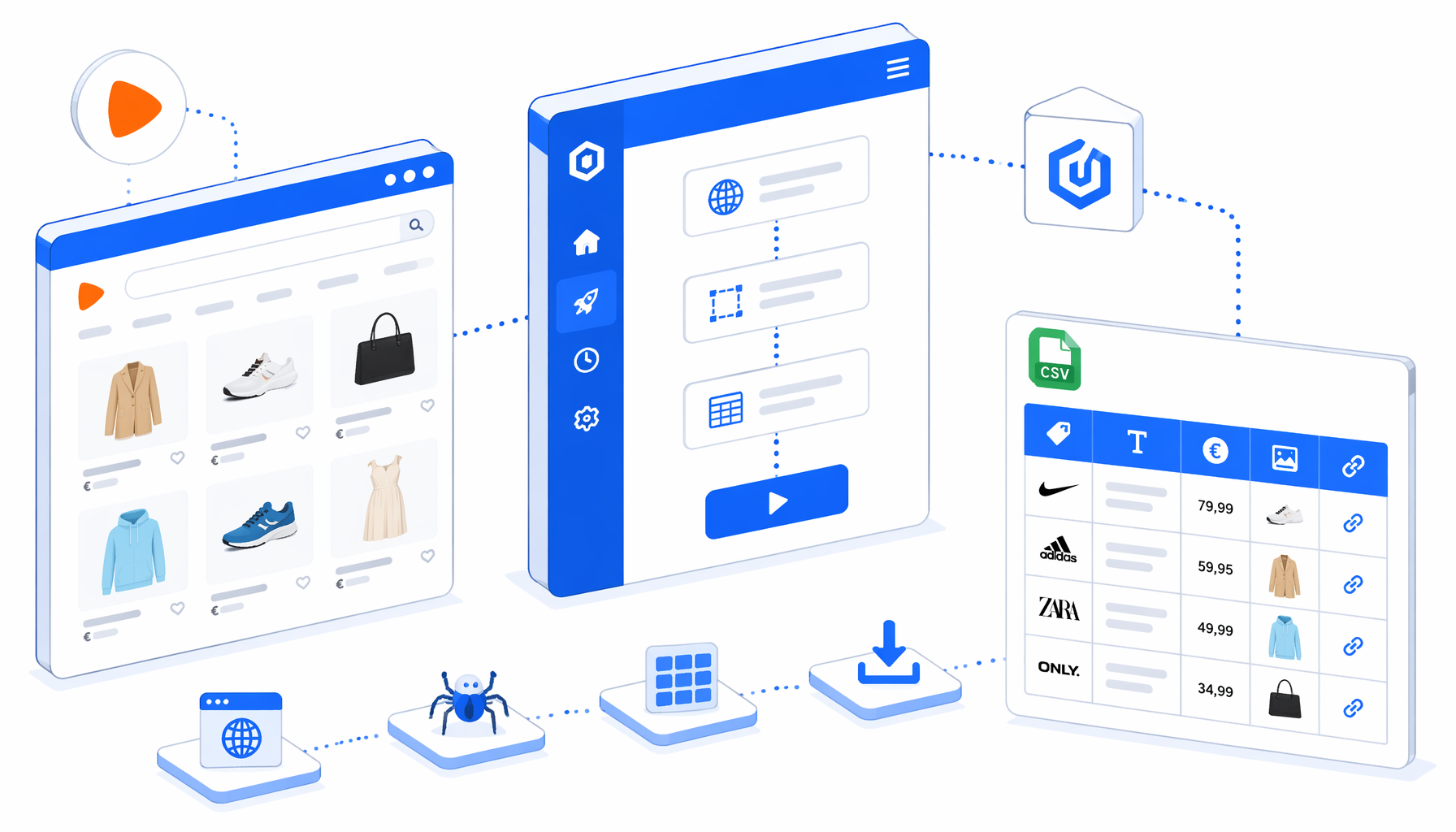
This tutorial shows how to scrape Zalando.de product data from listing pages into CSV with the Zalando.de Product Scraper template. You will import the workflow, edit URLs, confirm the export path, run one validation page, and check output before widening the batch.
Before you start
Prerequisites for a Zalando.de product scraper
You need UScraper installed as a local desktop app, the Zalando.de Product Scraper template, allowed Zalando.de listing URLs, and a folder for the CSV. Start with one page because listings can vary by category, search term, consent state, region, and session.
This guide covers visible listing pages, not account areas, carts, checkout, private customer data, login-only content, CAPTCHA bypassing, or attempts to defeat access controls. Before automation, review the current Zalando.de robots.txt, Zalando terms, and applicable law.
Technical access is not the same thing as permission. Keep runs modest, preserve the source URL in every row, and use official or licensed access when the output will feed a production system.
Workflow
What the Zalando.de Product Scraper template does
The JSON export is the authoritative workflow definition. It sets a browser size, opens a known URL list, waits up to 30 seconds, clicks common consent buttons when they appear, scrolls lazy product cards into view, checks for product rows, and runs Structured Export only when matching rows exist.
The starter URL list includes three Zalando.de entry points expanded across pages 1 through 10. URL-list pagination is easier to audit than an infinite-scroll guess, especially when you need a repeatable Zalando to CSV export.
{
"fileName": "zalando_de_produkt_scraper.csv",
"rowSelector": "article:has(a[href*='.html']):has(img[src*='ztat'])",
"input": "Zalando.de listing and search URLs",
"pagination": "known URL list, pages 1-10 per starter query",
"columns": [
"marke",
"produkt_titel",
"preis",
"bild_url",
"plus_etikett",
"produkt_url"
]
}
Output
What the Zalando.de CSV export includes
zalando_de_produkt_scraper.csvColumn
marke
Brand from product-card text or URL fallback.
Column
produkt_titel
Product title from visible card text or URL fallback.
Column
preis
Visible euro-formatted price text.
Column
bild_url
Primary listing image URL.
Column
plus_etikett
PLUS, Premium Delivery, or Early Access label when visible.
Column
produkt_url
Absolute product detail URL from the card.
| Column group | Fields | Why it matters |
|---|---|---|
| Product identity | marke, produkt_titel | Group rows by brand, query, category, or merchandising theme. |
| Price and label checks | preis, plus_etikett | Review visible price and delivery or premium labels during research. |
| Traceability | bild_url, produkt_url | Open the original product page or image when a row needs manual QA. |
Append mode stacks every configured listing URL into one CSV. Use a dated filename or clean folder before reruns.
Runbook
How to scrape Zalando.de products to CSV
Import the template
Open Zalando.de Product Scraper, download the workflow JSON, and import it into UScraper.
Replace the listing URLs
In Navigate, replace or extend the sample Zalando.de brand, category, and search URLs. Keep filter, sort, query, and page parameters that define the dataset.
Confirm the export path
Open Structured Export and confirm zalando_de_produkt_scraper.csv, headers, append mode, and a project-specific save folder.
Run one validation page
Run one URL first. Watch for consent, verification, redirects, empty categories, or cards that load after scrolling.
Validate and scale
Compare marke, produkt_titel, preis, bild_url, and produkt_url against the browser before adding more URLs.
For recurring research, save the original URL list next to the CSV. Page filters are part of the dataset.
Validation
Common issues in Zalando product data extraction
Open the CSV beside the browser after the first run. Check the first five rows and sort by produkt_url for duplicates. A clean listing page should produce product URLs, images, and at least some visible price values.
| Symptom | Likely cause | Fix |
|---|---|---|
| Zero rows exported | Cards did not render, a prompt blocked the page, the selector drifted, or the URL had no listing results | Handle allowed prompts, inspect the browser state, and rerun one URL. |
| Blank prices | Price text was delayed, hidden, or moved in the card markup | Increase waits and inspect one card before editing the JavaScript column. |
| Missing images | Images loaded after export or no ztat image source was present | Keep the scroll step and rerun after images visibly load. |
| Duplicate products | The same URL list was appended twice or two listing pages overlap | Clear the CSV before reruns and dedupe by produkt_url. |
| Brand and title look swapped | The card text order changed | Update the marke and produkt_titel JavaScript selectors against the live card. |
API vs scraper
Zalando API vs scraper vs Python script
The official Zalando Merchant Platform Products API is the right place for approved merchant product workflows. It is not the same thing as a quick public listing export for research.
A Zalando scraper Python project gives developers control over Selenium sessions, retries, storage, tests, and deployment. It also means maintaining drivers, selectors, queues, logs, and failure handling.
UScraper fits a narrower job: supervised no-code collection, visible browser QA, and a local CSV that non-developers can inspect.
FAQ
Zalando.de product scraper FAQ
Zalando.de pages can be public and still be governed by terms, robots directives, access controls, copyright, database rights, privacy rules, and local law. Review the current rules and get legal review before commercial reuse.
Next step
Download the Zalando.de product scraper template
When you are ready to run the tutorial, download the JSON from Zalando.de Product Scraper and keep this article open for QA. For neighboring ecommerce workflows, browse all UScraper templates or read more CSV export tutorials on the UScraper blog.