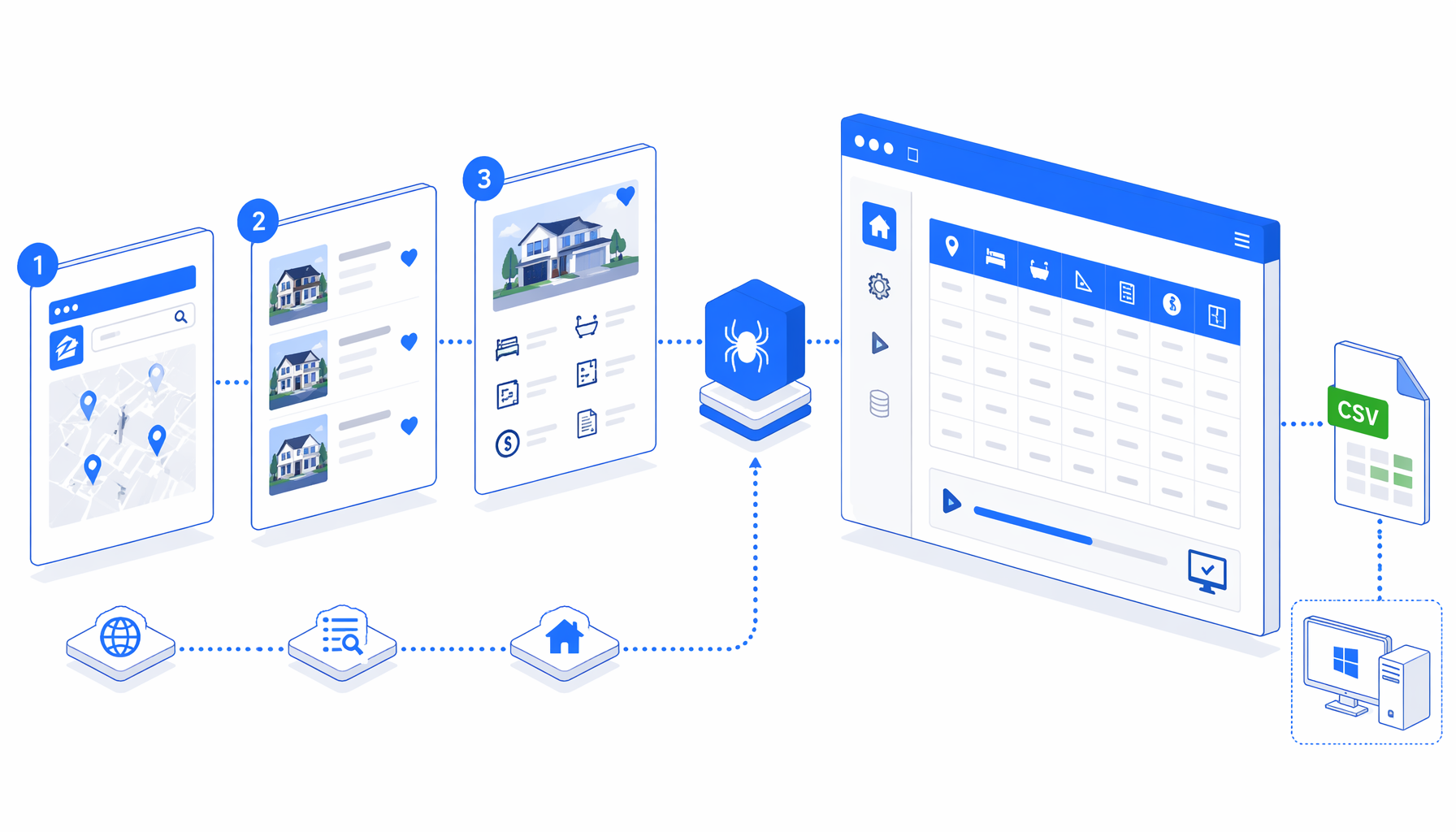
This tutorial shows how to scrape Zillow property data into CSV with UScraper's Zillow Details Scraper template. You will prepare URLs, import the workflow, validate the first rows, and understand common failure modes before expanding a batch.
Before you start
Prerequisites before you scrape Zillow property details
You need UScraper installed as a local desktop app, a reviewed list of Zillow property URLs, and a folder where CSV files can be written. Use detail or address URLs such as /homedetails/... that open normally in your browser. Do not start from a broad map search page unless another workflow has already converted the results into property URLs.
This guide is for internal research exports from pages you can inspect in a normal browser. It is not a guide to bypass CAPTCHA, sign-in walls, private dashboards, or access controls. Before automating, review Zillow's Terms of Use, Zillow Group developer and data terms, and current robots.txt.
A Zillow page being visible in a browser does not automatically mean every downstream use is allowed. Keep batches modest, document why you are collecting the data, and stop if the site asks for manual verification.
Workflow
What the Zillow details scraper template does
The Zillow Details Scraper template is the download path for this tutorial because the JSON preserves the block order, waits, extraction script, export columns, and loop behavior. It is designed for detail pages, not search-result inventory crawling.
The bundled workflow follows this path: Navigate -> Wait for Page Load -> Sleep -> Wait for Element -> Inject JavaScript -> Structured Export -> Loop Continue. The JavaScript step searches Zillow embedded JSON first, then visible labels, then URL-derived address fallbacks.
{
"project": "Zillow Details Scraper",
"input": "multiple Zillow detail or address URLs",
"flow": [
"Navigate",
"Wait for Page Load",
"Sleep",
"Wait for Element",
"Inject JavaScript",
"Structured Export",
"Loop Continue"
],
"output": "zillow-details-scraper.csv"
}
| Workflow block | What it does | What to verify |
|---|---|---|
| Navigate | Opens each Zillow URL from the configured list | Replace starter URLs with reviewed property pages. |
| Wait and Sleep | Gives dynamic page data time to render | Keep the first run slow. |
| Wait for Element | Confirms the page body exists | Stop if the browser shows verification or an empty body. |
| Inject JavaScript | Builds window.__zillowDetailsData | Check missing fields against the visible page. |
| Structured Export | Appends custom columns to CSV | Confirm folder, filename, headers, and append mode. |
| Loop Continue | Moves to the next URL | Watch for repeated rows when rerunning an old file. |
Runbook
How to scrape Zillow details to CSV
Download and import
Open the Zillow Details Scraper template, download the JSON, and import it into UScraper.
Replace the sample URLs
In Navigate, replace the starter Zillow URLs with reviewed detail pages. Keep the first list narrow and group similar listing types together.
Confirm the export path
Set the save folder. The stock filename is zillow-details-scraper.csv, headers are enabled, and append mode is on.
Run a validation batch
Start with a few URLs, watch the browser, and confirm that the page body renders before the JavaScript extraction block runs.
Audit the CSV
Compare address, beds, baths, living area, MLS fields, taxes, and room facts against the browser before joining the data with models or client reports.
If you searched for a Zillow scraper Python tutorial, the validation steps are similar. Python gives you code ownership; UScraper keeps the workflow editable as blocks inside the desktop app.
Output
What the Zillow details CSV contains
No CSV sample is included in the bundle, so use the export shape as your QA checklist. The workflow exports a wide property-detail row, not just card-level fields. Columns can be blank when Zillow omits a value, the listing type lacks that fact, or the page serves a different layout.
| Field group | Example columns | Validation tip |
|---|---|---|
| Identity | address, city, county, source, mls_id | Use address and MLS fields for dedupe before analysis. |
| Core facts | bed_count, bath_count, living_area_sqft, home_type, year_built | Treat blanks as unknown. |
| Listing signals | days_on_zillow, view_count, save_count, listing_updated, listing_by | Re-check volatile fields before sending a report. |
| Rooms | kitchen_level, primary_bedroom_dimensions, livingroom_dimensions | Room-level fields depend heavily on listing detail quality. |
| Features | heating, cooling, appliances, interior, lot_features | Use these as text fields until a human standardizes categories. |
| Ownership and tax | parcel_number, tax_assessed_value, annual_tax_amount, ownership | Verify against primary records before decisions. |
Validation
Validate the export before scaling
Open the CSV next to the browser and check at least five rows. The address should match the page, living area should preserve the displayed unit, MLS or source fields should not shift into the wrong column, and missing room dimensions should be explainable from the page.
For repeatable market work, add a review column outside UScraper: verified, needs_review, or blocked. That keeps data quality separate from market conclusions.
Alternatives
UScraper vs Python, APIs, and cloud Zillow scrapers
There is no single best Zillow scraper for every team. Use UScraper for supervised CSV exports from reviewed URLs. Use Python when your engineering team wants code ownership and can maintain rendering, retries, parsing, storage, and compliance checks. Use a licensed feed or approved API when you need redistribution rights, MLS-sensitive use, high-volume recurring ingestion, or contractual data access.
If you are looking for an Octoparse Zillow scraper alternative, the practical distinction is workflow control. UScraper keeps the run local and editable in the desktop app; hosted scraper products can be convenient when a cloud queue or vendor-managed environment is the priority.
FAQ
Frequently asked questions
Zillow pages can be publicly visible and still governed by terms, robots guidance, data licensing rules, copyright, privacy law, and real estate regulations. Review the current rules, do not bypass access controls, keep pacing conservative, and get legal review before commercial reuse.
For the next step, download the Zillow Details Scraper template, import it into UScraper, and browse the template library or UScraper blog when you need a listing-search workflow before detail extraction.