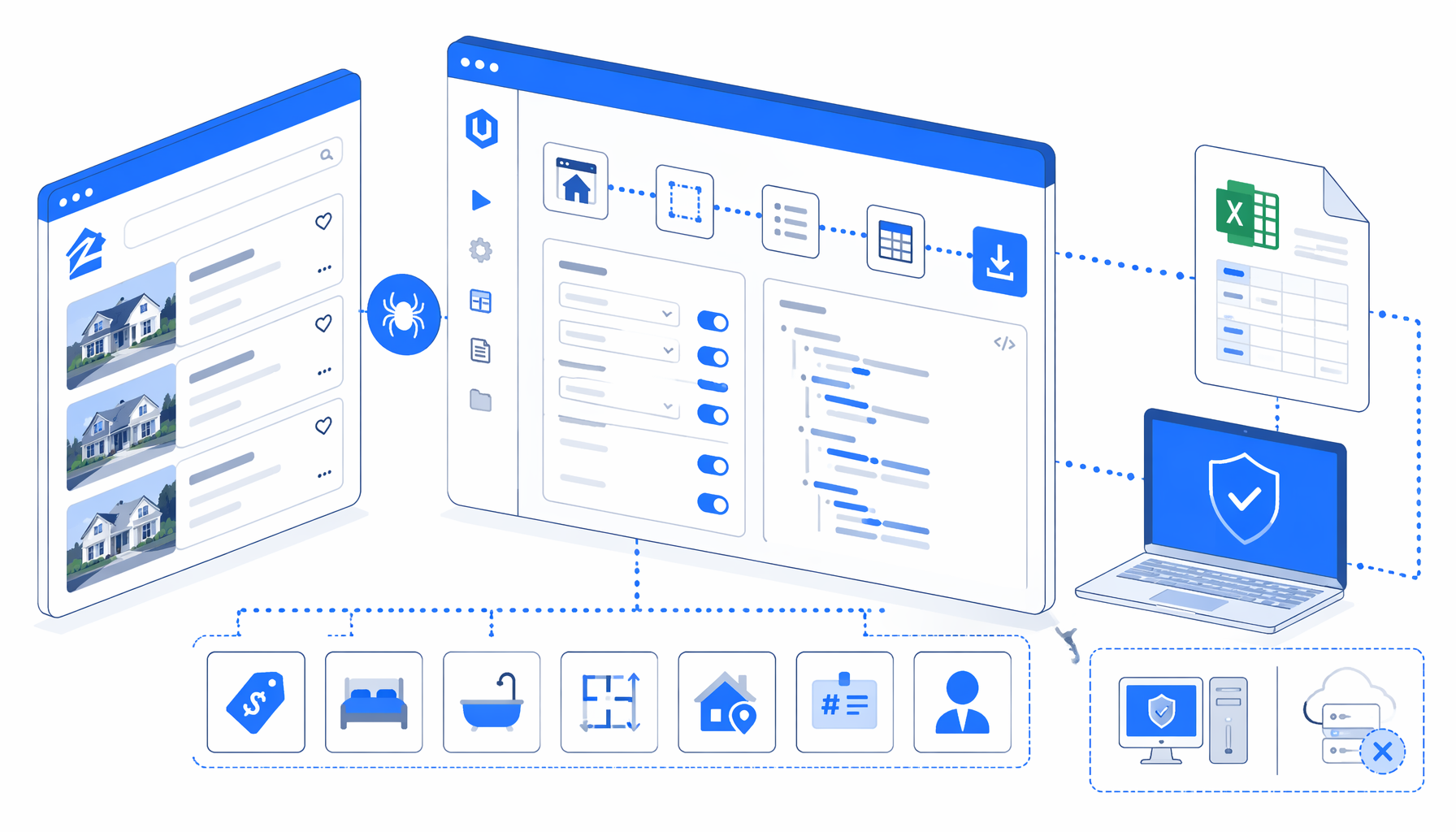
This tutorial shows how to scrape Zillow listing URLs into CSV with UScraper's Zillow Listing Scraper by URL. It covers prerequisites, import flow, export path setup, validation, common failures, and when an official data route is a better fit.
Scope
What this Zillow URL scraper is for
Use a Zillow scraper by URL when you already know the property pages you want to review. That might be a shortlist of comps, a saved set of active listings, URLs collected by an analyst, or links passed over from a search-page workflow.
The important distinction is scope: this template does not crawl Zillow broadly from a keyword. It opens each configured detail page and extracts fields from that page state. That makes it easier to validate because every row has a source URL, but it also means the input list matters. Bad URLs, inaccessible pages, expired listings, regional prompts, and verification screens can all produce blanks.
Before you automate, review Zillow's Terms of Use and robots.txt. Public visibility is not the same as unrestricted reuse.
Treat this as an internal research workflow unless your legal, compliance, and data licensing review says otherwise.
Prerequisites
Prepare the Zillow listing URLs
You need three things before running the template: UScraper installed, a folder for the CSV export, and a reviewed list of Zillow property detail URLs. Use full property URLs such as /homedetails/.../_zpid/, not a map search page.
Keep the first input list narrow. Mixes of for-sale homes, sold homes, rentals, land, condos, and off-market pages can expose different labels. That is normal for real estate data, but it makes the first validation pass harder. If you need discovery from a city or keyword first, use the Zillow Listing Scraper by Keyword or browse related workflows in the template library.
| Input check | Why it matters |
|---|---|
| URL opens manually | Confirms the page is accessible before automation. |
| Page has an address heading | The workflow waits for h1 before export. |
| Listing details are visible | Price, beds, baths, sqft, and status are not always present. |
| No verification screen | The template is not designed to bypass access controls. |
| Batch is modest | Easier to spot selector drift or blocked page states. |
Workflow
How to scrape Zillow listing data to CSV
Download and import
Open the Zillow Listing Scraper by URL template, download the JSON, and import it into UScraper.
Replace the sample URLs
In the Navigate block, replace the bundled sample Zillow URLs with your reviewed property detail URLs.
Confirm the export path
In Structured Export, set the save folder for your project and keep the filename as zillow-scraper.csv unless you want a versioned file.
Run a validation batch
Start with a short list, watch the browser flow, and verify that each page reaches the property heading before export.
Open and audit the CSV
Compare several rows against Zillow, then expand only after address, price, URL, and status fields match the visible page.
{
"project": {
"name": "Zillow Listing Scraper by URL"
},
"export": {
"fileName": "zillow-scraper.csv",
"fileMode": "append",
"columns": [
"keyword",
"image_url",
"house_url",
"price",
"bedroom_s_",
"bathroom_s_",
"square_feet",
"status",
"address",
"mls_id",
"listing_by"
]
}
}
The JSON export is the authoritative workflow definition. This article explains the intent and validation path; the imported template preserves the actual blocks, selectors, JavaScript column logic, and loop behavior.
Output
What the Zillow CSV contains
The output is a property-detail CSV, not a market-wide Zillow dataset. The template relies on stable page signals where possible: Open Graph metadata, the visible address heading, the current URL, visible MLS text, and embedded page data. Zillow uses dynamic markup, so the workflow avoids depending only on class names.
zillow-scraper.csvColumn
keyword
State or location label inferred from breadcrumbs or address text.
Column
image_url
Open Graph image or visible property image URL.
Column
house_url
Canonical Zillow property URL or the current browser URL.
Column
price
Displayed or embedded listing price when available.
Column
bedroom_s_
Bedroom count from metadata or visible page text.
Column
bathroom_s_
Bathroom count from metadata or visible page text.
Column
square_feet
Living area parsed from embedded data, meta description, or text.
Column
status
Active, sold, pending, off market, house for sale, or similar text.
Column
address
Property address from the page heading or Open Graph title.
Column
mls_id
MLS ID or MLS number when Zillow exposes it.
Column
listing_by
Brokerage, broker, or listing source text when available.
Quality control
Validate the Zillow export
Open the CSV beside the browser and inspect the first few rows. Confirm that house_url opens the same property, address matches the page heading, price matches the visible price, and mls_id is either correct or blank when no MLS value is exposed.
| Symptom | Likely cause | What to do |
|---|---|---|
| CSV has no rows | Page did not reach the expected detail state | Open the URL manually, handle prompts, and rerun a small batch. |
| Address exists but price is blank | Zillow hid the price, changed embedded data, or served a different listing type | Inspect the page text and update only the price column logic if needed. |
| MLS ID is missing | The listing does not expose MLS text or changed its label | Treat blank as valid unless the value is visible in the browser. |
| Repeated rows | Append mode wrote into an old CSV | Use a fresh folder or versioned filename for each run. |
| Run pauses on verification | Access control appeared | Stop the batch; do not bypass CAPTCHA or similar controls. |
This validation step is the practical difference between a useful export and a spreadsheet that looks complete but cannot be trusted.
Data options
Zillow data API vs scraping
Scraping is not the right default for every Zillow data project. If you need production integrations, MLS listing coverage, redistribution rights, or recurring high-volume access, review Zillow Group Developers, the MLS Listings API, and the Bridge API.
Use the UScraper template when the job is narrower: a supervised internal CSV from property URLs you already reviewed. Use official or licensed access when the data becomes a product dependency.
| Route | Best fit | Trade-off |
|---|---|---|
| UScraper URL template | Modest internal CSV exports from known property pages | Best-effort page extraction and selector maintenance. |
| Zillow Group or Bridge APIs | Licensed feeds and approved integrations | Access rules, eligibility, and data contracts apply. |
| Python scraper | Engineering teams that can maintain code, retries, and parsing | More control, more breakage responsibility. |
| Hosted scraping tools | Cloud schedules, APIs, and managed runs | Usage metering and third-party processing. |
FAQ
Zillow listing scraper by URL FAQ
Zillow pages can be publicly visible and still governed by Zillow Terms of Use, robots guidance, data licensing rules, privacy law, copyright rules, and local real estate regulations. Review the current policies, do not bypass access controls or CAPTCHA, keep pacing conservative, and get legal review before commercial reuse.
Next step
Download the Zillow URL scraper template
Download the Zillow Listing Scraper by URL, import the JSON into UScraper, and keep this tutorial open while you run the first validation batch. For broader real estate automation, explore the template library or browse more tutorials on the UScraper blog.