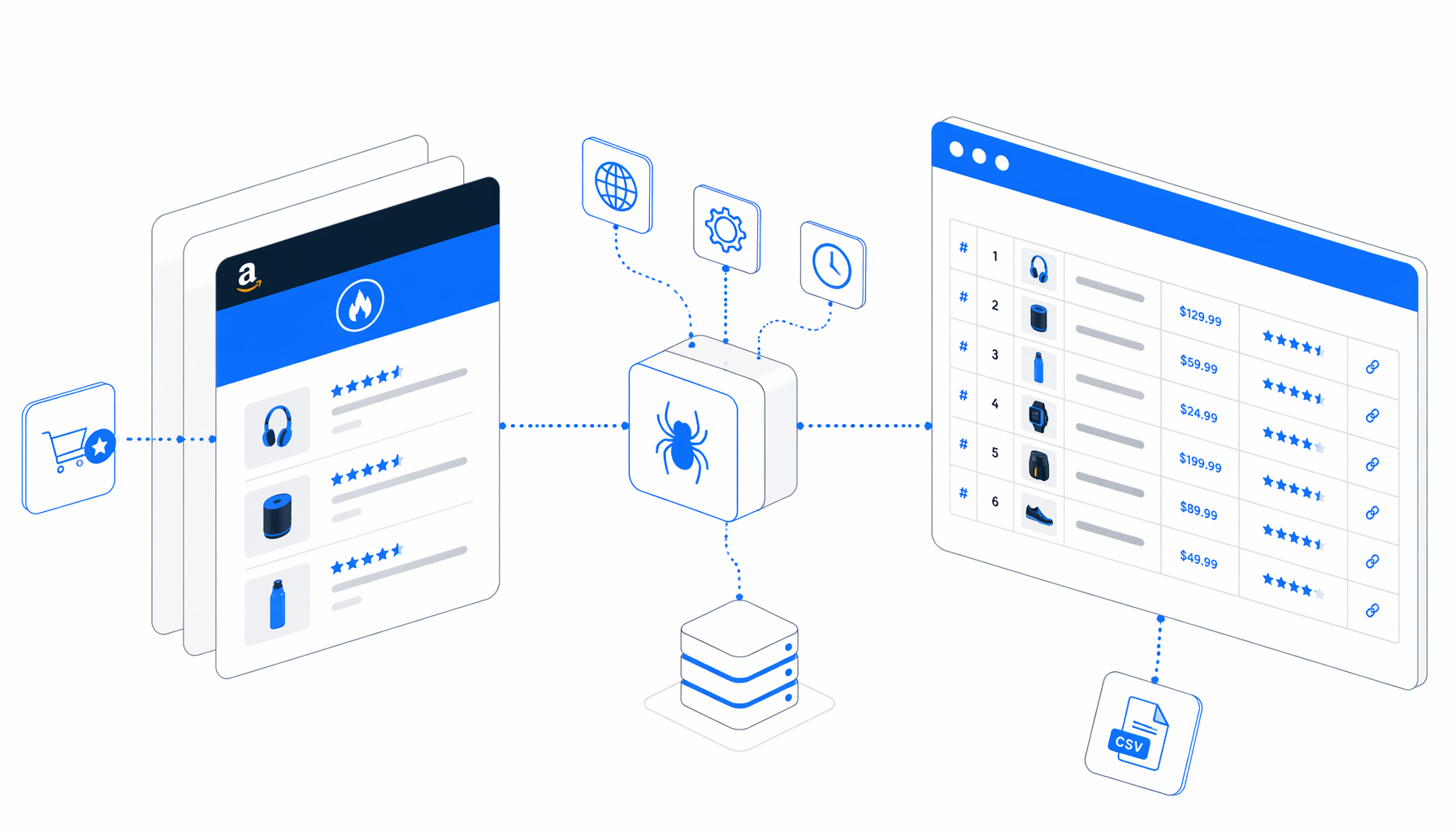
Amazon new releases product research gets messy when it lives in browser tabs. A category page may show rank, ASIN, title, price, rating, review count, image, and platform hints, but those signals are hard to compare by hand. The Amazon Hot New Releases Scraper by Category turns selected category pages into a structured CSV that product teams, researchers, SEO teams, and newsrooms can audit.
Research frame
Why Amazon Hot New Releases matter for product research
Amazon's Hot New Releases pages surface best-selling new and future releases inside departments and subcategories. That makes them useful for early category monitoring before products have long review histories, deep advertising footprints, or obvious bestseller durability.
The trap is treating a ranking page as a demand forecast. Hot New Releases, Best Sellers Rank, ratings, review count, price, availability, and category placement all answer different questions. A useful export keeps those signals separate instead of collapsing them into a vague "winning product" label.
A new-release rank is a lead for investigation, not a sourcing decision. The CSV is valuable because it gives every lead a source URL, category context, and fields you can verify.
Personas
Who uses an Amazon Hot New Releases scraper?
| Persona | Pain | Useful CSV outcome |
|---|---|---|
| Marketplace sellers | Manual category browsing misses launches and makes comparison subjective. | Compare new products by rank, ASIN, title, price, ratings, review count, and visible platform or format. |
| Product researchers | Ideas from Best Sellers lists can be too mature for early trend detection. | Capture category snapshots that point to fresh items worth deeper margin, sourcing, and review analysis. |
| SEO and content teams | Category pages reveal wording, formats, bundles, and attributes that change faster than editorial briefs. | Export product titles, brands, categories, prices, images, and review signals for keyword and page-brief research. |
| Newsrooms | Marketplace ranking claims need evidence that can be checked later. | Preserve source URLs, category names, rank positions, product URLs, review links, and run context for documented samples. |
| Category managers | Launch tracking gets noisy when teams paste product names into spreadsheets. | Deduplicate by ASIN and compare repeat category runs across dates. |
For many teams, the best Amazon product research scraper is the one that produces a small, explainable CSV from the exact pages they are allowed to review.
Workflow
From category page to structured product research table
The bundled UScraper workflow is direct: Set Window Size -> Navigate -> Wait for Page Load -> Sleep -> Wait for Element -> Structured Export -> Loop Continue. Navigate holds page 1 and page 2 URLs. Structured Export reads the visible product grid and appends both pages into one CSV.
| Research question | Export columns that help answer it |
|---|---|
| Which category and page produced this row? | original_url, category |
| What is the visible new-release position? | position |
| What product should we inspect next? | asin, name, url, picture |
| Who is behind the listing? | brand |
| Is there early demand or proof? | stars, ratings, reviews_link |
| What is the visible commercial context? | platform, price |
| Did the run hit an unusual state? | error |
There is no CSV sample in the bundle, so the JSON workflow is the authoritative sample before your first run. It shows selectors, append mode, filename, output columns, and pagination shape. Your first validated run becomes the real sample for your marketplace and category.
Use cases
Four practical Amazon new releases product research workflows
1. Launch scouting for sellers
Sellers can run a narrow category, sort by rank and review count, then inspect products with high visibility but still-light review history. The export does not tell you margin, ad cost, or return risk, but it gives you a cleaner shortlist than copied product names.
2. Category trend monitoring
Category managers can save the same Hot New Releases URLs and rerun them on a fixed cadence. Deduping by ASIN makes it easier to see repeat appearances, new entrants, missing products, and price movement.
3. SEO and content research
SEO teams can use titles, brands, platform text, prices, and review counts to enrich category briefs. New-release pages often expose naming patterns before slower editorial keyword tools. Pair the export with SERP checks instead of treating scraped titles as a keyword strategy by themselves.
4. Newsroom and market analysis
Journalists and analysts studying marketplace visibility need reproducible samples. The Markup's Amazon search investigation shows why ranking-data work needs clear methodology, preserved URLs, and careful interpretation. A local CSV can support that workflow when the team documents run time, marketplace, category, and validation notes.
Decision
Amazon New Releases API alternative, scraper, or manual review?
An Amazon New Releases API alternative can mean three different things: official Amazon API access, a hosted scraper API, or a local desktop workflow. They are not interchangeable.
| Route | Best fit | Trade-off |
|---|---|---|
| Product Advertising API or partner routes | Sanctioned product applications, affiliate workflows, and programmatic access | Eligibility, request rules, field availability, and API semantics may not mirror Hot New Releases pages. |
| Hosted scraper API | Larger recurring jobs, infrastructure outsourcing, programmatic delivery | Data custody, pricing, retries, and compliance posture depend on the vendor. |
| Manual review | Tiny samples where screenshots and notes are enough | Slow, inconsistent, and difficult to repeat across categories. |
| UScraper template | Controlled category snapshots, analyst QA, and local CSV output | Best for reviewable research batches, not unattended high-volume data pipelines. |
If you need official access, start with Amazon's Product Advertising API documentation and SearchItems operation. If you need a category-page research export, use the template, validate a small run, and keep the data scope modest.
Operating model
How to turn the template into a repeatable research system
Define the category question
Pick one category, one marketplace, and one purpose: launch scouting, SEO research, newsroom sampling, or monitoring.
Import the template
Open the Amazon Hot New Releases Scraper by Category, download the JSON workflow, and import it into UScraper.
Replace category URLs
Swap the example Navigate URLs for approved Hot New Releases category pagination URLs. Keep different categories in separate runs.
Validate before scaling
Run a small pass and compare rank, ASIN, title, price, rating, review count, and product URL against the rendered page.
Archive the CSV with notes
Store the CSV with run date, marketplace, category, and validation notes for later comparison.
For implementation details, use the step-by-step how-to guide. For vendor trade-offs, read the Amazon Hot New Releases scraper comparison or browse the full UScraper template library.
FAQ
FAQ
Marketplace researchers, sellers, SEO teams, journalists, and category managers should use it when they need a repeatable snapshot of visible new-release rankings for a defined category. Treat it as a research input, not a standalone buying signal.