This tutorial shows how to scrape Ekiten reviews from public shop pages into CSV with the Ekiten Review Scraper template for UScraper. You will check source URLs, import the workflow, set the export path, validate a small batch, and troubleshoot "blocked" or "no rows" cases.
Before you start
Prerequisites and source checks
You need UScraper installed as a local desktop app, one or more Ekiten shop URLs, and a folder where the CSV can be written. Start with a known shop page such as https://www.ekiten.jp/shop_1055997/, then add more URLs after the first export matches the browser.
Before scraping, confirm that the shop page and reviews are public, review Ekiten's current robots.txt and applicable terms, and treat the Ekiten sitemap as a discovery aid rather than blanket crawl permission.
Treat this as a controlled research workflow. Do not bypass access controls, do not hammer review pages, and keep a record of the source URLs, run date, and reason for collecting the data.
Workflow
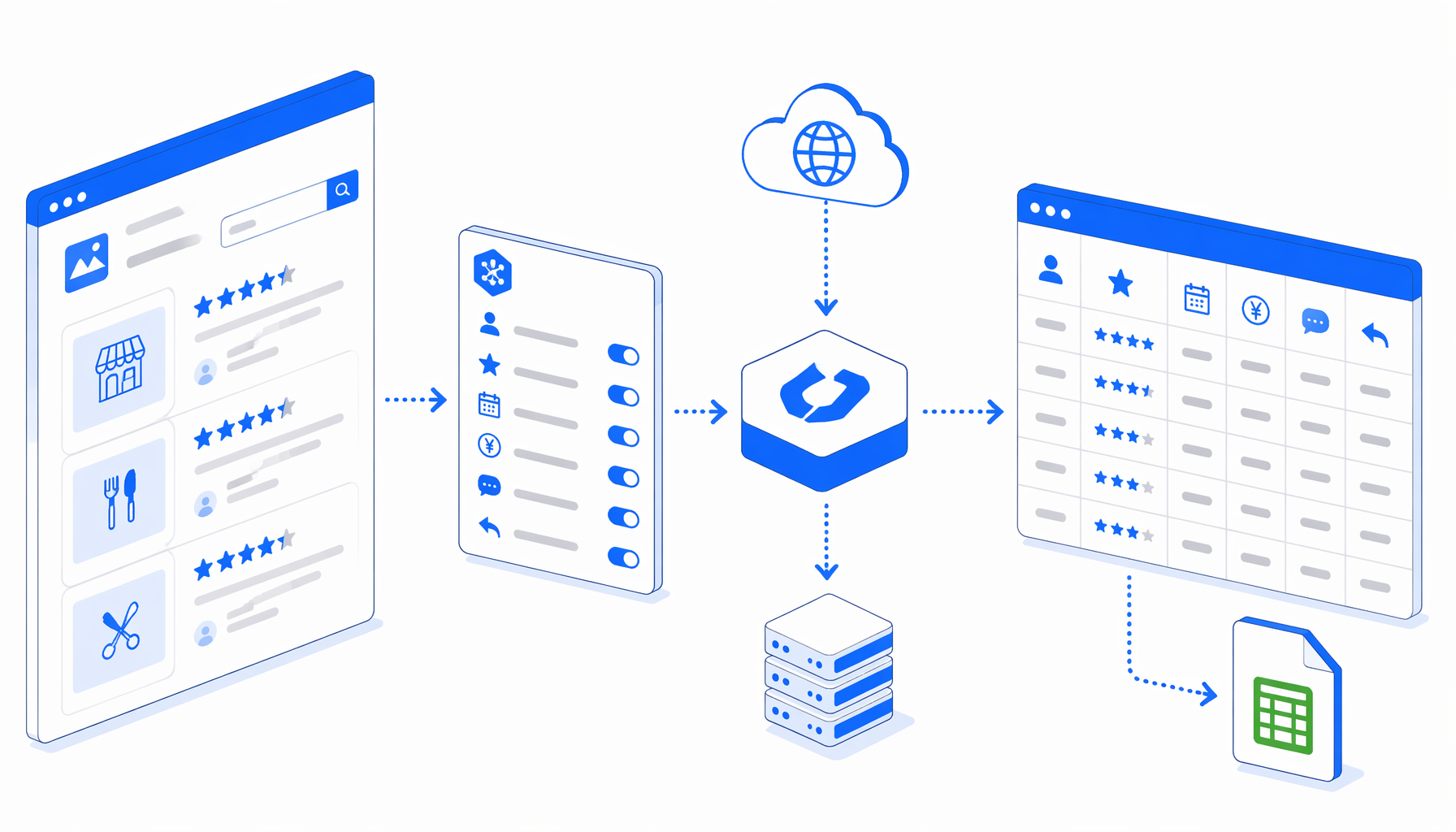
How the Ekiten review scraper works
The template is a best-effort no-code alternative to writing an Ekiten reviews Python scraper from scratch. Its JSON workflow is the authoritative definition: Navigate opens the URL list, Wait blocks let pages render, a human-verification branch handles visible challenge states, JavaScript tags detected review rows, Structured Export writes the CSV, and a pagination loop clicks an enabled next-review control.
You can see the browser state, solve allowed prompts manually, change the output folder, and verify rows beside the live page. It is still automation, so pacing and policy checks matter.
| Workflow stage | What it does | What to verify |
|---|---|---|
| Navigate | Opens each configured Ekiten shop URL | URL starts with the intended public shop page |
| Page load waits | Gives dynamic content time to appear | Heading and review area are visible |
| Verification branch | Detects a human-verification page | Manual step is allowed and completed |
| Review parser | Marks detected rows with data attributes | At least one visible review is represented |
| Structured Export | Appends fixed columns to CSV | Headers, folder, and append mode are correct |
| Pagination loop | Clicks the next-review control when found | No duplicate pages or skipped pages |
Runbook
How to scrape Ekiten reviews to CSV
Import the workflow
Download the related template JSON and import it into UScraper.
Replace sample shop URLs
Add public Ekiten /shop_ URLs in Navigate. Use a short validation list first.
Check verification behavior
Run visibly. If Ekiten asks to confirm you are human, complete only allowed manual steps and continue with a smaller batch.
Set the export folder
Confirm ekiten-review-scraper.csv, headers, append mode, and a project-specific local folder.
Validate before scaling
Compare the first CSV row against the live page, check encoding, then run the remaining approved URLs.
Keep the first pass small. One URL proves that Ekiten loads, rows are detected, and the export folder is writable. Three to five URLs test append mode and pagination.
Output
Ekiten review scraper export fields
The JSON export defines eleven columns. Values can be blank when a field is hidden, the shop has no detected reviews, or verification blocks the session.
ekiten-review-scraper.csvColumn
store_name
Shop name from the page heading.
Column
page_url
Source shop URL for audit and dedupe.
Column
reviewer
Visible reviewer name.
Column
review_title
Review heading or diagnostic code.
Column
rating
Visible numeric score.
Column
posted_date
First detected date.
Column
visit_date
Second detected date when shown.
Column
budget
Visible budget value.
Column
review_text
Review body or diagnostic note.
Column
likes_count
Visible likes or helpful count.
Column
shop_reply
Owner or shop response.
Validation
Validate Ekiten review data before using it
Open the CSV beside the browser and spot-check one row from the beginning, middle, and end. Make sure title, rating, date, budget, review text, and reply match the source page. Keep page_url in downstream files for audits.
| Symptom | Likely cause | Fix |
|---|---|---|
BLOCKED_BY_AWS_WAF_HUMAN_VERIFICATION | Ekiten returned a verification page | Use a visible session, complete allowed manual verification, reduce volume, and rerun |
NO_REVIEW_ROWS_DETECTED | Page loaded, but no rows matched the parser | Check whether reviews moved, the shop has no visible reviews, or markup changed |
| Blank rating or date | Field was hidden or pattern changed | Compare one row against the page and update the parser only for that field |
| Duplicate reviews | URL list or pagination loop repeated a page | Deduplicate by page_url, title, reviewer, and posted date |
| Garbled characters | Spreadsheet opened CSV with the wrong encoding | Import as UTF-8 instead of double-clicking in a default spreadsheet app |
Alternatives
UScraper vs Python, Octoparse, ScrapeStorm, and Apify
Python gives maximum control if you already maintain Selenium, BeautifulSoup, or Scrapy code, but your team owns waits, retries, selector drift, CSV writing, and verification handling. Octoparse and ScrapeStorm style tools are useful no-code options inside their ecosystems, while Apify fits hosted scheduling and actor infrastructure. UScraper is strongest when you want custody and inspection: a local desktop workflow, a CSV in your folder, and visible browser QA before scaling.
FAQ
Ekiten review scraper FAQ
Public review pages can still be governed by terms, robots directives, copyright, privacy law, and local rules. Review current policies, keep batches modest, avoid bypassing access controls, and get legal review before publishing review text.
Next step
Download the Ekiten review scraper template
Download the workflow from Ekiten Review Scraper, run one shop URL, and inspect the CSV before scaling. For adjacent workflows, browse the UScraper template library or read more tutorials on the UScraper blog.