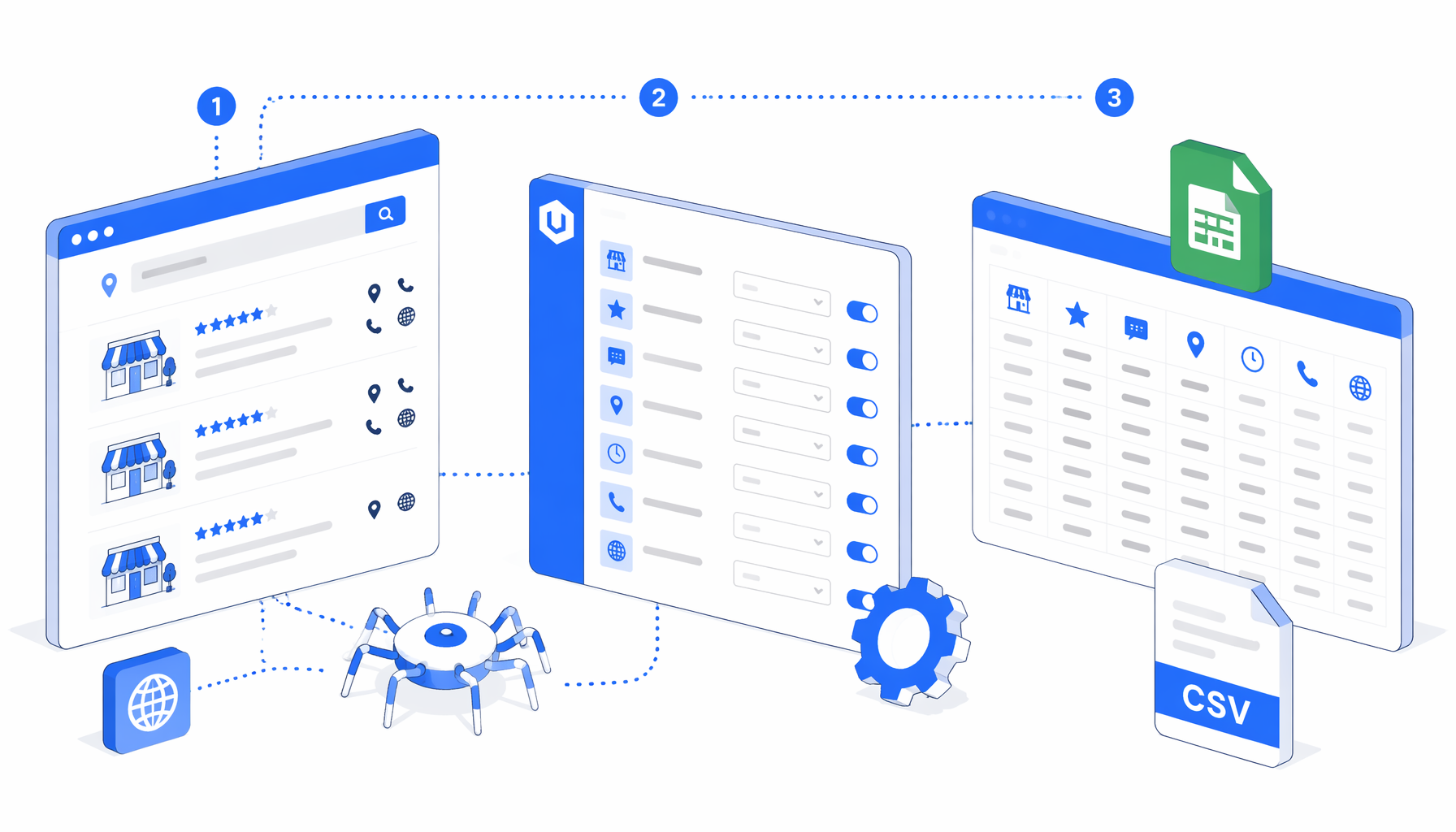
This tutorial shows how to scrape Ekiten store listings from public shop detail URLs into CSV with the Ekiten Store Listing Scraper template for UScraper. You will prepare URLs, import the workflow, set the export path, and validate the first rows.
Before you start
Prerequisites and source checks
You need UScraper installed as a local desktop app, a CSV export folder, and a short list of Ekiten shop detail URLs you are allowed to process. Start with three to seven URLs. A small batch proves that the page loads, the folder is writable, and selectors still match the live layout.
Ekiten is a public Japanese local business directory, but public visibility is not unrestricted reuse. Before automation, review Ekiten's current robots.txt, check applicable terms, and use the Ekiten sitemap as a discovery aid rather than blanket crawl permission.
Treat the first run as a policy and quality check. Do not bypass access controls, do not run high-volume parallel jobs, and keep the source URL list with your exported file.
Workflow
How the Ekiten store listing scraper works
The JSON template is the authoritative workflow definition. In plain English, the flow is:
Navigate -> Wait for Page Load -> Sleep -> Wait for Element
-> Text Contains human-verification check
-> Structured Export from live page or clean fallback sample rows
-> Loop Continue for the next shop URL
The live path opens each configured Ekiten detail URL and appends one row. The fallback path exists because some sessions see verification instead of the shop profile. In that case, the workflow writes clean bundle sample rows with fileMode=create instead of appending broken verification text.
| Workflow stage | What it does | What to verify |
|---|---|---|
| Navigate | Opens each configured Ekiten /shop_ URL | URLs are shop detail pages |
| Page waits | Gives the profile page time to render | Body text, heading, and contact modules are visible |
| Verification check | Looks for human-confirmation text | Challenge pages are not treated as shop data |
| Structured Export | Writes fixed CSV columns | Headers and save folder are correct |
| Loop Continue | Advances through the URL list | One intended row per shop URL is produced |
Runbook
How to scrape Ekiten store listings to CSV
Import the workflow
Open the Ekiten Store Listing Scraper template, download the JSON, and import it into UScraper.
Replace sample URLs
Add public Ekiten /shop_ URLs to Navigate. Keep the first validation batch short so you can inspect every row.
Check the verification branch
Run visibly. If Ekiten asks to confirm you are human, complete only allowed manual steps, reduce volume, and rerun a smaller batch.
Set the export folder
In Structured Export, confirm ekiten-store-listing-scraper.csv, headers, and the local save location for this project.
Validate before scaling
Compare the first CSV rows against the browser, check Japanese text encoding, then add more approved URLs only when the output is clean.
Use a fresh CSV filename for each client, category, or city run.
Output
Ekiten data extraction fields
The export shape comes from the Structured Export columns in the JSON template. Values can be blank when a store omits a field, a module loads differently, the page language changes, or verification interrupts live extraction.
| CSV group | Columns |
|---|---|
| Identity | store_name, detail_page_url, genre, official_site |
| Reputation | rating, review_count, review_url |
| Location | address, access, nearest_stations, bus_stop |
| Operations | today_business_hours, business_hours, price_range, phone_number, parking |
For quality control, sort by detail_page_url. One unique URL should create one row. Then inspect store_name, address, phone_number, and official_site.
Validation
Validate the Ekiten CSV before using it
Open the CSV beside the browser after the first run. Check rows from the start, middle, and end. Keep source URLs in downstream spreadsheets.
| Symptom | Likely cause | Fix |
|---|---|---|
| Verification text appears | Ekiten returned a confirmation page | Stop, reduce volume, and do not bypass controls |
Empty store_name | No visible profile heading loaded | Extend waits and rerun one URL |
| Blank phone or hours | Store omitted the field or markup changed | Inspect the live page before editing selectors |
| Duplicate rows | URL list repeated or old CSV was reused | Use a dated file and dedupe by detail_page_url |
| Garbled Japanese text | Wrong spreadsheet encoding | Import as UTF-8 |
Alternatives
UScraper vs Python, Octoparse, ScrapeStorm, and Apify
Python gives maximum control if your team maintains Selenium, BeautifulSoup, Scrapy, or Crawlee code. Octoparse and ScrapeStorm are useful inside their no-code ecosystems. Apify fits hosted actors and scheduling. UScraper fits visible local CSV work you can inspect before each run.
| Option | Good fit | Trade-off |
|---|---|---|
| UScraper template | Controlled batches, local CSV review, no custom code | Best for supervised collection |
| Python scraper | Full control over selectors and pipelines | More maintenance |
| Octoparse or ScrapeStorm | Teams already using those tools | Different runtime and data handling |
| Apify or cloud crawler | Scheduled jobs and queues | More setup and third-party processing |
Listings vs reviews
Ekiten reviews vs listings
Use this workflow for one row per shop: name, rating, review count, address, access, hours, phone, parking, and official site. Use review extraction when the question is "what did customers say?" For that path, read the companion Ekiten review scraper tutorial. Keep the datasets separate: export listings, dedupe by detail_page_url, then decide which shops justify deeper review collection.
FAQ
Ekiten store listing scraper FAQ
Public business information can still be limited by terms, robots directives, privacy rules, copyright, database rights, and local law. Review policies, keep runs modest, and avoid bypassing controls.
Next step
Download the Ekiten store listing template
Import the free Ekiten Store Listing Scraper for CSV Export and run a small validation batch.