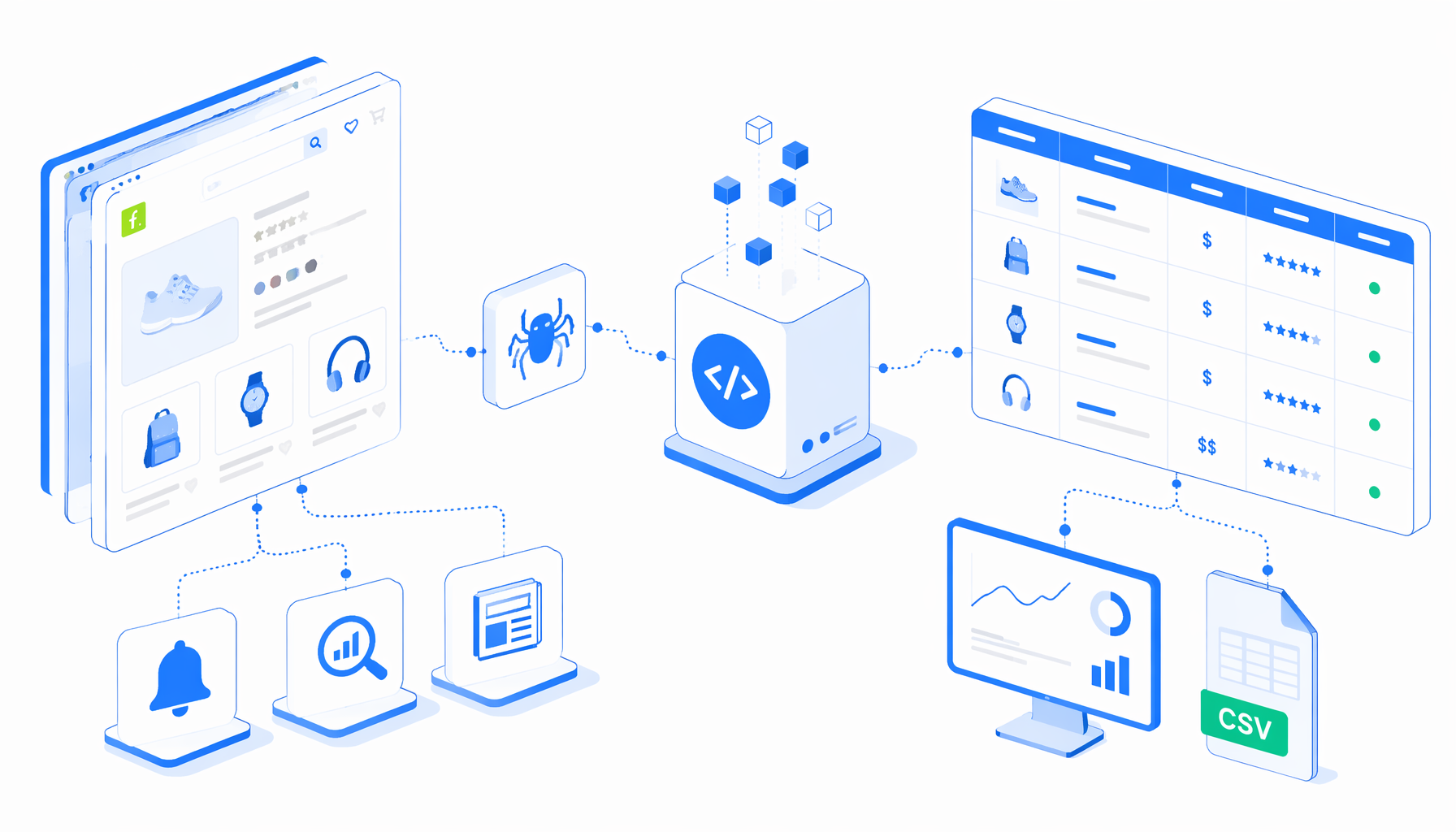
A Falabella product details scraper is most useful when the question is not "can we collect everything?" but "can this team turn reviewed product URLs into a clean CSV we can defend?" The Falabella Product Details Scraper supports that use case: open known product pages, extract identity, prices, images, ratings, and specifications, then export one row per URL.
CSV
19
URL list
Falabella
Local
Problem
Why Falabella product data is hard to use manually
Falabella product pages are built for shoppers, not spreadsheets. Product titles, codes, price blocks, ratings, image carousels, and specifications sit in different page modules. Some fields are category-specific: furniture, fashion, and electronics pages do not expose the same labels. Copying those fields by hand creates a file that is slow to build and hard to audit.
The risk gets worse with Falabella price monitoring. A pasted price without source URL, run date, country storefront, and page context is easy to misread later. Was it a sale price, current price, original price, add-on service price, or recommendation widget price? A useful scraper workflow should preserve the row-level evidence, not just the number.
A retail price snapshot is only useful when the team can explain where the row came from and what the browser showed during collection.
Personas
Who uses a Falabella product details scraper?
| Persona | Pain | Useful CSV outcome |
|---|---|---|
| Retail analysts | Weekly checks across selected products become browser-tab chaos. | Compare precio_rebaja, precio_actual, precio_original, brand, and product URL across dated snapshots. |
| SEO and content teams | Product pages and category briefs need entity details without manual copying. | Export brand, title, image URLs, type, size, gender, and especificacion for briefs and enrichment. |
| Newsrooms | Pricing claims or marketplace examples need a documented sample. | Keep source URL, product code, visible price fields, ratings, and review count in one auditable spreadsheet. |
| Marketplace researchers | Competitor or category scans need normalized product rows. | Join product codes, titles, brands, images, and specs after a listing workflow has found the detail URLs. |
| Agencies | Client reports need repeatable evidence instead of screenshots only. | Save the URL list, run date, CSV, and notes so the work can be reviewed later. |
That is the difference between how to scrape Falabella products as a trick and using a scraper as a controlled research workflow with inputs, output fields, QA rules, and stop conditions.
Workflow
How the template turns product URLs into rows
The JSON workflow is the source of truth. In plain language, the graph follows this pattern:
Set Window Size -> Navigate -> Wait for Page Load -> Sleep
-> Wait for Element -> Inject JavaScript -> Structured Export
-> Loop Continue -> End
Navigate holds the product detail URLs. The wait blocks give the page time to load visible text, product JSON, price areas, and images. The JavaScript block normalizes the page into window.__uscraperFalabellaProduct, then Structured Export appends those values into CSV. Loop Continue advances to the next URL.
falabella-retail-detalles-scraper.csvColumn
codigo
Product code from the URL path.
Column
codigo_tienda
Store or seller code fallback when available.
Column
marca
Brand from structured product data or page text.
Column
titulo
Clean product title.
Column
precio_rebaja
Sale or offer price near the purchase area.
Column
precio_actual
Comparable current price when a higher price is visible.
Column
precio_original
Original or list price when available.
Column
producto_url
The visited product detail URL.
Column
rating
Rating value when rendered.
Column
comentario
Review or comment count when exposed.
Column
imagen1
Primary product image URL.
Column
imagen2
Secondary image URL when available.
Column
imagen3
Additional image URL when available.
Column
imagen4
Additional image URL when available.
Column
imagen5
Additional image URL when available.
Column
tamano
Size, capacity, or seating field when present.
Column
tipo
Product type from specifications.
Column
genero
Gender field for applicable categories.
Column
especificacion
Cleaned specification block.
Use cases
Concrete Falabella scraper use cases
Retail pricing team
Weekly price monitoring
Keep a fixed URL set and compare price fields across dated CSV files. Treat blank or unusual prices as QA events, not zeroes.
SEO team
Product and category research
Export product titles, brands, images, types, and specifications into a sheet before writing content briefs, category pages, or comparison notes.
Newsroom or analyst
Evidence gathering
Capture a controlled product sample, then keep the URL list, run date, CSV, and screenshots together for editorial review.
Price monitoring without losing context
For recurring Falabella price monitoring, consistency matters more than volume. Use the same URLs, country storefront, run window, and CSV naming convention. Keep append mode for exploration, but save dated files for comparisons.
SEO and catalog enrichment
SEO teams often need more than a title and price. Image URLs, brand, type, size fields, and cleaned specifications help with entity matching, category briefs, product copy audits, and content gap analysis.
Newsroom and research checks
Journalists and researchers should treat the CSV as a starting artifact, not the full evidence package. Pair exported rows with screenshots, collection notes, and source policy review.
Decision
Falabella API vs scraper vs hosted tools
There is no universal best Falabella scraper. The right route depends on permission, scale, custody, and output format.
| Route | Best fit | Trade-off |
|---|---|---|
| Official Falabella Seller Center API | Approved seller workflows, authenticated catalog operations, and system integration | Requires API access and should be used when you need sanctioned seller-side operations. |
| Hosted scraper platforms | Cloud scheduling, API delivery, large recurring collection, and managed infrastructure | Data custody, pricing units, and output schemas depend on the vendor. |
| Custom Python or browser scripts | Engineering-owned pipelines with tests, logging, queues, and databases | Highest control, highest maintenance burden. |
| UScraper template | Supervised local CSV export from a controlled product URL list | Best for analyst-led batches, not unattended fleet-scale collection. |
If you are deciding Falabella API vs scraper, start with the job. Use the Falabella developer portal and API reference for approved Seller Center operations. Use UScraper for visible product URLs, a modest research batch, and a local CSV teammates can inspect.
Runbook
A practical workflow for teams
Define the question
Decide whether the job is price monitoring, catalog enrichment, SEO research, newsroom sampling, or client reporting. The question decides the URL list and QA checks.
Prepare product URLs
Use reviewed detail URLs only. Remove tracking parameters when they are not needed and keep the input list beside the final CSV.
Run a short batch
Start with two or three products. Compare code, brand, title, prices, images, and specifications against the browser before widening the run.
Version the output
Save the CSV with the run date, country storefront, project, and any workflow edits. Do not mix test rows with production snapshots.
Link the next analysis step
Open the CSV in Excel, Sheets, Power Query, BI tooling, or your internal QA file. Deduplicate by producto_url, codigo, or both.
For implementation details, use the companion how-to guide. For tool selection, compare options in the Falabella scraper alternatives guide or browse more articles in the UScraper blog.
FAQ
Falabella product scraper FAQ
Use it when analysts, SEO teams, journalists, marketplace researchers, or agencies have approved product URLs and need a structured CSV for comparison, QA, monitoring, or reporting.
Next step
Start with the Falabella Product Details Scraper
Use this workflow when your team has a defined product URL list and needs a structured CSV for monitoring, SEO research, newsroom checks, or client reporting. Download the Falabella Product Details Scraper, run a small validation batch, then expand only after the CSV matches the visible product pages.