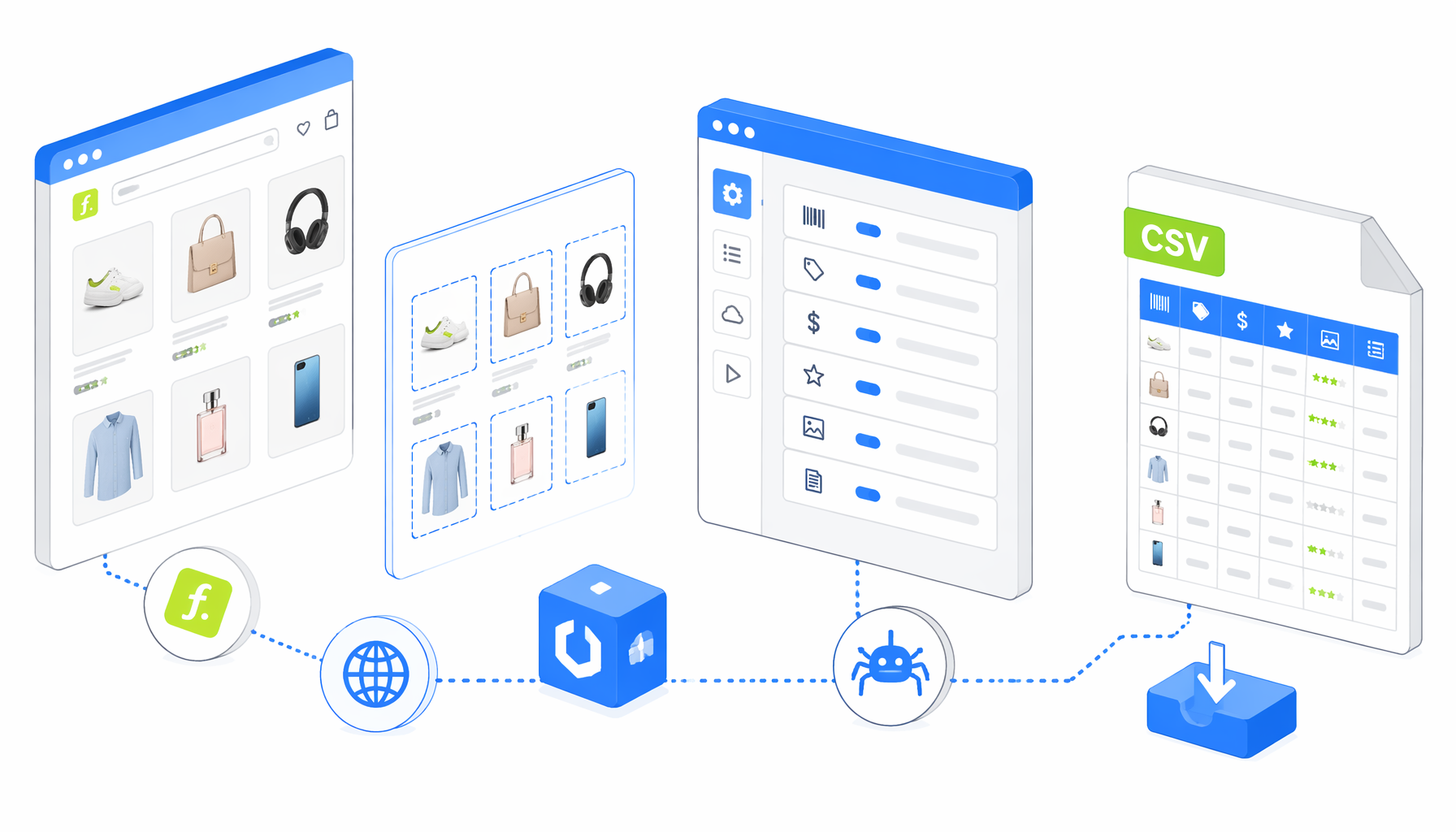
This tutorial shows how to scrape Falabella product details from known product URLs into CSV with the Falabella Product Details Scraper for UScraper. You will import the workflow, replace the sample URL list, set the export path, run a small batch, and validate product codes, brand, title, price tiers, ratings, image URLs, and cleaned specifications.
Before you start
Prerequisites, scope, and policy checks
You need UScraper installed as a local desktop app, a short list of Falabella product detail URLs you are allowed to process, and a folder for CSV exports. Start with two or three product pages because Falabella pages can differ by country storefront, category, availability, language, cookie prompt, and delivery context.
Use the Falabella Product Details Scraper as the download path for this article. The template page carries the current JSON workflow, block IDs, export columns, hosted import file, and FAQ. This post is the runbook: why each block exists, what to check before a batch, and how to debug common export issues.
This guide covers visible product detail pages only. It does not cover account pages, checkout flows, seller dashboards, CAPTCHA bypassing, or private marketplace data. Falabella also publishes Seller Center API documentation for approved seller workflows; use that route when you own the catalog operation and need an authenticated API contract rather than a browser export.
Treat source access and source permission as separate questions. If Falabella shows verification, login, regional gating, or unusual blank pages, pause the run and review the collection plan instead of forcing automation through it.
Workflow anatomy
What the Falabella product details scraper does
The JSON export is the authoritative workflow definition. In plain English, the flow is:
Set Window Size -> Navigate -> Wait for Page Load -> Sleep
-> Wait for Element -> Inject JavaScript -> Structured Export
-> Loop Continue -> End
The Navigate block owns the product URL list. Replace the bundled Falabella sample URL with the product pages your team has reviewed. The wait blocks give the storefront time to hydrate visible text, structured product data, prices, and images. The JavaScript block cleans text, reads product JSON when available, scopes price extraction near the purchase area, and stores normalized values on window.__uscraperFalabellaProduct.
Structured Export then writes the browser variable into CSV columns. Append mode is enabled, so each successful URL adds one row to the same file.
| CSV field group | Columns | Validation check |
|---|---|---|
| Product identity | codigo, codigo_tienda, marca, titulo, producto_url | Confirm the product code and title match the open Falabella page. |
| Price tiers | precio_rebaja, precio_actual, precio_original | Compare against the purchase area, not recommendation widgets or services. |
| Trust signals | rating, comentario | Expect blanks when reviews or ratings are not rendered for that product. |
| Media | imagen1 through imagen5 | Open one image URL and confirm it belongs to the same product code. |
| Attributes | tamano, tipo, genero, especificacion | Check category-specific fields because furniture, fashion, and electronics expose different labels. |
Runbook
How to scrape Falabella product details to CSV
Import the template
Open Falabella Product Details Scraper, download the JSON workflow, and import it into UScraper.
Replace the sample URL
Edit Navigate and paste the Falabella product detail URLs your team is allowed to collect. Keep one product URL per target row and remove tracking parameters when they are not needed.
Keep the page waits
Leave the page-load wait, four-second sleep, and visible body check in place for the first run. They reduce empty exports from partially hydrated pages.
Set the CSV destination
In Structured Export, confirm falabella-retail-detalles-scraper.csv, headers, append mode, and a project-specific save folder.
Run a small batch
Start with two or three URLs. Watch the browser, handle allowed prompts manually, and compare each exported row with the visible page before widening the input list.
After the first run, open the CSV beside the browser. Sort by producto_url and make sure each input page produced at most one row. If you rerun into the same file, clear the old CSV first or use a dated filename, because append mode will preserve previous test rows.
Output QA
Validate the Falabella CSV before using it
The bundled workflow is designed to create a product research file, not a raw HTML dump. It separates price tiers, captures up to five image URLs, and keeps long specifications in one cleaned cell for spreadsheet review. Still, validation is mandatory because ecommerce pages are dynamic.
| Symptom | Likely cause | Fix |
|---|---|---|
| No row for a URL | Page did not load, prompt interrupted rendering, or the run stopped before Structured Export | Open the URL manually, handle allowed prompts, and rerun one page. |
Blank precio_rebaja | No visible offer price, delayed module, unavailable product, or country-specific layout | Compare the purchase area in the browser and rerun with a longer wait if needed. |
| Incorrect price | A service, recommendation, or unrelated module was read | Keep price extraction scoped near the purchase area and retest with mixed categories. |
| Missing images | Image carousel lazy-loaded late or URL patterns changed | Add a scroll or wait step only after confirming the image appears in the browser. |
| Duplicate rows | Append mode wrote multiple test runs into the same CSV | Clear the file before production runs or dedupe by codigo and producto_url. |
Alternatives
UScraper vs Octoparse, Apify, Python, and APIs
If you are comparing Octoparse Falabella alternatives, Falabella scraper Python projects, or Falabella scraper vs Apify options, decide by custody and maintenance first.
| Approach | Best fit | Trade-off |
|---|---|---|
| UScraper template | Supervised CSV export from a finite product URL list | You maintain waits and selectors when Falabella changes pages. |
| Octoparse-style no-code cloud tools | Hosted workflow templates and non-local execution | Data custody, plan limits, and template behavior depend on the vendor. |
| Apify actors | Cloud scheduling, datasets, APIs, and developer pipelines | Pricing and infrastructure are metered, and output schema varies by actor. |
| Python scraper | Engineering-owned parsing, tests, storage, and retries | Requires code maintenance, monitoring, and anti-bot handling decisions. |
| Official APIs | Approved seller-owned catalog operations | Usually require authorization and may not expose public competitor page data. |
UScraper is strongest when an analyst needs to see the browser, inspect the CSV locally, and make small workflow edits without writing scraper code. Hosted tools are better when cloud scheduling and programmatic datasets matter more than local custody. Python is better when the scraper is part of an owned data platform with tests, logging, and retries.
For adjacent workflows, browse the UScraper template library, the UScraper blog, or pair this details run with a Falabella listing template when you need to build the input URL list first.
FAQ
Falabella product scraper FAQ
Falabella product pages may be visible in a browser, but automated collection can still be limited by source terms, robots directives, anti-bot controls, intellectual property rules, privacy law, and local ecommerce regulations. Review the current rules, avoid bypassing access controls, keep volume modest, and get legal review before commercial reuse.
Next step
Download the Falabella product details scraper
When you are ready to run the tutorial, download the JSON from Falabella Product Details Scraper and keep this article open for QA. Start with a small URL list, confirm the CSV output, then expand only after product code, brand, title, price, images, and specification fields match the browser.