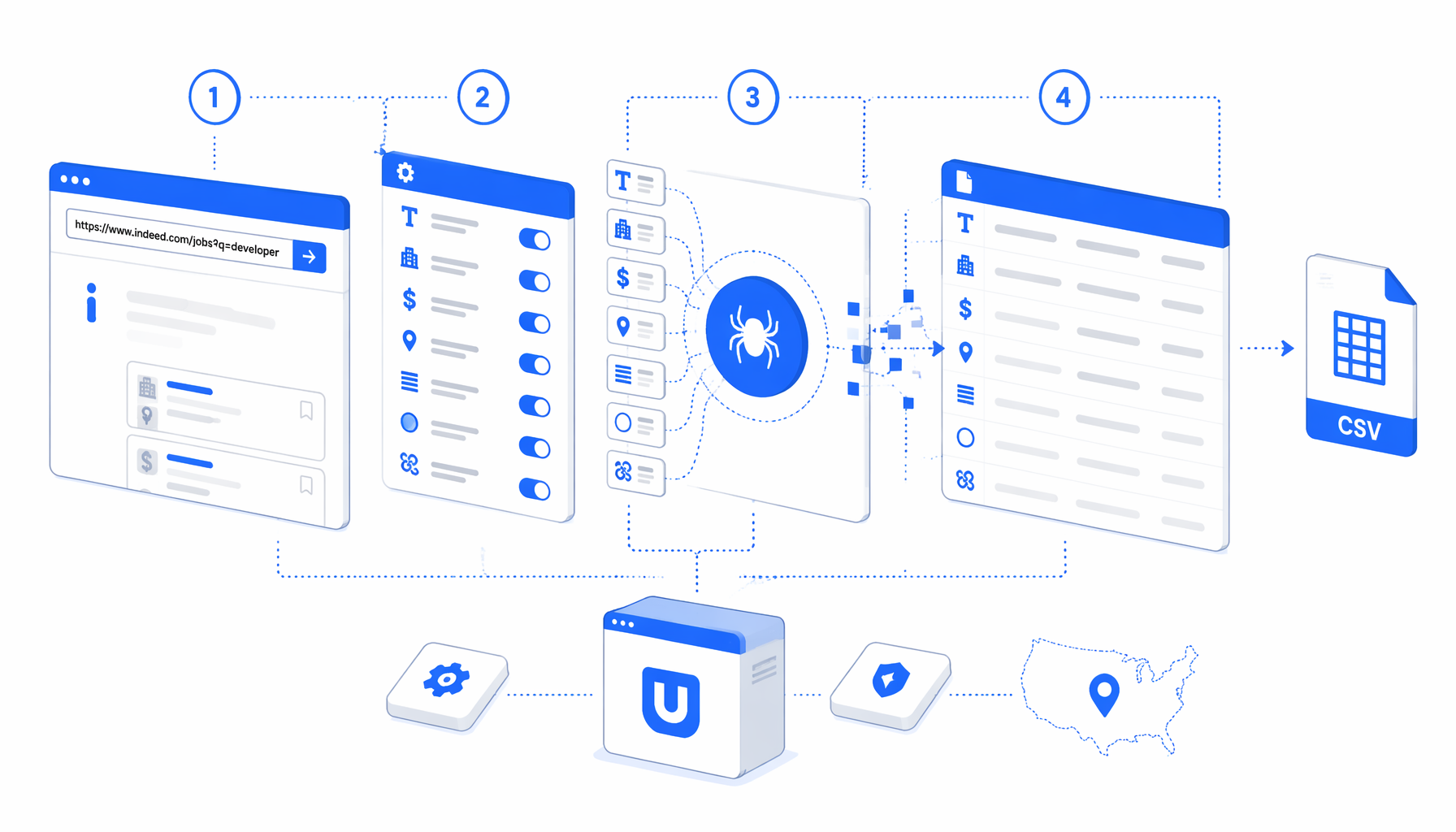
This tutorial shows how to scrape Indeed jobs by URL into CSV with the Indeed Job Scraper by URL template for UScraper. You will prepare direct job links, import the workflow, set the export path, run a small validation batch, and audit verification rows before using the data.
Before you start
Prerequisites, URL list, and policy checks
You need UScraper installed as a local desktop app, a small list of reviewed Indeed job-detail URLs, and a folder where CSV exports can be saved. Start with five to ten links from a shortlist, job alert, internal tracker, or manual Indeed search. Direct URLs are best when you already know the roles you want to inspect and need the full detail page rather than a broad search-results scrape.
This URL-based flow is useful for recruiting research, salary snapshots, competitor hiring reviews, part time jobs analysis, seasonal jobs checks, weekend jobs tracking, and job-board QA. It is not a license to collect every listing you can reach. Review the current Indeed Partner Docs, Indeed API guides, Indeed legal policies, and robots.txt before automating collection.
Browser visibility is not the same as permission to automate, store, resell, republish, or train models on job data. If Indeed shows verification, login, CAPTCHA, or access-denied screens, pause the run instead of trying to force through the control.
Workflow anatomy
What the Indeed job scraper by URL does
The template is intentionally narrow: it processes a list of supplied job URLs and writes one CSV row for each input. That makes it a better fit for curated job details than keyword discovery. If you need search-page pagination first, use the broader Indeed Job Scraper tutorial, then feed selected job URLs into this URL-based template.
The JSON workflow is the source of truth. It starts with a multi-URL Navigate block, waits for the page body, sleeps briefly so page content can settle, checks for "Additional Verification Required", then routes the run into one of two JavaScript branches. Normal pages are parsed into job fields. Challenge pages produce a diagnostic row so you can see exactly which URL failed.
| Block group | What it does | What to verify |
|---|---|---|
| Page Load | Opens each URL, waits for page load, waits for body, then pauses briefly | The page is a job detail page, not a login, block, or verification screen. |
| Verification check | Looks for additional verification text in the page body | Diagnostic rows are expected when Indeed blocks a URL. |
| Data extraction | Reads JobPosting JSON-LD first, then known Indeed selectors | Title, company, location, salary, and description match the browser. |
| Structured Export | Appends one row to indeed_job_scraper_by_url.csv | Headers, append mode, and local save folder are correct. |
| Loop Continue | Advances to the next input URL | One input URL should produce one row. |
Export shape from the workflow definition
There is no bundled CSV sample for this template, so use the JSON workflow and your first dry run together. The export block includes headers, uses append mode, and writes the following 20 columns.
indeed_job_scraper_by_url.csvColumn
Site
Source site context.
Column
Search_Term
Empty for URL-only batches unless you add one.
Column
Search_Location
Empty for URL-only batches unless you add one.
Column
URL_Input
The original URL supplied to Navigate.
Column
Total_Result
Reserved for search-result context or diagnostics.
Column
Job_Title
Job title from JSON-LD or the page header.
Column
Job_ID
Indeed job key, usually from the jk parameter.
Column
Job_URL
Canonical viewjob URL when a job ID is present.
Column
Job_Type
Full-time, part-time, contract, temporary, or similar text.
Column
Salary
Visible salary or baseSalary value.
Column
Location
Job location from structured data or page text.
Column
Full_Description
Cleaned job description or verification diagnostic.
Column
Company_Name
Hiring organization name.
Column
Company_URL
Company profile or sameAs URL when visible.
Column
Company_Rating
Visible rating, when present.
Column
Company_Review_Count
Visible review count, when present.
Column
Posted_Date
Posted date from structured data when available.
Column
isExpired
True when the page appears expired.
Column
Valid_Through
JobPosting validThrough value when available.
Column
Apply_Link
First likely apply link found on the page.
The imported workflow should look roughly like this:
{
"project": {
"name": "Indeed Job Scraper by URL",
"description": "Processes every URL in navigate.urls[] and appends one row per input URL."
},
"blocks": [
{ "title": "Navigate", "config": { "urls": ["https://www.indeed.com/viewjob?jk=282cd08f13ff1c00"] } },
{ "title": "Text Contains", "config": { "text": "Additional Verification Required", "selector": "body" } },
{ "title": "Structured Export", "config": { "fileName": "indeed_job_scraper_by_url.csv", "fileMode": "append", "includeHeaders": true } },
{ "title": "Loop Continue" }
]
}
Runbook
How to scrape Indeed job details from URLs
Collect approved job URLs
Build a short list of direct Indeed job pages your team is allowed to process. Remove duplicates before importing them.
Import the template
Open Indeed Job Scraper by URL from the Templates library, download the workflow JSON, and import it into UScraper.
Replace the sample URLs
In Navigate, replace the example viewjob links with your reviewed list. Keep the first batch small.
Set the export path
In Structured Export, confirm indeed_job_scraper_by_url.csv, headers, append mode, and a project-specific local folder.
Run and audit
Run the workflow, open the CSV, compare several rows against the browser, and separate verification diagnostics from usable job rows.
Do not scale the run until the first CSV is clean. A good validation pass checks that URL_Input equals the link you supplied, Job_ID matches the jk parameter, Job_URL is normalized, Full_Description is a job description rather than a block message, and Apply_Link points to a real application path.
Common issues and fixes
Indeed returned a verification, Cloudflare, login, or similar challenge instead of the job detail page. Treat the row as a diagnostic. If your use case allows it, rerun from a verified persistent browser profile; otherwise remove that URL or switch to official access.
Validation
Review the CSV before analysis
The fastest review is a three-column audit: URL_Input, Job_Title, and Full_Description. If those fields look right, compare salary, location, company, posted date, expiry status, and apply link for a few rows. For recruiting workflows, add a reviewer column in your spreadsheet so someone can mark "usable", "expired", "blocked", or "needs manual check".
For market research, keep the extraction date next to the file name because job pages change quickly. A useful naming pattern is indeed_job_scraper_by_url_2026-06-25_raw.csv, followed by a reviewed file after filtering diagnostics and duplicates.
FAQ
Is it legal to scrape Indeed job pages by URL?
Indeed job pages may be publicly reachable, but automated collection can still be limited by Indeed terms, robots directives, copyright, privacy rules, and employment-data regulations. Review the current rules, avoid private or login-only data, do not bypass access controls, and get legal review before using exported job data commercially.
Do I need an Indeed API key for this tutorial?
No API key is required for this UScraper workflow. Use official Indeed partner APIs or a licensed data provider when you need contractual access, redistribution rights, production feeds, or service-level guarantees.
What does the Indeed job scraper by URL export?
The output is indeed_job_scraper_by_url.csv with 20 columns: Site, Search_Term, Search_Location, URL_Input, Total_Result, Job_Title, Job_ID, Job_URL, Job_Type, Salary, Location, Full_Description, Company_Name, Company_URL, Company_Rating, Company_Review_Count, Posted_Date, isExpired, Valid_Through, and Apply_Link.
How many Indeed job URLs should I process at once?
Start with a small approved batch, validate the CSV, then increase slowly. Practical volume depends on page availability, browser session trust, verification prompts, pacing, selector stability, and your compliance policy.
Where should I go next?
Import the Indeed Job Scraper by URL template for the workflow, browse more UScraper templates, or read the blog for related scraping tutorials and comparison guides.