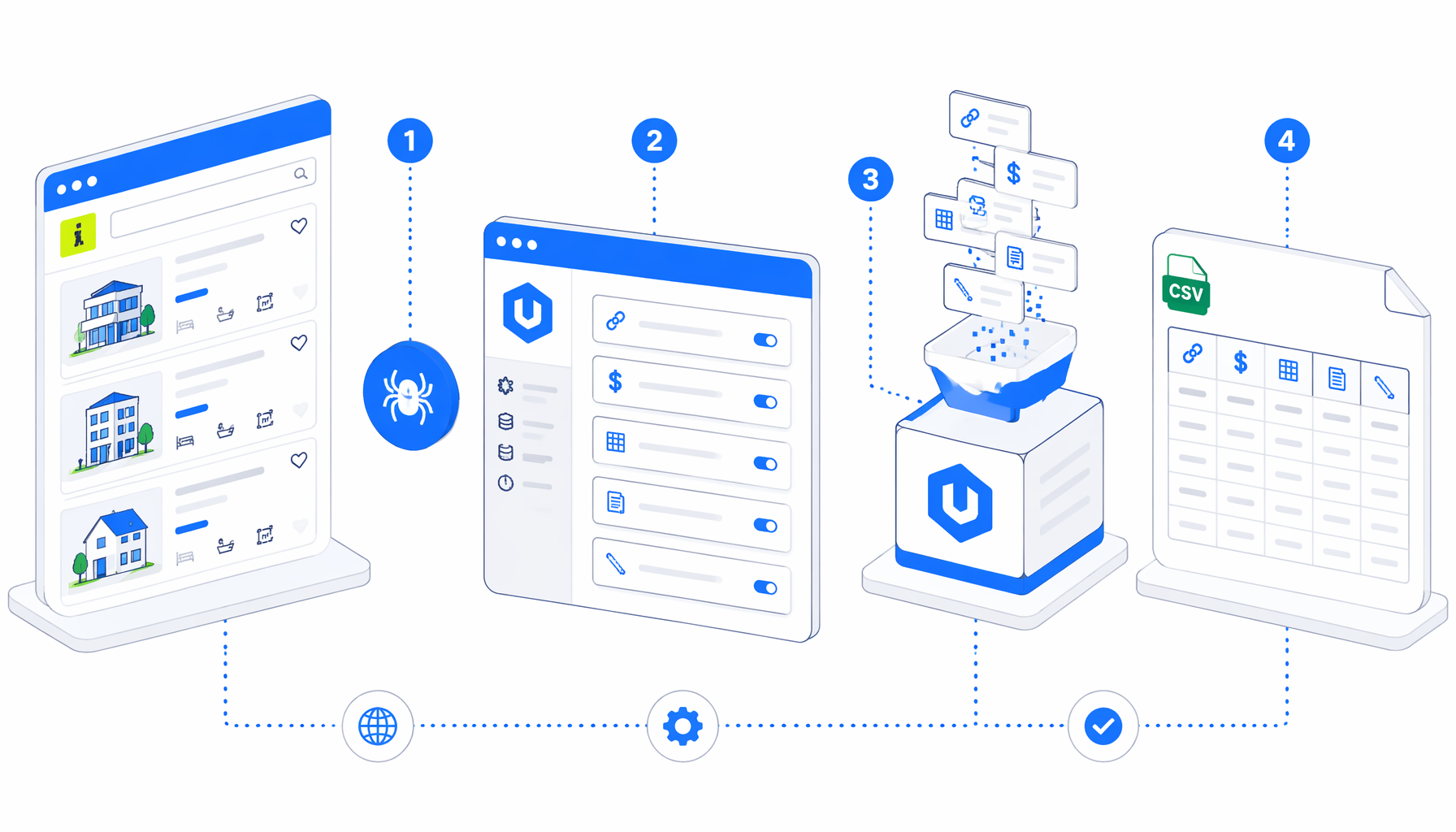
This Idealista scraper tutorial shows how to scrape Idealista listing pages into CSV with UScraper's Idealista Listing Pages Scraper. You will import the workflow, replace the sample search URL, set the export path, run one controlled page, and validate the listing rows before collecting a larger real estate dataset.
Before you start
Prerequisites and access checks before you scrape Idealista
You need UScraper installed as a local desktop app, the Idealista Listing Pages Scraper template, a writable local export folder, and an Idealista Spain search results URL you are allowed to process. Build that URL manually first: choose sale or rent, city, neighborhood, property type, price range, and sort order in the browser, then copy the final listing page.
This tutorial covers visible listing cards. It does not cover account dashboards, advertiser portals, private messages, lead forms, CAPTCHA solving, or bypassing blocked pages. If the project needs approved integration, redistribution rights, or stable production delivery, review Idealista's API access request, data products, robots file, and legal statement before choosing scraping.
Technical access is not permission. Keep first runs narrow, document the business reason for each export, and stop when the site returns a verification or blocked state.
Workflow anatomy
Idealista scraper tutorial: what the workflow does
The JSON export is the authoritative workflow definition. In plain English, the flow is:
Navigate -> Wait for Page Load -> accept consent if present -> Sleep
-> check article.item -> Structured Export -> check next page
-> Click next -> wait -> check article.item -> repeat or end
The stock Navigate block uses an example Barcelona sales URL. Structured Export uses article.item as the row selector and appends one CSV row per listing card. The next-page step looks for common Idealista pagination selectors, clicks the link, waits for the page to settle, and loops back into the same export step.
The most important part is the false branch. If no article.item rows exist, the workflow ends instead of writing misleading blank output. That can happen because the page is empty, filters returned no properties, the selector changed, or Idealista returned DataDome, CAPTCHA, HTTP 403, or another access-control page.
{
"project": {
"name": "Idealista Listing Pages Scraper",
"description": "Scrapes Idealista Spain listing pages for property title, listing URL, price, characteristics, description, and address/location text."
},
"structuredExport": {
"rowSelector": "article.item",
"fileName": "idealista-listados-scraper.csv",
"fileMode": "append",
"columns": [
"url_ingresada",
"titulo",
"url",
"precio",
"caracteristica_1",
"caracteristica_2",
"caracteristica_3",
"descripcion",
"direccion_o_zona"
]
}
}
idealista-listados-scraper.csvColumn
url_ingresada
The Idealista results page URL being processed.
Column
titulo
Visible title from the listing card.
Column
url
Detail-page link for manual review or a follow-up details scraper.
Column
precio
Displayed price text exactly as shown in the card.
Column
caracteristica_1
First visible feature chip, such as bedrooms or area.
Column
caracteristica_2
Second visible feature chip when available.
Column
caracteristica_3
Third visible feature chip when available.
Column
descripcion
Short listing description from the results page.
Column
direccion_o_zona
Address or zone text derived from the listing title.
Best for analyst-led CSV work, visible browser validation, quick selector edits, and a local file that can be opened in a spreadsheet before anyone trusts the data.
Runbook
How to scrape Idealista listing pages to CSV
Import the template
Open Idealista Listing Pages Scraper from the template library, download the JSON workflow, and import it into UScraper.
Create a focused search URL
In Idealista, set the market, location, filters, sort order, and language. Copy the final results URL only after the page shows the listing cards you want.
Replace the sample URL
Open the Navigate block and replace the Barcelona sample with your filtered URL. Keep one URL during the first test so errors are easy to trace.
Confirm browser access
Open the same URL in the browser session UScraper uses. Resolve normal consent prompts manually, and stop if the page shows DataDome, CAPTCHA, login, or HTTP 403.
Set the export path
In Structured Export, confirm idealista-listados-scraper.csv, headers enabled, append mode, and a clean local folder for the project or city.
Run one page and compare
Run the first page, open the CSV, and compare title, detail URL, price, feature chips, description, and address or zone text against the browser.
Validate the Idealista CSV export
The bundle does not include a CSV sample, so treat the configured export shape and one-page browser comparison as the contract. A healthy row should include a meaningful title, detail URL, price, and source page URL. Feature chips, description, and zone text can vary by listing type and market.
| Symptom | Likely cause | Fix |
|---|---|---|
| Zero rows exported | No article.item rows rendered or the page was blocked | Inspect the browser tab, slow down the run, and confirm access before rerunning. |
| Repeated rows | The CSV was appended across multiple tests | Dedupe by url and clear old test rows before the final run. |
| Blank feature columns | The card exposes fewer than three feature chips | Treat blanks as normal unless the browser visibly shows the missing field. |
| Wrong area text | The title pattern changed or the address was not embedded in the title | Validate several listings and adjust the derived direccion_o_zona logic if needed. |
| Pagination stops early | The next link disappeared, changed, or loaded into a blocked state | Compare the final browser page with the source URL and rerun only after access is clear. |
Stop the run and inspect the page manually. The template is designed to exit cleanly when listing rows are not available, not to bypass verification or access controls.
FAQ
Frequently asked questions
Is it legal to scrape Idealista listing pages?
Idealista listing pages may be publicly viewable, but automated collection can still be restricted by Idealista terms, robots directives, database rights, copyright, privacy law, and local real estate rules. Keep runs modest, do not bypass access controls, and get legal review before commercial reuse.
Do I need the Idealista API for this tutorial?
No API key is required for this UScraper workflow because it exports visible listing-card fields from rendered results pages. Use Idealista API access or licensed data products when you need approved integration, contractual usage rights, redistribution, or production service levels.
What does the Idealista listing pages scraper export?
The workflow writes idealista-listados-scraper.csv with url_ingresada, titulo, url, precio, caracteristica_1, caracteristica_2, caracteristica_3, descripcion, and direccion_o_zona columns.
Why did Idealista return DataDome, CAPTCHA, or HTTP 403?
Those states mean the current browser session, network, pacing, or request was not allowed to reach normal listing rows. The template checks for article.item before export and exits cleanly when rows are unavailable; inspect the page manually and do not automate around access controls.
How many Idealista listing rows can I scrape?
The workflow exports every listing row found on reachable results pages and follows the next-page link until pagination ends or listing rows disappear. Practical row counts depend on filters, page availability, pacing, anti-bot checks, and selector maintenance.
Next steps
Use Idealista Listing Pages Scraper as the download path for this tutorial. After the listing CSV is clean, pass selected URLs into the Idealista Details Scraper, browse more real estate workflows in the UScraper templates library, or keep the UScraper blog open for adjacent no-code scraping guides.