This tutorial shows how to scrape Zillow agents from reviewed profile URLs into CSV with the Zillow Profile Scraper for UScraper. You will import the workflow, replace the sample URLs, set the export path, run a small validation batch, and check the output before using it for real estate research.
Before you start
Prerequisites and Zillow policy checks
You need UScraper installed as a local desktop app, the Zillow Profile Scraper template, a short list of Zillow agent profile URLs you are allowed to process, and a folder for CSV exports. Start with three to five profiles. Agent pages can vary by profile type, location, brokerage, sign-in state, and Zillow's current access controls.
This guide covers profile pages you can already open in a normal browser session. It does not cover account dashboards, Premier Agent admin pages, lead inboxes, login-only data, CAPTCHA solving, or bypassing anti-bot controls. Review Zillow's Terms of Use, robots.txt, and official agent help center before automation.
Technical access is not the same thing as permission. Keep volume modest, do not defeat verification challenges, document why you collected the data, and use approved data or partnership routes when you need contractual rights.
Workflow anatomy
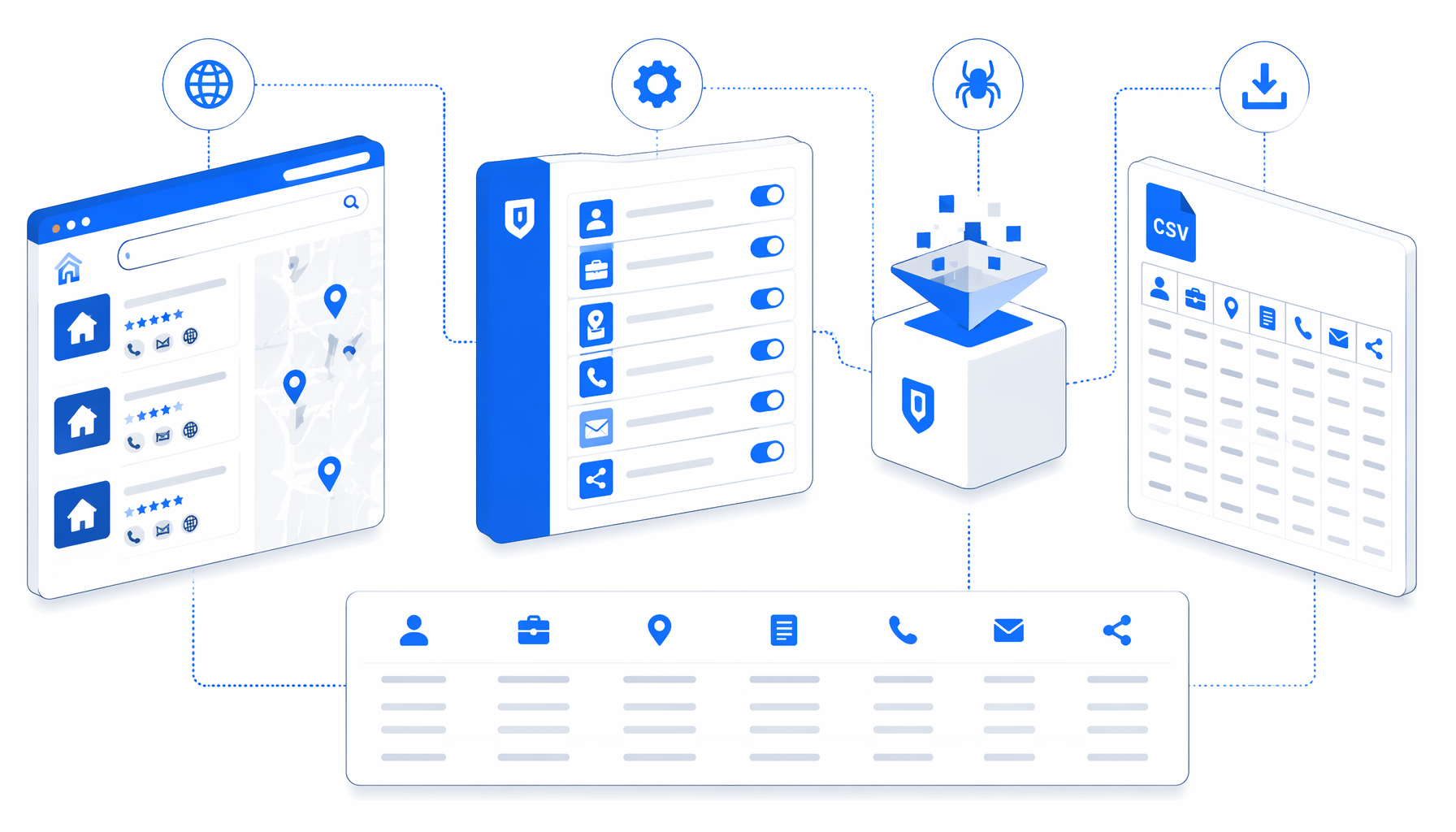
What the Zillow agent profile scraper does
The companion JSON export is the authoritative workflow definition. In plain English, the flow is:
Set Window Size -> Navigate over profile URLs -> Wait for Page Load
-> Sleep -> Wait for html -> Check access-denied text
-> Expand visible profile text -> Structured Export -> Loop Continue
Navigate owns the profile URL list. The wait blocks give Zillow time to render profile content. The text check prevents a blocked page from being treated as a valid profile. Structured Export writes a row with JavaScript-backed columns, then Loop Continue advances to the next URL.
| CSV column group | Fields | Why it matters |
|---|---|---|
| Page context | Page_title, Page_URL, Original_URL | Keeps every row tied to the exact profile URL that produced it. |
| Agent identity | Profile_Name, Company_Name, City_Location, State_Location | Supports dedupe, market grouping, and brokerage research. |
| Profile content | Full_Bio, Address | Captures visible bio and office context for human review. |
| Contact fields | Cell_Phone, Office_Phone, Email, Website | Creates a starting point for compliant contact-record verification. |
| Social links | Linkedin, Facebook, Instagram, Twitter | Helps analysts enrich profiles without manually opening each page. |
Because Zillow profile markup can change, the template uses best-effort fallbacks: JSON-LD when present, visible headings when available, metadata when useful, and page text patterns for phone, email, address, city, and state. That makes the workflow practical for research, but it still needs validation.
Runbook
How to scrape Zillow agent profiles to CSV
Replace sample profile URLs
In Navigate, replace the three example URLs with your reviewed Zillow profile URLs. Keep one URL per input item and start with a small sample.
Keep the waits intact
Preserve the page-load wait, short sleep, and html wait. If profiles load slowly in your session, increase waits before changing selectors.
Set the export folder
Structured Export writes zillow-profile-scraper.csv with headers and append mode. Change the save location to your project folder.
Run one batch and inspect
Run the first few URLs, compare the CSV against the browser, then widen only after names, companies, phones, and profile URLs look correct.
Append mode is useful for multi-URL loops, but it can also mix test rows with production rows. Use a dated filename or clear the CSV before a rerun if you want a clean export.
Validation
Validate the Zillow profile CSV
There is no bundled CSV sample for this template, so the expected export shape comes from the workflow JSON: one accessible profile URL should produce one row with 17 columns. The JSON is the source of truth for column names, skip conditions, and the local save path.
| Symptom | Likely cause | Fix |
|---|---|---|
| Zero rows exported | Every URL hit an access-denied page or the loop never reached Structured Export | Open one URL manually, confirm access, and rerun only that profile. |
| CAPTCHA text in CSV | The skip condition missed a changed block message | Add the new block phrase to the Text Contains check and rerun. |
Empty Profile_Name | No JSON-LD name, missing h1, or unexpected title format | Inspect the rendered profile and update the name fallback. |
| Missing phones or email | The profile does not expose those fields, or labels changed | Treat contact fields as optional and verify against the visible page. |
| Duplicate profiles | A URL appears twice or a rerun appended into the same file | Dedupe by Original_URL and use fresh filenames for new runs. |
Stop the batch, review the URL in a normal browser, and keep the blocked profile out of the export. The template is intentionally not a CAPTCHA bypass tool.
Tool choice
Zillow scraper vs Octoparse, Apify, and custom code
If you are comparing the best Zillow agent scraper for a one-off profile review, start with custody and workflow control. UScraper runs the flow in a local desktop app, writes a local CSV, and lets you inspect each browser step. That is useful when a real estate team already has a reviewed URL list and wants a spreadsheet without building a Python scraper.
Octoparse and other no-code cloud tools can be convenient when you want hosted runs and a visual extractor. Apify actors are useful when your team wants cloud scheduling, datasets, APIs, and managed infrastructure. Custom Python gives the most control for engineering teams, but it also means maintaining browser automation, waits, retries, selectors, compliance checks, and exports yourself.
| Option | Best fit | Trade-off |
|---|---|---|
| UScraper Zillow Profile Scraper | Local CSV export from known profile URLs | You validate access and selectors before scaling. |
| Octoparse-style visual templates | Hosted no-code extraction | Data and runs typically move through a third-party cloud workflow. |
| Apify actors | Scheduled cloud datasets and APIs | Usage-based infrastructure and actor behavior need review. |
| Custom code | Full engineering control | Highest maintenance burden for anti-bot, layout, and export changes. |
For this tutorial's use case, the shortest path is the Zillow Profile Scraper template. For broader scraping examples and related workflows, browse the UScraper blog and template library.
FAQ
Zillow agent profile scraper FAQ
Is it legal to scrape Zillow agent profiles?
Zillow profile pages can be publicly visible and still governed by Zillow Terms of Use, robots directives, privacy law, real estate advertising rules, and data licensing limits. Review the current policies, avoid bypassing verification or access controls, and get legal review before commercial outreach or resale.
Do I need a Zillow account to use this workflow?
No Zillow account or API key is built into the bundled UScraper workflow. It opens profile URLs from the Navigate block and exports visible fields when the page is accessible in that browser session.
What does the Zillow profile scraper export?
The CSV includes Page_title, Page_URL, Original_URL, Profile_Name, Company_Name, City_Location, State_Location, Full_Bio, Website, Linkedin, Facebook, Instagram, Twitter, Cell_Phone, Office_Phone, Email, and Address.
Why does Zillow return an access-denied or CAPTCHA page?
Zillow may show verification, access-denied, or PerimeterX challenge pages when automated access is limited. The template is designed to detect and skip blocked pages rather than export challenge text as profile data.
How many Zillow profiles can I scrape?
The workflow loops through the profile URLs you place in Navigate and appends one row per accessible profile. Practical volume depends on permission, pacing, page availability, verification frequency, rate limits, and selector maintenance.