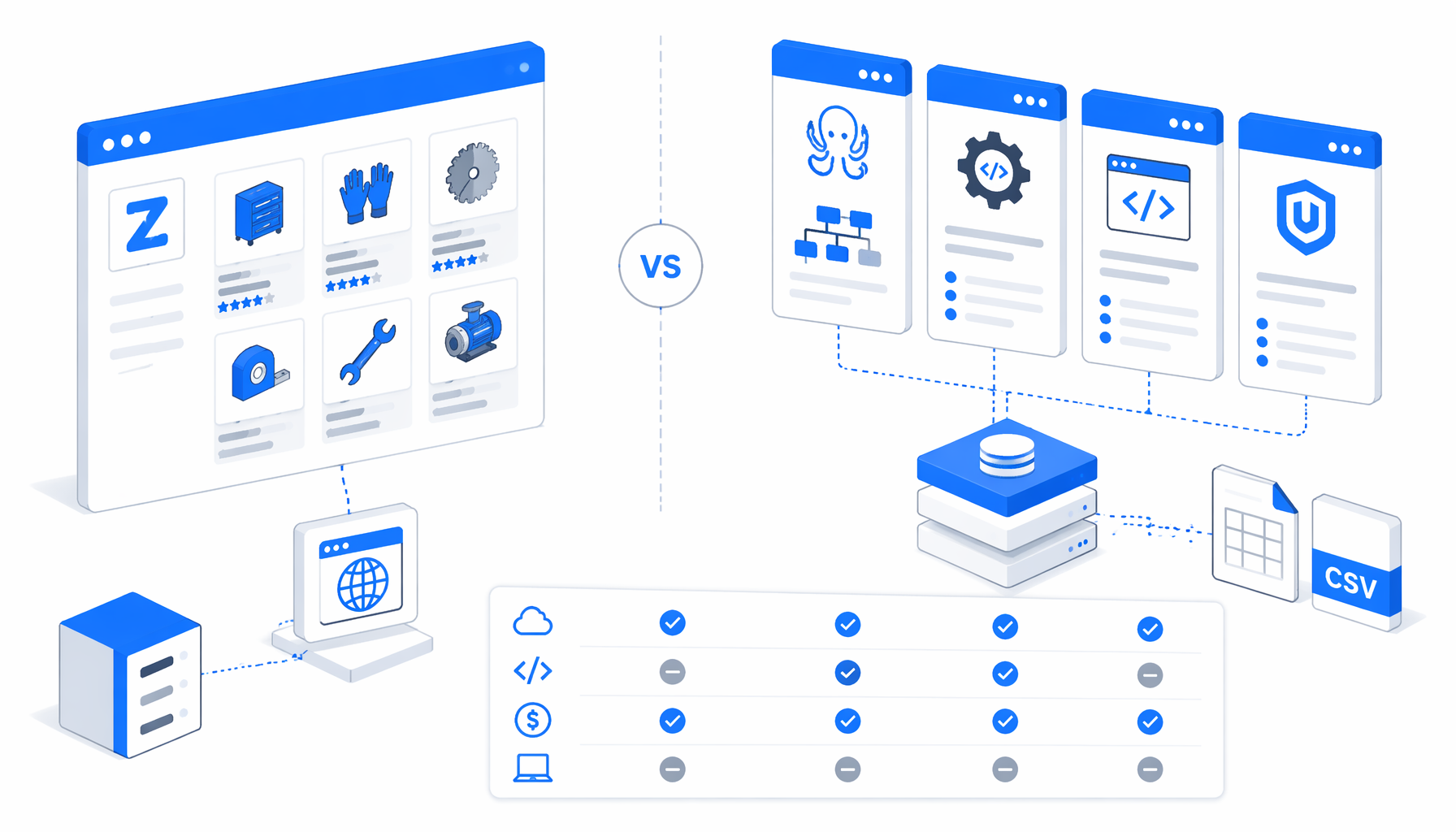
The best Zoro scraper depends on the job. This comparison looks at Octoparse, Outscraper, Apify, scraping APIs, custom scripts, and UScraper's Zoro Product Scraper template by hosting model, code level, output, pricing meter, and maintenance burden.
Comparison frame
What a Zoro product data scraper has to solve
A useful Zoro product data scraper needs more than names. Teams care about brand, title, canonical URL, shipping label, manufacturer number, current price, original price, stock state, image URL, and category context. The challenge is keeping those fields tied to the exact product URL while pages vary by session, region, and access checks.
Searches such as how to scrape Zoro, zoro scraper vs Octoparse, and zoro scraping tools split into no-code platforms, cloud actor marketplaces, scraping APIs, open-source scripts, and local visual workflows.
The fair question is not "can this tool extract one Zoro page?" It is "where does the browser run, how is the run priced, who maintains selectors, and what output does the team actually need?"
Side by side
Zoro scraper alternatives compared
| Option | Best fit | Hosting | Code needed | Output | Pricing shape | Main trade-off |
|---|---|---|---|---|---|---|
| UScraper + Zoro Product Scraper | Product-detail URL batches and reviewed CSV | Local desktop app | Low | CSV: brand, title, URL, shipping, Mfr number, prices, stock, image | Free template; app licensing applies | You own QA and selectors |
| Octoparse Zoro Scraper and Zoro Product Scraper | Hosted no-code users who want vendor templates | Octoparse platform | Low | Table exports such as CSV or Excel-style outputs | Free tier plus paid SaaS plans | Convenient template layer, but less local workflow custody |
| Outscraper Zoro Products Scraper | Teams that prefer provider-managed delivery | Provider API or managed service | Low to medium | API, CSV, or managed data delivery depending on setup | Usage or service pricing | Less visual control over each browser step |
| Apify Web Scraper and ecommerce actors | Cloud actors, datasets, APIs, and schedules | Cloud actor platform | Low to medium | Dataset, JSON, CSV, API | Platform usage and actor terms | Strong orchestration, but costs depend on run shape |
| ScrapingBee, Scrapfly, Scrape.do, Crawlbase, and similar tutorials | Developer-built Zoro crawlers | Your code plus provider API | High | JSON or CSV you build | API usage plus engineering time | Parser upkeep stays with you |
| Open-source or custom Python, Playwright, Scrapy, or Selenium scripts | Source-controlled data pipelines | Your environment | High | Any schema you design | Engineering and infrastructure cost | Maximum control, maximum maintenance |
This table is a decision matrix, not a universal ranking. If you need a recurring backend integration, use a cloud actor or API. If you need a reviewed spreadsheet from a known URL list, UScraper is usually simpler.
Where UScraper wins
When UScraper is the better Zoro scraper alternative
UScraper is strongest when the workflow starts from a controlled list of Zoro product detail URLs and ends in a spreadsheet. The Zoro Product Scraper for CSV Export opens each URL, waits for the page, reads JSON-LD, meta tags, visible text, and product-ID fallbacks, then appends one row to zoro-scraper.csv.
The bundled JSON workflow is intentionally inspectable:
{
"project": { "name": "Zoro Scraper" },
"blocks": [
{ "title": "Set Window Size" },
{ "title": "Navigate", "config": { "urls": ["https://www.zoro.com/.../i/G0058816/"] } },
{ "title": "Wait for Page Load" },
{ "title": "Wait for Element", "config": { "selector": "body" } },
{ "title": "Sleep" },
{ "title": "Structured Export", "config": { "fileName": "zoro-scraper.csv", "fileMode": "append" } },
{ "title": "Loop Continue" }
]
}
That visibility matters. If Current_price is blank, you can inspect the page and export column. If duplicate rows appear, check append mode and the URL list. If Zoro shows DataDome, CAPTCHA, or a 403 state, stop the batch instead of trusting bad rows.
UScraper wins when the CSV should be created locally and stay in the configured folder unless you add upload or sync steps.
UScraper wins when a non-developer needs to inspect URLs, waits, export fields, file names, and loop behavior before a batch.
Hosted platforms win when schedules, queues, remote browsers, logs, webhooks, and API pulls matter more than local supervision.
Scraping APIs and engineering stacks win when the job needs proxy orchestration, retries, tests, monitoring, and code-level parser ownership.
Where others win
When Octoparse, Apify, APIs, or scripts make more sense
Choose Octoparse when your team already works inside its platform and wants no-code Zoro templates with vendor-side task management. Choose Apify for cloud actor runs, schedules, datasets, logs, API access, and marketplace patterns.
Choose Outscraper or a scraping API such as ScrapingBee, Scrapfly, Scrape.do, or Crawlbase when developers want endpoint-style delivery or managed request, rendering, and anti-blocking infrastructure. Choose custom scripts when Zoro scraping belongs in a source-controlled system with tests, storage, monitoring, and selector upkeep.
Decision guide
Best Zoro scraper for each job
| Job | Best starting point | Why |
|---|---|---|
| One-off product-detail CSV from known URLs | UScraper + Zoro Product Scraper | Visible local workflow and zoro-scraper.csv. |
| Broad category or listing discovery before detail enrichment | Zoro listing scraper | Collect product listing rows first, then enrich selected URLs. |
| Hosted no-code scraping workspace | Octoparse templates | Useful when your team prefers platform-managed scraping tasks. |
| Cloud schedules, datasets, and API pulls | Apify or a managed actor setup | Better fit for recurring cloud orchestration. |
| Developer-owned scraping pipeline | Python, Playwright, Scrapy, Selenium, or scraping APIs | Best when code review, tests, and custom storage are required. |
| Vendor-managed data delivery | Outscraper or a scraping service | Better when you want an external provider to package the export. |
For neighboring workflows, browse the UScraper template library, compare the Zoro listing scraper, or read the step-by-step Zoro scraper tutorial.
FAQ
Zoro scraper alternatives FAQ
The best option depends on the job. Use UScraper when you have approved product detail URLs and need a visible local desktop app workflow that exports CSV. Use Octoparse for hosted no-code templates, Apify for cloud orchestration, Outscraper or scraping APIs for endpoint delivery, and scripts for full parser control.
Next step
Try the Zoro product scraper template
If the fit is a supervised local CSV workflow, import Zoro Product Scraper for CSV Export, replace sample URLs, run one product, and compare the row before expanding. For broader ideas, return to the UScraper blog or explore UScraper templates.