This tutorial shows how to scrape Idealista property detail pages in Italy into CSV with the Idealista Detail Scraper Italy template. You will import the workflow, replace the sample /immobile/ URLs, validate the export, and decide when official API access is a better fit.
Before you start
Prerequisites for an Idealista property scraper
You need UScraper installed as a local desktop app, the Idealista Detail Scraper Italy template, and a short list of Idealista.it property detail URLs you are allowed to process. The workflow is built for detail pages such as https://www.idealista.it/immobile/28853110/, not broad keyword crawling or map exploration.
Review Idealista terms, robots directives, privacy obligations, database rights, and your internal data-use policy before automation. Official Idealista routes exist too: the Idealista Search API access request is meant for teams that need approved property-data integration, while the Italian Idealista/data API overview describes comparable and market-metric data products.
Technical access is not permission. Keep batches modest, collect only fields you need, stop when an access challenge appears, and use official or partner routes when you need stable rights to redistribute data.
Workflow shape
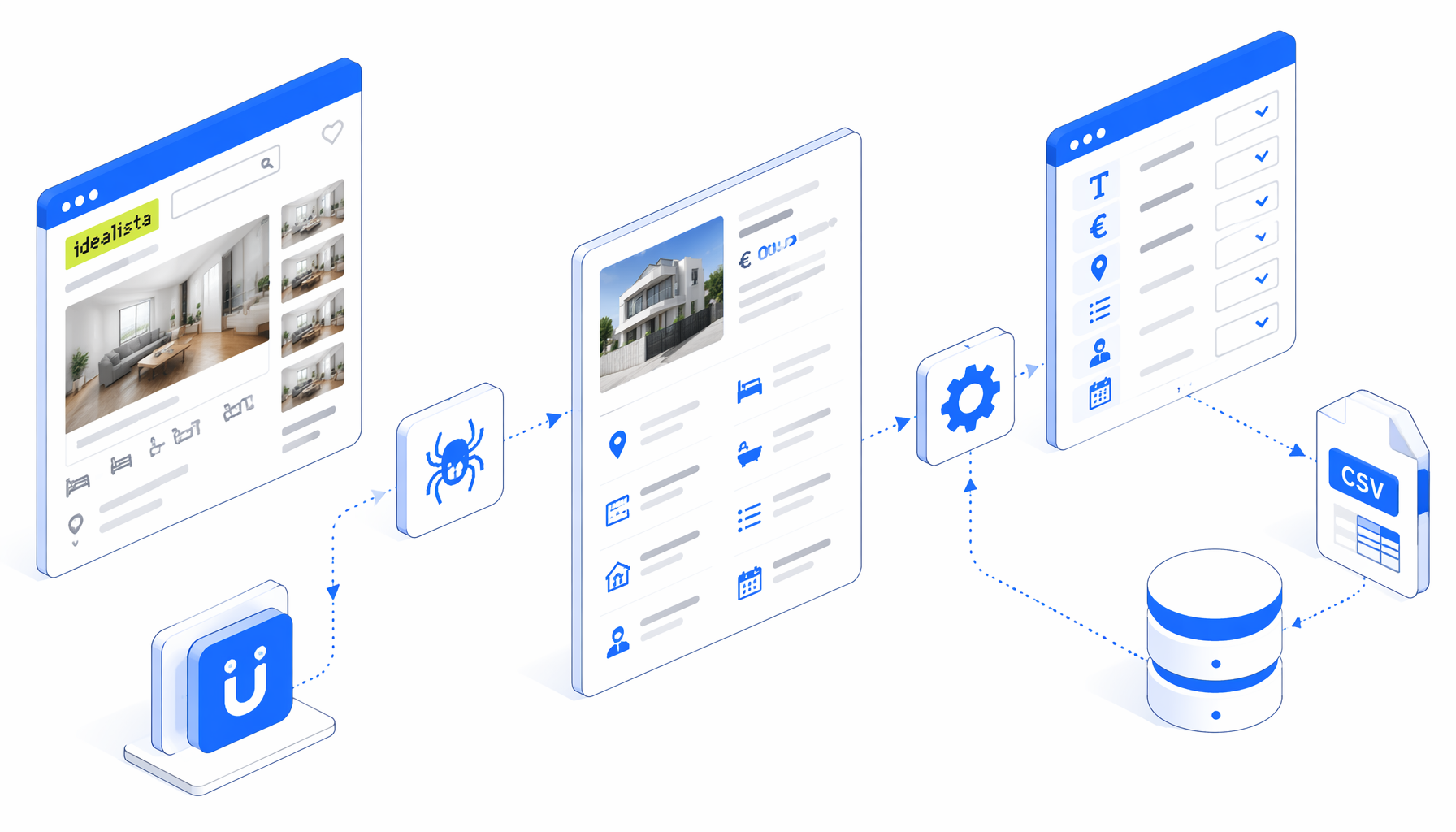
How the Idealista detail workflow works
The JSON export is the authoritative workflow definition. It sets a browser size, navigates through navigate.urls[], waits for the page body, injects a parser, exports columns, and continues to the next URL.
| Workflow block | Purpose | Validation check |
|---|---|---|
| Set Window Size | Stabilizes the viewport | Keep it unchanged during QA. |
| Navigate | Stores the /immobile/ URL list | Replace sample URLs. |
| Waits | Lets the listing render | Stop on challenge or error pages. |
| Inject JavaScript | Reads property fields | Compare against the browser. |
| Structured Export | Appends CSV columns | Check filename and folder. |
| Loop Continue | Advances the URL list | One row should map to one URL. |
The template notes that live testing saw an Idealista DataDome 403 or CAPTCHA interstitial. When a page is accessible, the parser reads the live DOM. When a bundled sample URL is blocked, fallback sample data helps you inspect the export shape. Treat fallback or blank rows as QA warnings, not market data.
Runbook
How to scrape Idealista property details to CSV
Replace sample URLs
Replace the bundled Verona sample links with approved Idealista.it /immobile/ detail pages.
Confirm page access
Continue only when the real listing renders, not a CAPTCHA, error, login, or device-check page.
Set the CSV destination
Confirm crawler-dettagli-immobili-idealista.csv, headers, append mode, and a project folder.
Run and compare
Compare title, price, location, description, features, advertiser, profile URL, and update text.
Scale after QA
Extend the URL list only after blank fields, fallback rows, and access prompts are understood.
Because file mode is append, reruns add rows to the same CSV. Use a dated folder or clear the file before repeating a URL list.
Output
CSV output fields from Idealista detail pages
The bundle does not include a static CSV sample. Use the export shape below together with the JSON workflow: the JSON controls the parser, while your first validation run proves the fields still match today's page layout.
crawler-dettagli-immobili-idealista.csvColumn
url_inserito
Processed detail URL.
Column
titolo_appartamento
Property title.
Column
prezzo
Displayed price text.
Column
posizione
Address and area text.
Column
descrizione
Listing description.
Column
caratteristiche_1
Feature such as size or rooms.
Column
dotazione_1
Amenity when present.
Column
professionista
Advertiser or agency.
Column
ultimo_aggiornamento
Visible update text.
Tool choice
Idealista API alternative vs scraper tools
Searches for idealista api alternative, best Idealista scraper tools, and Octoparse Idealista alternative usually ask one question: do you need a spreadsheet today, or a governed data integration?
Use UScraper for selected Idealista.it detail URLs, local CSV output, analyst QA, and no-code workflow editing.
For this tutorial, the wedge is local CSV export from selected Italian detail pages. That keeps access, selectors, and data quality inspectable.
Troubleshooting
Common issues when scraping Idealista in Italy
| Symptom | Likely cause | Fix |
|---|---|---|
| Blank title or price | Expected listing markup did not render | Inspect one URL, then adjust waits or selectors. |
| CAPTCHA or 403 page | Idealista access controls triggered | Stop the batch and use approved access. |
| Repeated rows | The same URL was supplied twice or append-mode test rows remained | Dedupe by url_inserito and clear the CSV before reruns. |
| Agency URL missing | The advertiser link was hidden or markup changed | Treat it as optional, then test several pages. |
FAQ
Idealista scraper FAQ
Idealista detail pages may be visible in a browser, but automated collection can still be restricted by terms, robots directives, database rights, privacy law, real estate rules, and anti-abuse systems. Review the rules, keep runs modest, avoid bypassing controls, and get legal review before commercial reuse.
Next step
Download the Idealista detail scraper Italy template
Use Idealista Detail Scraper Italy as the download path, then keep this tutorial open while you validate the first CSV. For adjacent workflows, browse all UScraper templates or return to the UScraper blog.