the export.
API fit
LinkedIn company API alternative or local CSV workflow?
Searches for linkedin company api alternative often mix two different needs. One need is governed access to official LinkedIn data for approved applications. The other is analyst-led research from pages a person can already view. The first belongs with official APIs or licensed vendors. The second can often start with a local CSV workflow.
| Need | Better route | Why |
|---|---|---|
| Approved Page administration, analytics, and integrations | Official LinkedIn APIs | Built for sanctioned account and organization workflows. |
| High-volume company data delivery | Licensed data provider or scraper API | Contracts, support, infrastructure, and normalized JSON matter more than a visual run. |
| Sales automation chains | Dedicated outreach or automation platform | Better when extraction feeds sequences, CRM tasks, or account operations. |
| Research snapshots from approved pages | UScraper template | Local browser visibility, inspectable workflow blocks, and CSV output are enough. |
| One-off company check | Manual browser review | No automation is needed for a single fact check. |
For vendor trade-offs, read the LinkedIn company scraper tools comparison. For step-by-step setup, use the LinkedIn company scraper tutorial. You can also browse the wider template library or return to the UScraper blog.
FAQ
LinkedIn company scraper FAQ
Use it when researchers, newsrooms, SEO teams, agencies, or monitoring teams need a supervised CSV snapshot of approved company pages, visible people cards, and visible posts.