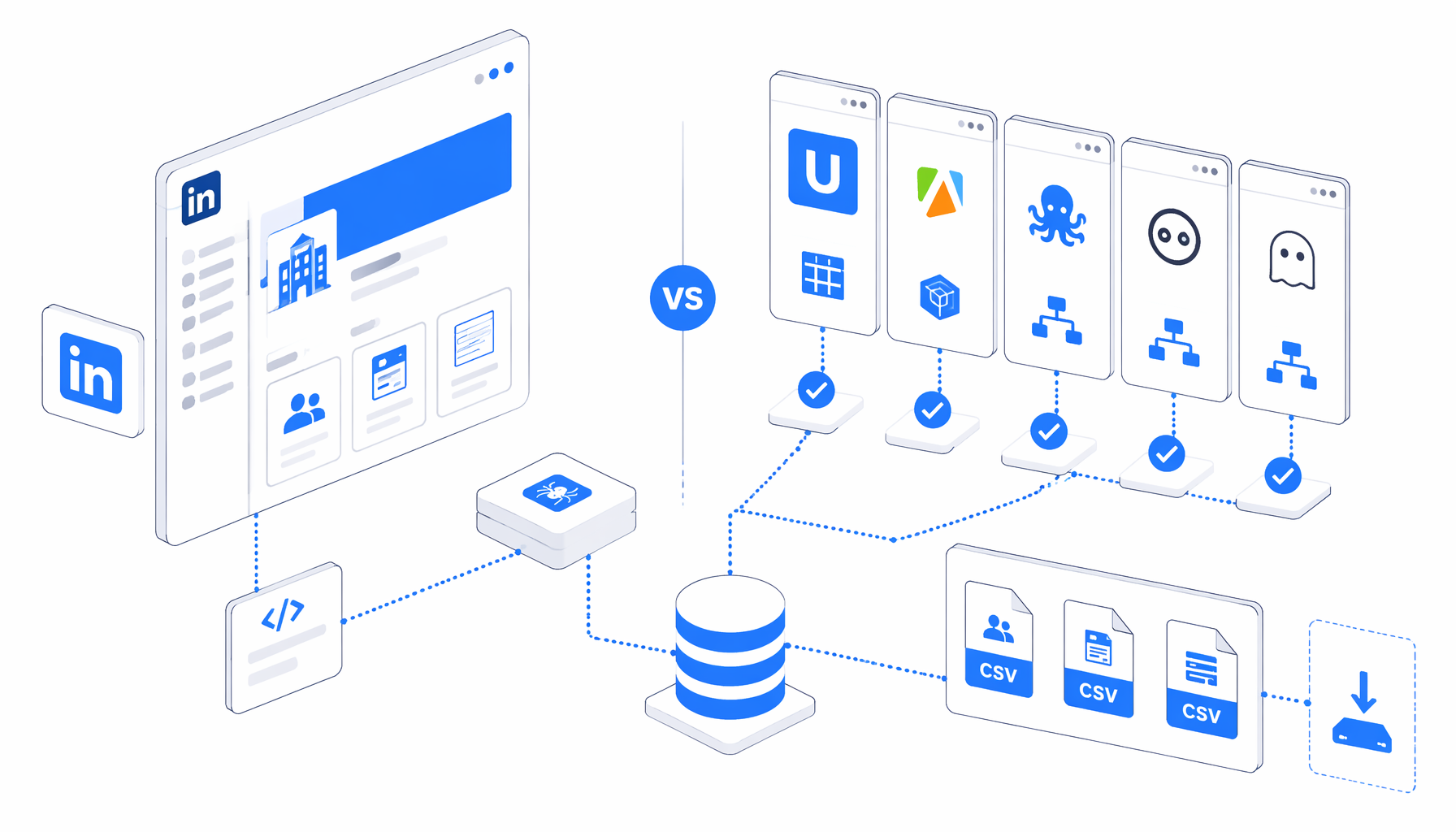
The best LinkedIn company scraper depends on whether you need a local CSV, a cloud actor, an API contract, a visual SaaS template, or an outreach workflow. This comparison puts UScraper, Octoparse, Apify, Browse AI, PhantomBuster, Bright Data, and custom scripts through price, hosting, code, output, account handling, and maintenance.
Landscape
The main LinkedIn company scraper alternatives
Searches for linkedin company scraper alternatives usually lead to five product families.
Visual scraper platforms such as Octoparse's LinkedIn company profile template and Browse AI's LinkedIn company scraper give analysts templates, browser-like configuration, and exports without code.
Cloud actor marketplaces such as Apify's LinkedIn Company Profile Scraper and LinkedIn Company Profiles Scraper fit teams that want configurable jobs, datasets, API calls, webhooks, and usage-based infrastructure.
Sales automation tools such as PhantomBuster's LinkedIn Company Scraper sit closer to prospecting operations and can feed spreadsheets, CRMs, or other automations.
Scraper APIs and datasets such as Bright Data's LinkedIn Scraper API docs are strongest when engineers need structured JSON, contracts, support, and procurement-ready data infrastructure.
Local no-code workflows are where UScraper fits. The LinkedIn Company Profile Scraper template runs in the UScraper local desktop app, follows overview, About, People, and Posts views, and writes structured rows to linkedin-company-scraper.csv.
A LinkedIn scraper comparison should start with custody and permission, not feature count. If your source access, account rules, or legal basis are weak, a faster scraper only makes the risk faster.
Decision matrix
Compare price, hosting, code, output, and maintenance
Pricing pages change, so treat this table as a buying model rather than a live quote. Check the vendor pricing pages before procurement: Octoparse pricing, Apify pricing, Browse AI pricing, PhantomBuster pricing, and ParseHub pricing.
| Tool family | Hosting model | Code required | Output shape | Pricing shape | Where it wins |
|---|---|---|---|---|---|
| UScraper + LinkedIn company template | Local desktop app | No code; edit visual blocks and selectors | CSV with profile, about, visible people, visible posts, and scrape_status | Local desktop app license plus free template JSON | Local custody, visible browser QA, predictable small-team research |
| Octoparse | Hosted platform with visual templates | No-code to low-code | Excel, CSV, JSON depending on workflow | Subscription and plan limits | Larger template ecosystem, cloud scheduling, analyst-friendly UI |
| Apify actors | Cloud actor runtime | Config first; API optional | Datasets, JSON, CSV, integrations | Usage-based platform billing and actor terms | Developer workflows, APIs, webhooks, scale-out runs |
| Browse AI | Hosted robot platform | No code | Tables, monitored changes, integrations | Credit or plan-based SaaS | Monitoring and repeatable hosted robots for non-developers |
| PhantomBuster | Hosted automation platform | No code; account/session setup | Spreadsheet, Excel, CSV, JSON, CRM paths | Subscription and execution limits | Sales ops teams chaining LinkedIn automations |
| Bright Data or similar APIs | Vendor API and dataset infrastructure | API integration | Structured JSON | API or dataset contract | Engineering teams that need supported endpoints and high-volume data delivery |
| Python, Playwright, Selenium scripts | Your machines or cloud | Full code ownership | Whatever you build | Engineering time plus infrastructure | Custom parsing, versioned tests, internal pipelines |
Where UScraper wins
Why choose UScraper for LinkedIn company profile scraping
UScraper is strongest when the operator wants to see what the browser sees. The template opens a company overview page, waits, checks for authwall or security verification markers, and writes a diagnostic row if LinkedIn blocks access. If the session can view the page, it exports overview data, then navigates through About, People, and Posts.
That makes the workflow more conservative than many "paste URLs and wait" tools. It does not pretend to bypass login walls. It records blocked_by_linkedin_authwall_or_security_verification when access fails, so a CSV audit does not quietly mix valid rows with empty rows.
UScraper
Snapshot- Tagline
- Local desktop app with a visual scraping flow and inspectable JSON template.
- Pricing
- Local desktop app license model; the LinkedIn company template JSON is free to download.
- Hosting
- Runs locally in a visible browser session; exports to a local CSV path.
- Best for
- Analysts validating approved LinkedIn company pages before enrichment, CRM cleanup, or competitor research.
- Less ideal for
- Hands-off high-volume cloud crawling where the team needs vendor-managed scheduling, APIs, and parallel infrastructure.
The CSV shape is intentionally broad: page_url, scrape_status, company profile fields, about fields, website, size, headquarters, specialties, visible employee links, visible post text, post links, dates, likes, and comments. Blank cells are expected because overview, people, posts, and diagnostic rows expose different fields.
Where competitors win
When Apify, Octoparse, Browse AI, PhantomBuster, or an API is better
Apify or a scraper API wins when engineering wants scheduled cloud jobs, API retrieval, datasets, webhooks, and run logs.
Octoparse wins when the team values a mature visual platform, many templates, and hosted export options.
Browse AI wins when the job is closer to monitoring visible page changes than exporting one-off research CSVs.
PhantomBuster wins when company extraction feeds a broader prospecting sequence.
UScraper wins when the buyer wants a supervised browser run, local export folder, visible block graph, and fewer moving parts than a new cloud account.
Python scripts beat no-code tools when engineers need unit tests and custom data contracts. UScraper beats scripts when non-developers need a maintainable visual workflow.
If your team already uses Apify storage, Bright Data endpoints, or PhantomBuster sequences, switching cost may outweigh UScraper's custody advantage. UScraper is best when a focused team wants to extract LinkedIn company data to CSV with a workflow they can watch, edit, and rerun locally.
Legal and API reality
LinkedIn access rules matter more than scraper choice
LinkedIn company pages may display public business information, but automated access can still be restricted by the LinkedIn User Agreement, LinkedIn robots directives, account rules, privacy law, and local regulations. For approved integrations, review the official LinkedIn Marketing API and Organizations API documentation.
Pick a lane
Which LinkedIn company scraper should you choose?
Choose UScraper for account research, competitor monitoring, partner scouting, or enrichment QA across a short approved company list. The LinkedIn Company Profile Scraper is especially useful when you need local CSV evidence and a clear scrape_status column.
Choose Octoparse for a broader hosted visual platform, Apify for actors and APIs, PhantomBuster for sales automation chains, Bright Data or another scraper API for supported structured JSON delivery, and Python, Playwright, or Selenium when engineering wants to own selectors, tests, sessions, and infrastructure.
For adjacent no-code scraping workflows, browse the UScraper template library, read the practical LinkedIn company scraper tutorial, or return to the UScraper blog for more comparison guides.
FAQ
LinkedIn company scraper FAQ
For supervised company research, UScraper plus the LinkedIn Company Profile Scraper template is the cleanest fit because it runs locally, exposes the browser state, and exports to linkedin-company-scraper.csv. For large recurring cloud jobs, Apify actors or scraper APIs may be better.
Next step
Download the LinkedIn company profile scraper
Start with the LinkedIn Company Profile Scraper template. Import the JSON into UScraper, replace the sample company URLs, run one approved profile first, and compare the CSV against the browser before scaling the workflow.