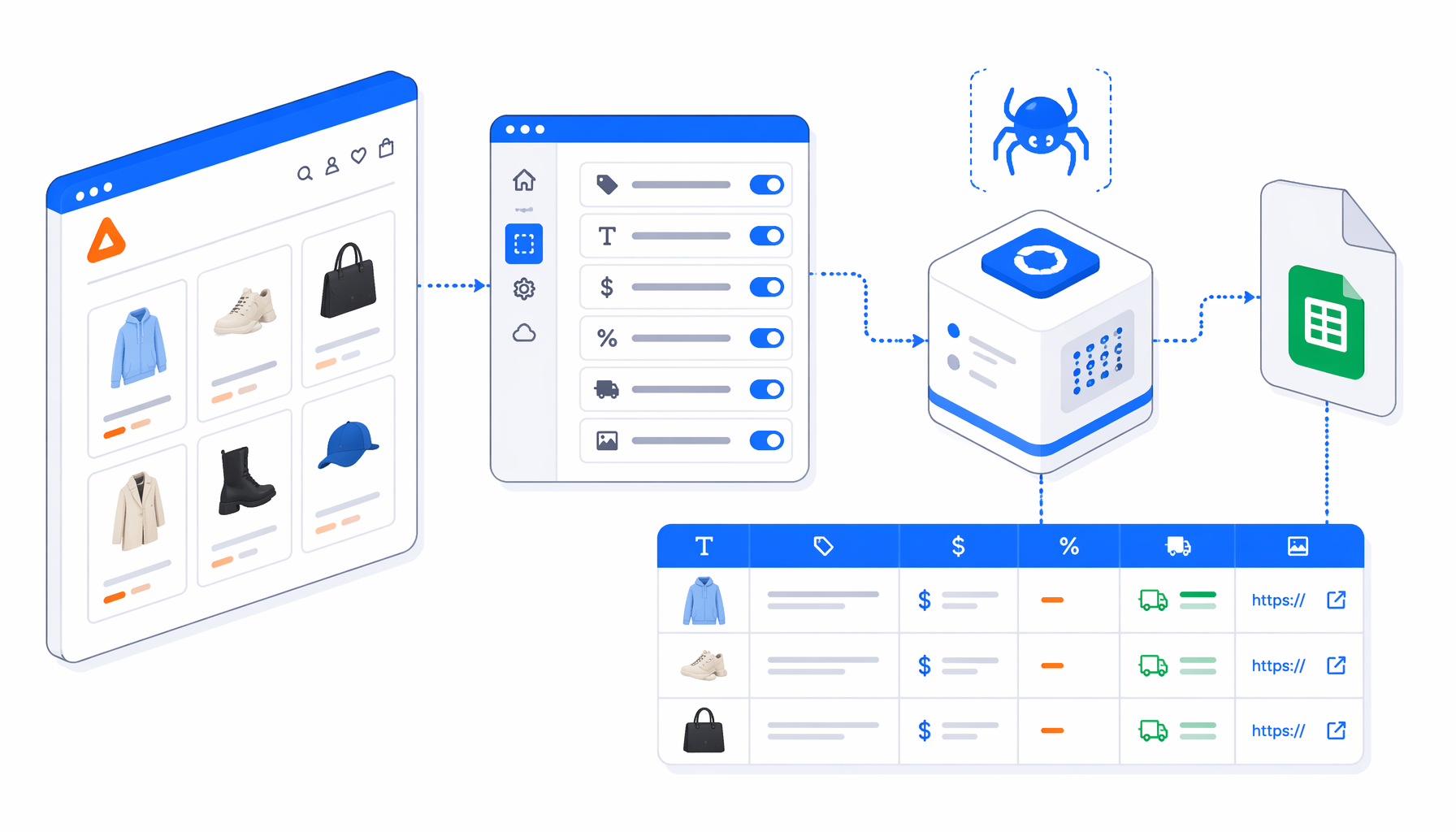
This tutorial shows how to scrape Zalando product data from keyword listing pages into CSV with the Zalando Product Scraper template. Import the workflow, edit catalog URLs, set the export path, run one validation page, and check rows before scaling.
Before you start
Prerequisites for scraping Zalando listings
You need UScraper installed as a local desktop app, the Zalando Product Scraper template, Zalando.it keyword URLs you are allowed to process, and a folder for the CSV. Start with one keyword and one page because listings vary by site, language, filters, stock, sale period, consent state, and session.
This guide covers visible catalog pages, not account dashboards, carts, checkout, partner portals, login-only prices, CAPTCHA bypassing, or private customer data. Review Zalando's current robots.txt, terms, and Partner Solutions docs for approved access.
Technical access is not the same as permission. Keep runs modest, avoid restricted data, document why the dataset is being collected, and use official or licensed routes when the export will feed a production system.
Workflow
What the Zalando product scraper workflow does
The JSON export is the authoritative workflow definition: set window size, navigate to keyword URLs, wait for product article links, scroll, export, check for Next, click Next, then repeat. The bundled workflow starts with editable Zalando.it searches such as borsette, occhiali da sole, and cappotti. JavaScript columns clean card text and extract the product URL from a[href*=".html"].
{
"fileName": "crawler_prodotti_zalando.csv",
"rowSelector": "article",
"input": "Zalando.it keyword URLs",
"pagination": "Next link when present",
"columns": [
"parola_chiave",
"titolo",
"pagina_url",
"brand",
"prezzo_attuale",
"prezzo_prima",
"sconto",
"consegna",
"img_url"
]
}
Append mode writes every keyword and reachable pagination page into the same local CSV. Clear the file or use a dated filename before reruns.
Output
What the Zalando to CSV export includes
| CSV column | What it captures | Validation check |
|---|---|---|
parola_chiave | Search keyword from the current URL | Confirm it matches the intended batch. |
titolo | Product title from card text or link label | Compare against the visible card title. |
pagina_url | Absolute product detail URL | Open a few rows to confirm traceability. |
brand | Brand name detected from card text | Spot-check mixed-brand result pages. |
prezzo_attuale | Current displayed price | Expect blanks when price is not exposed. |
prezzo_prima | Previous or secondary price | Useful for markdown analysis. |
sconto | Visible discount such as -30% | Validate during sale periods. |
consegna | Delivery, shipping, or long-distance label | Treat as visible page copy. |
img_url | Primary image URL | Use for QA and matching. |
This is a listing-level scraper for assortment scans, price checks, sale monitoring, and discovery. For variant sizes, full descriptions, or reviews, run a detail workflow against selected pagina_url values.
Runbook
How to scrape Zalando product data to CSV
Import the template
Open Zalando Product Scraper, download the workflow JSON, and import it into UScraper.
Edit keyword URLs
Replace the bundled Zalando.it catalog searches with approved keyword URLs. Keep language, category, sort, and filter parameters when they affect results.
Confirm waits
Keep the 45-second page-load wait, product-link check, scroll block, and short sleep before Structured Export.
Set the CSV destination
Structured Export writes crawler_prodotti_zalando.csv with headers and append mode. Change the save location before running a batch.
Run one page, then widen
Run one keyword page, compare the CSV with the browser, then collect later pages only after the first sample is clean.
For recurring research, keep the exact source URLs. Filters and locale are part of the dataset.
Validation
Validate the export before using the data
Open the CSV beside the browser after the first run. Check the first five rows, one middle row, and one row from the last page. Sort by pagina_url for duplicates and by prezzo_attuale for blanks.
| Symptom | Likely cause | Fix |
|---|---|---|
| Zero rows exported | Product cards did not render, consent blocked the page, or the selector no longer matches | Handle allowed prompts, wait for product cards, and rerun one page. |
| Blank prices | Price text was delayed, hidden for the session, or moved in the listing markup | Increase wait time and inspect one card before changing the JS column. |
| Duplicate rows | A run was appended twice or pagination revisited a page | Clear the CSV before reruns and dedupe by pagina_url. |
| Brand and title swapped | Text order changed in the product card | Update the brand and titolo selectors. |
| Missing images | The card image did not expose currentSrc or src when exported | Keep img_url optional and rerun after a scroll if images lazy-load. |
Alternatives
Zalando scraper Python, API, or local workflow?
A Zalando scraper Python script gives developers control over selectors, retries, storage, and tests. It also means maintaining browser automation, queues, logs, and selector drift. A hosted Zalando scraping API can reduce infrastructure work, but data passes through a third party and pricing is usually usage-based.
UScraper fits a different path: visible-browser QA, no-code edits, and local CSV output for controlled research batches. For a production shoe store API, official partner or licensed product-data routes are more durable. For a quick Zalando to CSV export, UScraper templates are usually shorter.
FAQ
Zalando product scraper FAQ
Public pages can still be limited by terms, robots directives, access controls, copyright, database rights, privacy law, and local regulations. Review the current rules, keep runs modest, and get legal review before commercial reuse.
Next step
Download the Zalando product scraper template
When you are ready to run the tutorial, download the JSON from Zalando Product Scraper and keep this article open for QA. For ecommerce workflows, compare the Farfetch scraper, browse all UScraper templates, or read more export tutorials on the UScraper blog.