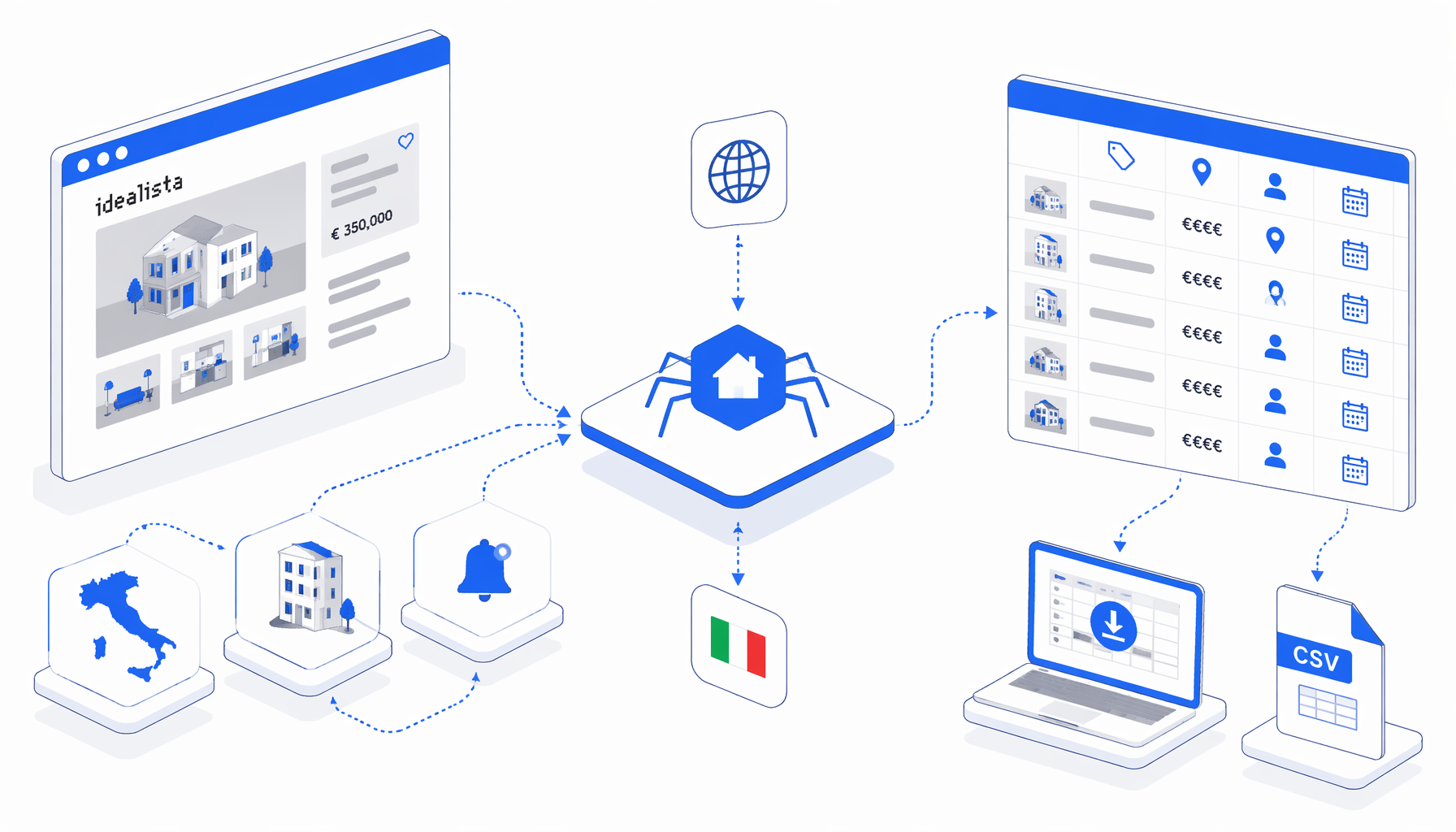
An Idealista Italy scraper is useful when the team needs a clean spreadsheet from selected Idealista.it detail pages, not a full property-data platform. Research teams, newsrooms, SEO teams, agencies, and monitoring analysts can use UScraper's Idealista Detail Scraper Italy template to turn reviewed /immobile/ URLs into local CSV rows.
Problem
Idealista real estate research gets messy in tabs
Idealista.it is easy to browse one property at a time. The friction starts when the same check repeats across twenty detail pages, three cities, or a weekly monitoring list. One analyst copies the price, another records the agency, a third saves the update text, and the final sheet loses its source trail.
The practical problem is not opening Idealista. The practical problem is keeping source URL, price, description, features, advertiser, update text, and observation time together in one reviewable file.
Official routes exist for different jobs. The Idealista Search API access request is for product integrations. idealista/data and its comparables and metrics APIs serve market-intelligence work. This scraper template is narrower: selected browser-visible detail pages, local CSV export, and analyst review.
Personas
Who uses an Idealista property detail scraper?
| Team | Pain | CSV outcome | Example use |
|---|---|---|---|
| Market researchers | Comps are copied by hand. | Price, location, features, agency, and timestamp. | Shortlist Verona rentals for review. |
| Newsrooms | Reporters need traceable examples. | Source URL, facts, update text, and export time. | Support a housing story. |
| SEO teams | Listing language is hard to compare. | Titles, descriptions, location phrases, and agency names. | Audit district and amenity wording. |
| Agencies and monitors | Watchlists change faster than notes. | Repeatable rows for known URLs. | Flag price, wording, or access changes. |
The problem
Manual copying produces inconsistent columns, missing source URLs, and fragile audit trails.
What you do instead
Run a controlled URL list and keep source, fields, and export time together.
Start small, then compare the CSV against the browser.
The problem
A generic scraper can mix search-card data with detail-page data.
What you do instead
Use a detail-page workflow when the job requires description, features, advertiser, and update text.
Use listing pages for discovery, then send selected detail URLs here.
Workflow
How the template delivers structured export
The bundle has no static CSV sample, so use the export shape summary together with the JSON workflow definition. The template sets the browser size, navigates through the URL list, waits for the page, injects a parser, writes columns, and continues to the next URL.
Set Window Size -> Navigate URL list -> Wait for Page Load -> Wait for body
-> Sleep -> Inject JavaScript parser -> Structured Export -> Loop Continue
The JSON export shows the key operational detail: navigate.urls[] holds multiple Idealista.it /immobile/ pages, and Structured Export appends one row per property to crawler-dettagli-immobili-idealista.csv. The parser reads live page fields when accessible and uses fallback records for bundled sample URLs if a DataDome 403 or CAPTCHA page blocks the run.
Output
Idealista real estate data fields for analysis
It is a structured capture layer for fields analysts normally inspect manually.
crawler-dettagli-immobili-idealista.csvColumn
url_inserito
Processed detail URL.
Column
titolo_appartamento
Property title.
Column
prezzo
Visible price.
Column
posizione
Address or area text.
Column
descrizione
Listing description.
Column
caratteristiche_1
First visible feature.
Column
caratteristiche_2
Second feature.
Column
caratteristiche_3
Third feature.
Column
dotazione_1
Amenity when present.
Column
codice_dell_annuncio
Reference or property ID.
Column
professionista
Advertiser or agency.
Column
professionista_url
Advertiser profile URL.
Column
ultimo_aggiornamento
Visible update text.
Column
ora_attuale
Export timestamp.
Use cases
Four concrete Idealista scraping workflows
Comparable property research
A market analyst can collect a small set of Idealista.it detail URLs, export price, location, features, advertiser, and update text, then sort the CSV before review. This helps comp shortlists; official reports such as the Idealista annual residential market report for Italy are better for market-level trends.
Newsroom and policy reporting
Newsrooms often need traceable examples. A data desk can keep source URL, export time, title, price, advertiser, description, and update text together before a reporter writes from the row.
SEO and listing-language audits
SEO teams can compare how agencies phrase neighborhoods, renovations, floor area, contract terms, and amenities. A small CSV reveals repeated wording patterns faster than browser review.
Recurring watchlist monitoring
Agencies and researchers can maintain a watchlist of known URLs and rerun it. Append mode helps, but use dated files or dedupe by url_inserito and ora_attuale.
Decision
Idealista API alternative vs scraper workflow
| Route | Best fit | Trade-off |
|---|---|---|
| Official Idealista API access | Approved product or backend integration. | Requires access request and setup. |
| idealista/data products | Licensed comparables, metrics, and studies. | Better for market intelligence than page review. |
| Hosted scrapers such as Octoparse or Apify | Cloud runs, schedules, datasets, or API delivery. | Rows and logs run through a vendor platform. |
| Bright Data or scraper APIs | Vendor-delivered datasets or API JSON. | Less transparent for analysts. |
| UScraper Italy detail template | Selected Idealista.it detail URLs, visible local workflow, and CSV output. | Best for controlled research batches, not unattended high-volume crawling. |
Use official or licensed routes for permission, redistribution, or production reliability. Use UScraper for a reviewed URL list and an inspectable spreadsheet.
Compliance
Access, legality, and quality checks
Public browser visibility is not permission. Review Idealista terms, robots directives, database rights, copyright, privacy obligations, and local real estate rules. The CNIL guidance on web-scraping data collection highlights legal-basis and impact-reduction duties. AWS also publishes ethical web crawler best practices.
Use it when analysts, newsrooms, SEO teams, agencies, or monitors have reviewed Idealista.it detail URLs and need repeatable CSV output.
Next step
Start with the Idealista detail scraper Italy template
Open Idealista Detail Scraper Italy for Property Pages, replace the sample /immobile/ URLs, and validate three rows. For setup, read the tutorial. For trade-offs, compare scraper alternatives, browse templates, or return to the blog.