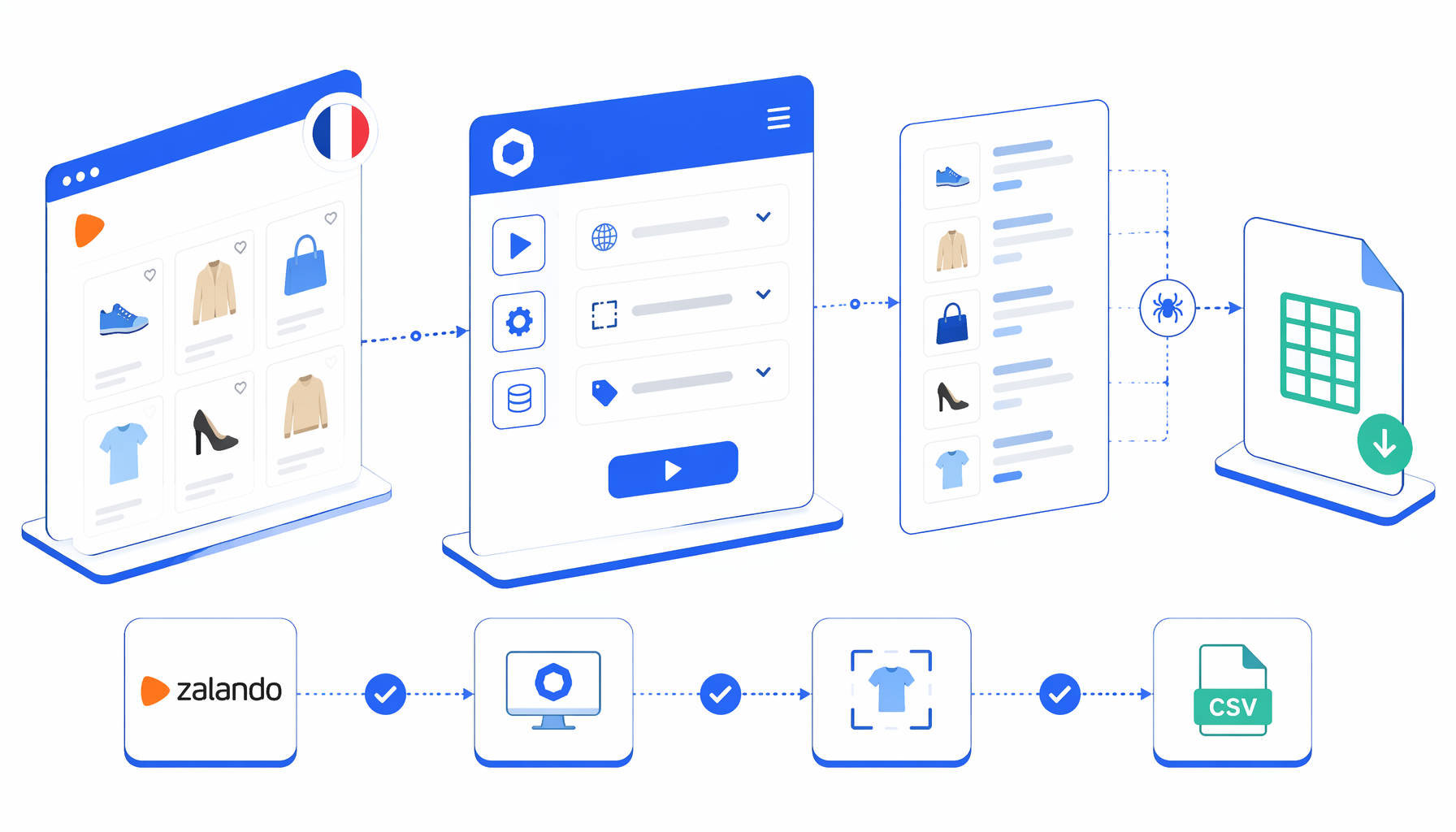
This tutorial shows how to scrape Zalando France product data from approved product detail URLs into CSV with the Zalando France Product Scraper template for UScraper. You will import the workflow, replace the sample URLs, set the export folder, run a small batch, and validate the rows before using the file.
Before you start
Prerequisites, scope, and Zalando policy checks
You need UScraper installed as a local desktop app, a short list of Zalando.fr product detail URLs you are allowed to process, and a folder where CSV exports can be written. Start with two to five product URLs. Fashion product pages can vary by size availability, locale, stock state, consent prompts, and page experiments, so a tiny validation run saves time before you scale.
This guide covers public product detail pages. It does not cover account dashboards, checkout flows, cart automation, login-gated content, CAPTCHA bypassing, or bulk crawling from catalogue pagination. Before running automation, review Zalando France's current robots.txt and legal terms, and keep your use case aligned with applicable law and contractual restrictions.
Treat scraping as a controlled research workflow: use permitted URLs, keep request volume modest, preserve the source URL in every row, and do not work around access controls.
Workflow anatomy
What the Zalando France product scraper does
The companion template is a detail-page workflow, not a catalogue crawler. It follows a simple path: Set Window Size -> Navigate -> Wait for Page Load -> Wait for Element -> Structured Export -> Loop Continue. Navigate owns the product URL list. The wait blocks give the rendered page time to expose the title area. Structured Export writes the CSV row. Loop Continue moves to the next URL.
The JSON export is the authoritative workflow definition. It starts with two product detail URLs and writes to zalando_fr_produit_scraper.csv with headers enabled and append mode on. Scale the run by adding approved product detail URLs to navigate.urls.
| Block | Purpose | What to check |
|---|---|---|
| Set Window Size | Opens pages at a consistent browser size | Keep the default unless your layout test shows missing data. |
| Navigate | Loops through supplied product URLs | Replace the sample Puma and Lacoste URLs with your approved list. |
| Wait for Page Load | Allows the product page to finish loading | Increase the timeout if pages are slow or prompts appear. |
| Wait for Element | Waits for product title selectors or h1 | Confirm the browser is on a product page, not a block or consent page. |
| Structured Export | Extracts fields into CSV | Keep headers and append mode while testing batches. |
Runbook
How to scrape Zalando product pages to CSV
Import the scraper template
Open the Zalando France Product Scraper page, download the JSON template, and import it into UScraper.
Replace the sample product URLs
In Navigate, remove the sample URLs and paste the Zalando.fr product detail pages you are allowed to review. Keep one URL per product page.
Set the export destination
Open Structured Export and confirm the file name, save folder, headers, and append mode. Use a project-specific folder if the CSV will feed reporting or QA.
Run a one-product test
Run one URL and open the CSV immediately. Compare marque, description, prix, and img against the browser view.
Run the remaining URLs
After the first row is clean, run the full Navigate list. Keep the browser visible so consent, verification, or unavailable-product states are caught early.
Treat the workflow as supervised automation: confirm the first row, watch for page states, then expand the URL list only after the output matches the visible product page.
Output
What the Zalando France CSV export includes
zalando_fr_produit_scraper.csvColumn
marque
Brand name from the product title area, brand link, page title, or metadata fallback.
Column
description
Product name or short product description cleaned from the detail page.
Column
prix
Visible euro-formatted price text when present on the rendered page.
Column
detail_url
The exact Zalando.fr product URL opened by the browser.
Column
img
Product image URL from Open Graph metadata or gallery image fallback.
Sample rows
2 of many
| marque | description | prix | detail_url | img |
|---|---|---|---|---|
| Puma | ACM Tee - T-shirt imprime | 34,95 EUR | ||
| Lacoste Sport | Kurzarm Polo - bleu marine blanc | 79,95 EUR |
The template uses JavaScript-backed export columns because Zalando product pages can expose useful values through visible text, title metadata, Open Graph image tags, or page title fallbacks. That helps small research runs, but selector maintenance is still part of the job.
Validation
Validate and troubleshoot the first export
After the first run, sort or filter by detail_url. One product URL should create one row. If the same row appears twice, the run likely resumed after Structured Export had already appended, or the URL appears more than once in Navigate.
| Symptom | Likely cause | Fix |
|---|---|---|
Empty marque | Product title area did not render or page changed | Check the browser, extend waits, and update the brand selector if needed. |
Blank prix | Price hidden, item unavailable, or price module changed | Reopen the product URL manually and compare the visible page state. |
Missing img | Open Graph image missing or gallery selector drifted | Inspect the page metadata and refresh the image fallback selector. |
| Rows contain a consent page | Prompt appeared before product content | Handle the prompt in-browser, then rerun the failed URL. |
| Fewer rows than URLs | Blocked page, timeout, or early stop | Rerun a small subset and watch the page state before scaling again. |
Alternatives
UScraper vs Python, Selenium, and hosted Zalando scrapers
Python and Selenium tutorials are useful when your team wants code ownership, custom retry logic, and programmatic pipelines. They also require maintenance for browser drivers, selectors, waits, storage, and rate controls. Hosted Zalando scrapers can be convenient when you need cloud scheduling or managed infrastructure.
UScraper fits a different workflow: a local desktop app, visible browser QA, a no-code block graph, and a CSV export that a non-developer can inspect. For small product research and controlled URL-list exports, the local workflow is often simpler than writing a Zalando scraper in Python or managing a cloud actor. For production-scale ecommerce feeds, evaluate permissions, vendor contracts, reliability guarantees, and data custody first.
Browse all UScraper templates if you need sibling ecommerce workflows, or open the UScraper blog for more no-code scraping tutorials.
FAQ
Zalando France scraper FAQ
Public product pages can still be subject to Zalando terms, robots directives, copyright, database rights, privacy rules, and local law. Review the current Zalando France robots.txt and legal pages, keep runs modest, avoid bypassing access controls, and get legal advice before commercial reuse.
Next step
Download the Zalando France product scraper template
When you are ready to run the workflow, download the JSON from Zalando France Product Scraper and keep this tutorial open for QA. Add your product detail URLs, run one row, verify the CSV, then expand the batch only after the export matches the browser.