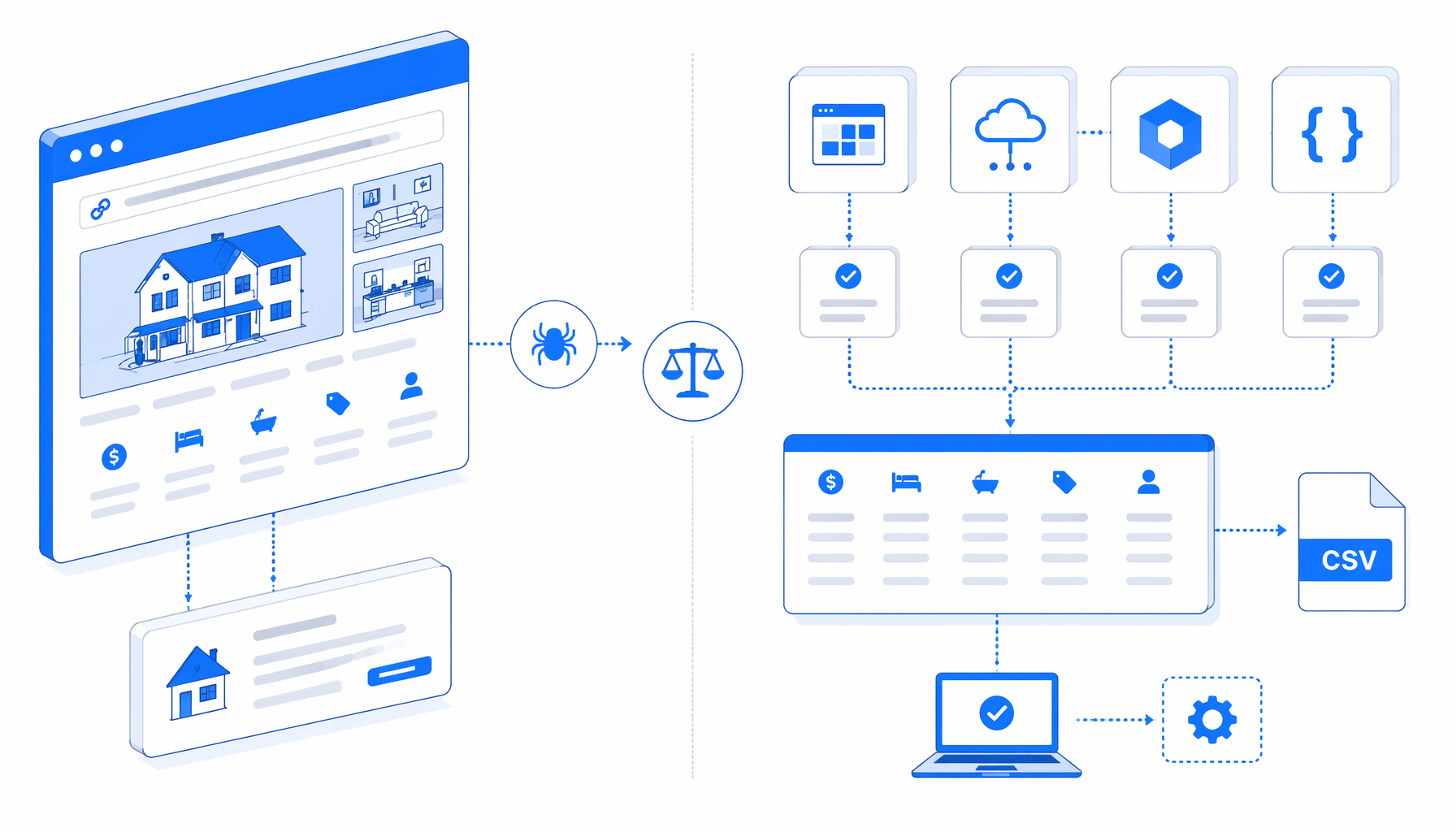
This Zillow scraper by URL comparison looks at UScraper, Octoparse, Apify, scraper APIs, marketplace scrapers, and scripts through one practical question: how should you turn reviewed Zillow property URLs into a trustworthy CSV?
Decision frame
What to compare before choosing a Zillow scraper
A fair Zillow scraper alternatives list should start with the run model. Does the browser run on your machine or in a vendor cloud? Do you need a scheduled API feed or a one-time CSV? Who fixes selectors when Zillow changes page markup?
For a URL-driven task, the input list is scoped. You are asking the tool to open known property detail pages and extract price, beds, baths, square feet, status, address, MLS ID, broker, image URL, and source URL.
The best Zillow scraper is the one whose failure mode your team can inspect. For a small analyst batch, that usually matters more than the longest feature checklist.
Before automating, review Zillow's Terms of Use, crawler guidance, and official data options from Zillow Group Developers.
Side by side
Zillow scraper by URL alternatives compared
| Option | Best fit | Hosting | Code needed | Output model | Pricing shape | Main trade-off |
|---|---|---|---|---|---|---|
| UScraper + Zillow Listing Scraper by URL | Analyst-reviewed property URL batches | Local desktop app | Low | CSV appended locally | Free template; app licensing applies | Strong visual control, but not a cloud scheduling platform |
| Octoparse Zillow templates | No-code users who want vendor templates | Vendor platform | Low | Tables, CSV, Excel-style exports | SaaS plans and task limits | Convenient setup, but less local custody of the run |
| Apify Zillow actors | Cloud actors, datasets, schedules, and APIs | Apify cloud | Low to medium | JSON, CSV, API datasets | Platform usage plus actor pricing | Strong orchestration, but metering and actor quality vary |
| WebScraper.io marketplace | Marketplace sitemap workflows | Browser extension or cloud platform | Low to medium | Sitemap-driven exports | Plan and cloud execution limits | Useful for trained workflows, still needs QA on dynamic pages |
| Bright Data or Decodo scraper APIs | Backend data pipelines and managed delivery | Provider infrastructure | Medium | API responses or datasets | Request, record, or usage-based | Better for engineering pipelines than manual review |
| pyzill, Playwright, or Selenium scripts | Teams that own code, tests, and maintenance | Your environment | High | Whatever you build | Engineering time plus infrastructure | Maximum control, maximum breakage responsibility |
| Official or licensed data routes | Production feeds, compliance-sensitive products, MLS coverage | Official or partner systems | Medium | Approved APIs or datasets | Contract and eligibility based | Stronger permission posture, not a quick custom scraper |
This is why an Apify Zillow scraper comparison can be misleading if it only compares fields. Apify is a cloud platform, Octoparse is a no-code platform, scraper APIs are backend services, and UScraper is a local visual workflow.
UScraper fit
Where UScraper wins, and where it does not
UScraper wins when the operator wants the workflow to be visible. The template opens each Zillow listing URL, waits for the page, handles common consent or close buttons, exports structured columns, and continues the URL loop.
It also wins when the output is the deliverable. The CSV fields include keyword, image_url, house_url, price, bedroom_s_, bathroom_s_, square_feet, status, address, mls_id, and listing_by.
UScraper is stronger when a person needs to watch the run, inspect page state, update selectors, and keep the CSV local.
Apify, scraper APIs, and managed providers are stronger for schedules, webhooks, API datasets, logs, and server-side infrastructure.
Octoparse and UScraper both reduce coding. Choose Octoparse for hosted task management; choose UScraper for a local workflow with editable blocks.
Scripts give engineers the most control. UScraper exposes selectors and JavaScript helpers without forcing every analyst into a codebase.
The limitation is scale. UScraper is not the answer for a hosted API, cloud queue, managed proxy pool, or contractual data delivery. It is the answer when the question is how to scrape Zillow by URL for a modest batch without writing a scraper.
Alternatives
How competitors fit
Octoparse Zillow scraper alternative
Octoparse belongs in any best Zillow scrapers shortlist when you want no-code templates and hosted task tooling. UScraper is more direct for a URL list: import the template, replace sample URLs, confirm the export folder, run, and open the CSV.
Apify Zillow scraper comparison
Apify is stronger when scraping is part of a larger automation system. Actors can be called from APIs, scheduled, logged, and connected to datasets. UScraper wins a different job: local supervision, visual debugging, and analyst-controlled CSV output.
Zillow scraper API comparison
Bright Data, Decodo, and similar providers are closer to infrastructure than desktop tooling. Use them for programmatic access, managed extraction, proxy handling, or recurring ingestion. For a one-off CSV, an API can be heavier than the task deserves.
Output
What the UScraper Zillow URL workflow exports
The bundled workflow definition uses a multi-URL input loop, browser waits, a consent-button helper, and structured export columns. It relies on stable page signals where possible: metadata, the visible address heading, the current URL, visible MLS text, and embedded page data.
| CSV column | What it is used for |
|---|---|
house_url, address | Source review, dedupe, and human validation. |
price, bedroom_s_, bathroom_s_, square_feet | Basic property comparison and spreadsheet filtering. |
status, mls_id, listing_by | Listing state, MLS reference, and broker or source context when exposed. |
image_url, keyword | Visual QA and rough location or state grouping. |
Compliance
Compliance and data quality checks
No scraper removes the need to review terms, robots directives, privacy law, copyright, MLS rules, and local real estate regulations. Do not bypass CAPTCHA, login walls, paywalls, or access controls. If the data becomes a product dependency, use official or licensed routes.
For quality control, save each run into a fresh file, spot-check source URLs, and treat blanks as unknowns rather than zeros.
Decision
Which Zillow scraper should you choose?
Use UScraper if you have a reviewed list of property URLs, want a local visual flow, and need a CSV with listing-detail fields. Start from the Zillow Listing Scraper by URL template and keep the first run small.
Use Octoparse for hosted no-code setup, Apify for cloud actors, scraper APIs for backend pipelines, and scripts when your team accepts maintenance. Browse more workflows in the UScraper template library, or compare guides on the UScraper blog.
FAQ
Zillow scraper by URL FAQ
Use official data access for production feeds, Apify or scraper APIs for cloud scale, Octoparse for hosted no-code setup, scripts for engineering control, and UScraper for local CSV exports from reviewed listing URLs.