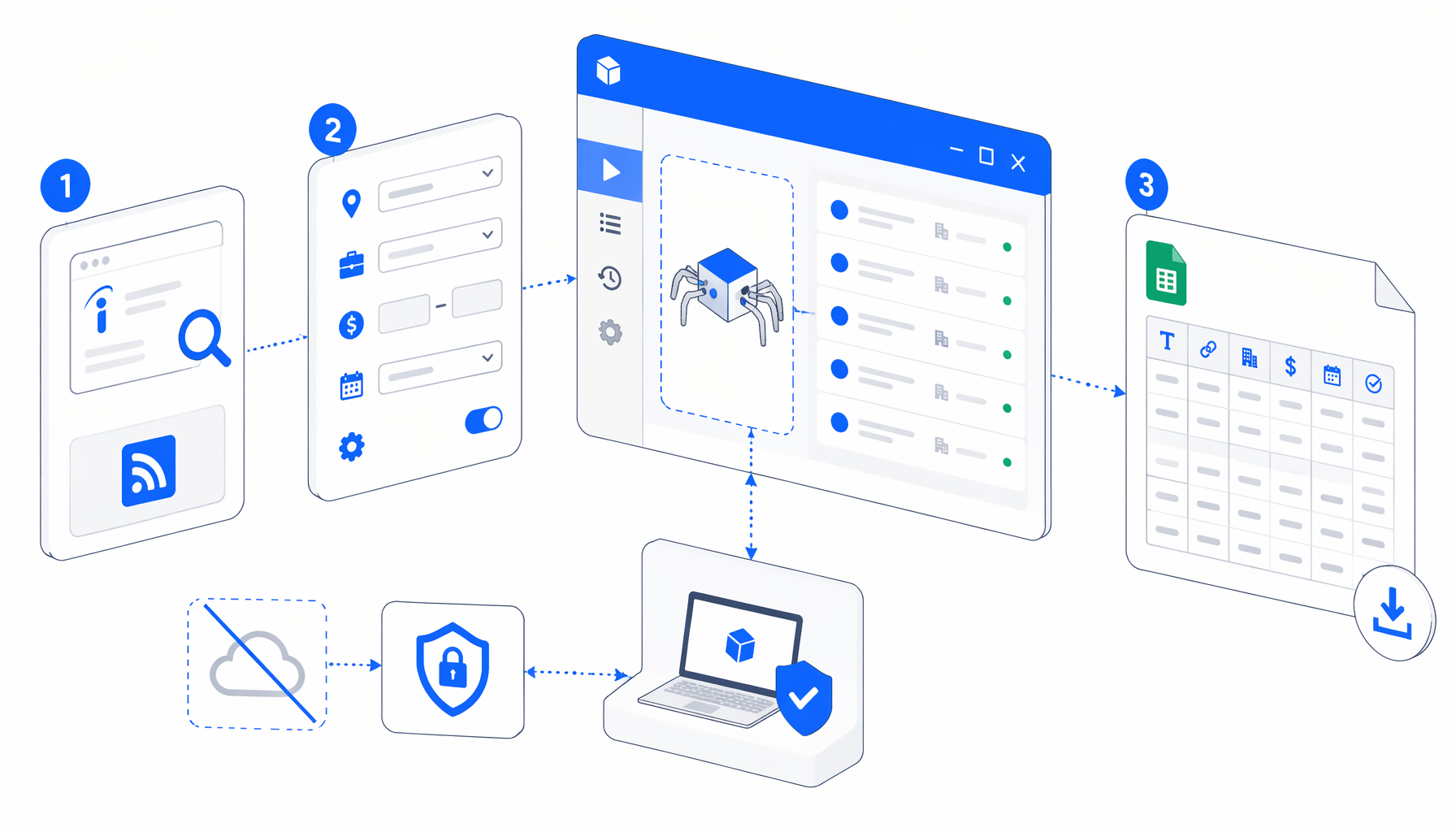
This Indeed scraping tutorial explains how to collect job-search feed rows into CSV with UScraper. You will review the policy checks, import the workflow, edit keyword and location URLs, choose the export path, validate rows, and understand why the template writes a diagnostic row when Indeed returns no usable items.
Download path: start from the Indeed Scraper template, then keep this tutorial open while you configure the workflow and audit the first CSV.
Before you start
Prerequisites and policy checks
You need UScraper installed as a local desktop app, the downloadable workflow from the template library, and a folder where the CSV can be saved. You also need a small, specific research question: for example, "software engineer roles in the United States", "remote data analyst jobs", or "contract recruiter listings in Chicago." A focused search is easier to validate than a broad crawl.
Review the current Indeed legal terms, Indeed Terms FAQ, and robots.txt before running automation. Indeed's robots file includes rules that matter to RSS, job detail, and paginated job-search URLs, so do not treat a feed URL as automatic permission to collect, store, republish, or resell job data.
Browser visibility is not the same as permission. If Indeed shows verification, CAPTCHA, login, access-denied, or empty-result screens, pause the run and document what happened.
Workflow
How the Indeed scraper workflow works
The JSON export is the source of truth. The bundled Navigate block opens five RSS URLs for the sample query software engineer in the United States, using start=0, start=10, start=20, start=30, and start=40. After each page loads, the workflow injects JavaScript that tries to parse RSS item records, cleans title and description text, detects salary or job-type phrases when present, and creates one visible .uscraper-rss-item element per row.
If no feed items are found, the workflow still exports one row with scrape_status set to blocked_or_no_items. That behavior is intentional. A failed run should leave evidence instead of silently creating an empty spreadsheet.
| Block | Purpose | Validation check |
|---|---|---|
| Navigate | Opens editable Indeed RSS search URLs | Confirm the keyword, location, and page offsets are intentional. |
| Wait and Sleep | Gives the response time to load | Increase waits only if feeds are slow, not to push past blocks. |
| Inject JavaScript | Parses feed items and creates normalized HTML rows | Check that .uscraper-rss-item exists before export. |
| Structured Export | Appends rows to indeed-scraper.csv | Confirm headers, append mode, and save folder. |
| Loop Continue | Advances through the URL list | Watch row counts and diagnostic rows after each offset. |
Export shape from the workflow definition
There is no bundled CSV sample for this post. Use the workflow definition and your first dry run together: the JSON defines the intended columns, while your local CSV confirms what Indeed returned for the exact keyword, location, session, and date.
indeed-scraper.csvColumn
job_title
Cleaned job title parsed from the feed item title.
Column
job_url
Indeed URL from the RSS link field.
Column
company
Company segment inferred from the title when available.
Column
location
Location segment inferred from the title when available.
Column
salary
Salary phrase detected in the description text.
Column
job_type
Full-time, part-time, contract, temporary, remote, or similar text.
Column
posted_date
RSS pubDate value.
Column
valid_date
Date when the workflow created the row.
Column
experience_level
Entry, senior, years-of-experience, or similar phrase when detected.
Column
description
Cleaned RSS description or diagnostic message.
Column
guid
RSS guid when present.
Column
source
Feed source text.
Column
feed_page_url
The RSS URL that produced the row.
Column
scrape_status
ok, or blocked_or_no_items for diagnostic rows.
Sample rows
1 of many
| job_title | job_url | company | location | salary | job_type | posted_date | valid_date | experience_level | description | guid | source | feed_page_url | scrape_status |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Senior Software Engineer | Example Health | Remote | $130,000 - $165,000 a year | full-time | Mon, 01 Jun 2026 10:00:00 GMT | 2026-06-25 | senior | Cleaned job description text | example-guid | Indeed | ok |
The authoritative JSON excerpt looks like this when reduced to the blocks and export columns that matter for setup:
{
"project": {
"name": "Indeed Scraper",
"description": "Uses Indeed RSS search URLs with start-offset pagination, normalizes available feed items into rows, and exports job data or a diagnostic row."
},
"blocks": [
{
"title": "Navigate",
"config": {
"urls": [
"https://www.indeed.com/rss?q=software+engineer&l=United+States&start=0",
"https://www.indeed.com/rss?q=software+engineer&l=United+States&start=10",
"https://www.indeed.com/rss?q=software+engineer&l=United+States&start=20"
]
}
},
{
"title": "Structured Export",
"config": {
"rowSelector": ".uscraper-rss-item",
"fileName": "indeed-scraper.csv",
"includeHeaders": true,
"fileMode": "append",
"columns": ["job_title", "job_url", "company", "location", "salary", "job_type", "posted_date", "valid_date", "experience_level", "description", "guid", "source", "feed_page_url", "scrape_status"]
}
}
]
}
Runbook
How to scrape Indeed jobs with the template
Run the sample search
Keep the default software engineer query for one test. This verifies the blocks, export path, and diagnostic behavior before you add your own search.
Edit keyword and location
In Navigate, update q for the role and l for the market. Keep two or three offsets for the first custom run.
Choose the export folder
In Structured Export, confirm indeed-scraper.csv, headers, append mode, and a project-specific local save path.
Validate the CSV
Open the export, filter scrape_status, compare several rows with the browser, and archive diagnostic rows separately.
Repeat carefully
Add more keywords, locations, or offsets only after the first run produces reviewed rows that match the search intent.
Common issues and fixes
Indeed did not return scrapeable RSS items to the automated browser. Check the page text preview, reduce the batch, verify the URL manually, and pause if the response is a challenge or access-control screen.
Indeed scraper Python vs a local no-code workflow
If you searched for indeed scraper python, the trade-off is control versus setup time. Python is appropriate when you need unit tests, custom storage, queues, monitoring, and approved infrastructure. A local desktop app workflow is faster when the task is a supervised research export: edit a URL list, run a few pages, inspect rows, and hand a CSV to a recruiter or analyst.
| Approach | Best fit | Trade-off |
|---|---|---|
| UScraper Indeed template | No-code CSV exports, small market snapshots, transparent local review | Best-effort against feed availability; validate every run. |
| Python scraper | Custom parsing, tests, databases, scheduled jobs | More code, more maintenance, same compliance obligations. |
| Hosted scraper or data provider | Managed infrastructure, higher volume, contracted delivery | Queries and output pass through a third party, often with per-run pricing. |
| Official or licensed access | Production use, redistribution, strict guarantees | Requires approval, terms, quotas, and integration work. |
FAQ
FAQ
Is it legal to scrape Indeed jobs?
Indeed pages and feeds may be reachable in a browser, but automated collection can still be limited by Indeed terms, robots directives, privacy law, copyright, and how you reuse job-posting text. Review the current rules, avoid private or login-only data, do not bypass access controls, and get legal review before commercial use.
Do I need an Indeed API or account?
No Indeed account or API key is built into the template. It opens editable RSS search URLs and exports fields that are present. Use official or licensed access when you need contractual reuse rights, scheduled delivery, or production guarantees.
What does the Indeed scraper export?
The workflow exports indeed-scraper.csv with job_title, job_url, company, location, salary, job_type, posted_date, valid_date, experience_level, description, guid, source, feed_page_url, and scrape_status.
Why does scrape_status say blocked_or_no_items?
That status means no usable RSS items were found. Indeed may have returned an interstitial, CAPTCHA, empty feed, changed endpoint, or blocked automated access. Treat the row as a diagnostic and pause rather than trying to force a result.
Can I use this instead of an Indeed scraper Python script?
Yes, when the goal is a reviewed CSV export without maintaining code. Use Python instead when your team needs custom logic, automated tests, databases, scheduling, and approved production infrastructure.
Where does the CSV export go?
Structured Export writes indeed-scraper.csv to the local save folder configured in the workflow. The stock template does not upload your CSV to UScraper infrastructure unless you add a separate upload or sharing step.
Related templates and next steps
Use the Indeed Scraper template for the RSS workflow in this tutorial. If your workflow starts from direct job-detail URLs, read the Indeed job scraper by URL tutorial. For broader options, browse the UScraper blog and template library before choosing between a local workflow, Python, hosted scraping actors, or licensed access.