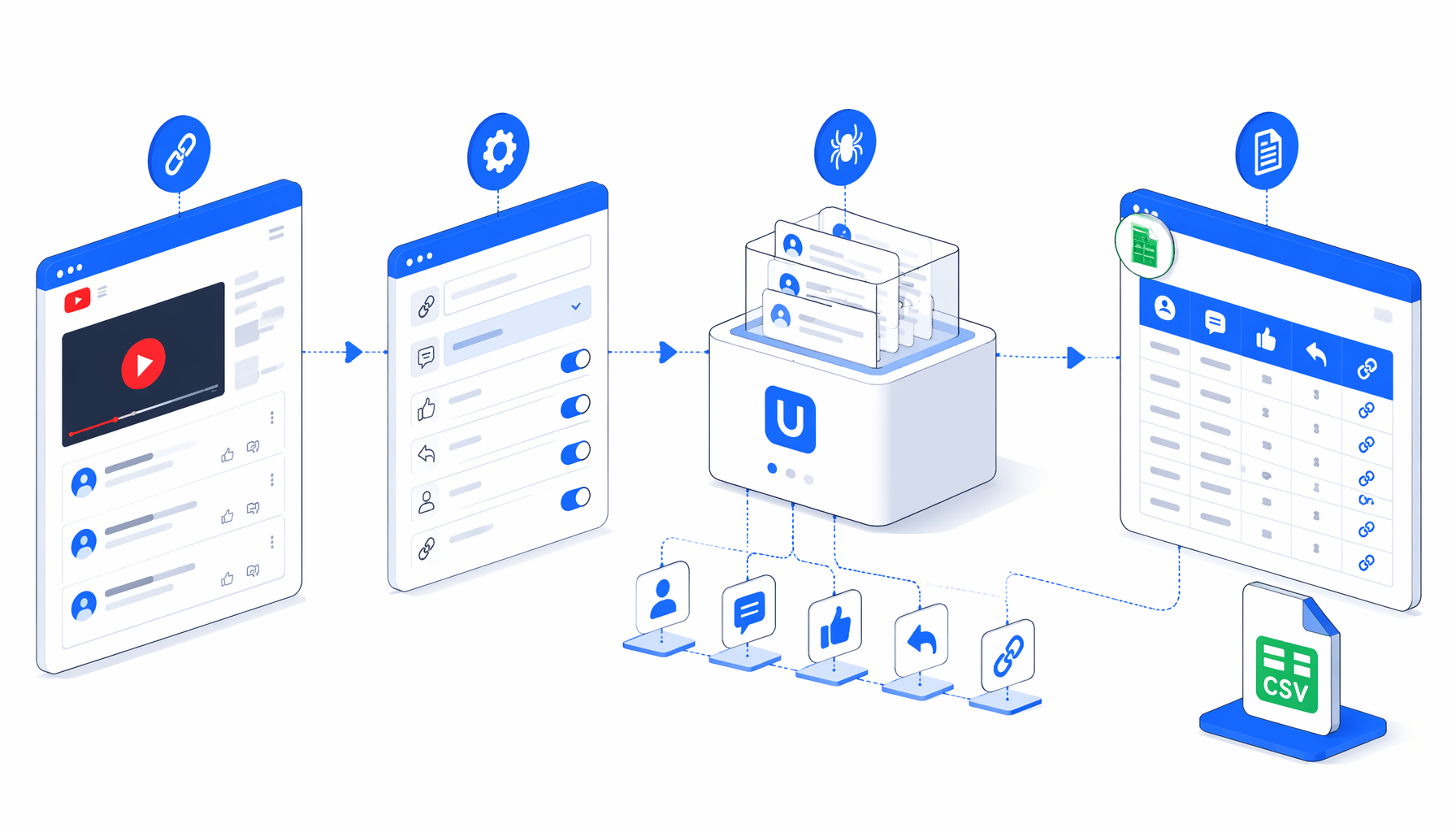
This tutorial shows how to scrape YouTube comments from one or more video URLs into a local CSV. You will import the YouTube Video Comments Scraper template, replace the sample watch URL, set the export path, validate the rows, and decide when a no-code scraper is a better fit than the YouTube Data API.
Prerequisites
Before you scrape YouTube comments
You need UScraper as a local desktop app, one or more YouTube watch URLs, a folder where the CSV should be saved, and a short validation plan. Start with one video that has visible public comments. A small first run makes it easier to spot disabled comments, age checks, region gates, consent screens, or empty exports before you add a long list of URLs.
You also need a clear reason for collecting the data. YouTube comments are user-generated content. Public visibility does not automatically mean you can republish, sell, profile, or train models on the export. Keep the batch narrow, avoid private or restricted content, and get legal review for commercial, research, or model-training workflows.
Write down the source videos, purpose, fields needed, retention period, and who can access the CSV before you run the scraper. The best scraping workflow is the one you can explain later.
Choose a path
YouTube comments API vs scraper
There are three common ways to export YouTube comments to CSV: the official API, a Python script, or a no-code scraper. The right path depends on your team, the size of the job, and how much control you need over replies and pagination.
| Path | Best for | Trade-off |
|---|---|---|
| UScraper template | Non-developers who need a local CSV from known video URLs | Exports loaded visible threads; very large threads may need scroll tuning. |
| YouTube Data API | Engineers who need sanctioned programmatic access and pagination | Requires API setup, quota management, and code. |
| Python scraper or API script | Developers building a custom dataset pipeline | Flexible, but you own authentication, retries, storage, and maintenance. |
| Hosted scraper actor | Teams that want cloud queues and managed runs | Output and source URLs pass through another provider. |
The official commentThreads.list endpoint is the primary API route for retrieving comment threads for a video. Google's comments implementation guide explains that commentThreads.list can request snippet for top-level comments or snippet,replies when you also want included replies. For full reply pagination, developers typically pair it with comments.list, which lists comments that match request parameters such as a parent comment ID.
Workflow
How the YouTube comments scraper works
The template follows a readable browser workflow: Set Window Size -> Navigate -> Wait for Page Load -> handle consent -> scroll to comments -> wait for comment rows -> bounded scroll loop -> Structured Export -> Loop Continue. The Navigate block accepts multiple watch URLs. The Loop Continue block advances to the next URL after the current video's loaded comments are exported.
The important part is the bounded scroll loop. YouTube comments load dynamically, so the workflow scrolls until continuation rows stop appearing or the guard reaches 20 cycles. That prevents a single large video from running forever while still giving the page time to load a practical comment sample.
| Block | Purpose | What to check |
|---|---|---|
| Navigate | Opens each youtube.com/watch?v=... URL | Replace the sample URL with approved video inputs. |
| Inject JavaScript | Accepts common consent prompts and moves to comments | Watch for login, age, or verification screens. |
| Wait for Element | Confirms ytd-comment-thread-renderer appears | Empty pages usually mean disabled comments or blocked loading. |
| Scroll loop | Loads more comment thread rows | Raise the guard only after a successful small test. |
| Structured Export | Appends loaded rows to CSV | Confirm file name, headers, save folder, and append mode. |
| Loop Continue | Moves to the next video URL | Remove duplicates before running a batch. |
The JSON workflow definition is the authoritative source for the export shape. In the bundled template, the file name is youtube-video-comments-scraper.csv, the output mode is append, and the row selector is ytd-comment-thread-renderer.
{
"project": {
"name": "YouTube Video Comments Scraper"
},
"blocks": [
{ "title": "Navigate", "config": { "urls": ["https://www.youtube.com/watch?v=dQw4w9WgXcQ"] } },
{ "title": "Wait for Element", "config": { "selector": "ytd-comment-thread-renderer", "timeout": 90 } },
{
"title": "Structured Export",
"config": {
"rowSelector": "ytd-comment-thread-renderer",
"fileName": "youtube-video-comments-scraper.csv",
"includeHeaders": true,
"fileMode": "append"
}
}
]
}
Runbook
How to export YouTube comments to CSV
Import the template
Open the YouTube comments scraper template, download the JSON workflow, and import it into UScraper.
Paste video URLs
Replace the sample Navigate URL with one or more YouTube watch URLs. Keep the first test to one video so any issue is easy to trace.
Set the export path
In Structured Export, confirm youtube-video-comments-scraper.csv, headers enabled, append mode, and a save folder for this project or client.
Run one validation video
Watch the browser session until comments appear, then let the scroll loop finish. Stop if YouTube asks for login, age verification, CAPTCHA, or unusual traffic checks.
Check the CSV
Open the export, compare several comment permalinks against the source video, verify the video ID and title, and only then add more URLs.
Output
CSV fields from the YouTube comments scraper
The export is designed for analysis rather than archiving every possible YouTube object. Each row represents a loaded top-level comment thread with video context repeated beside the comment fields.
youtube-video-comments-scraper.csvColumn
video_url
Canonical watch URL for the source video.
Column
video_id
The v query parameter from the YouTube URL.
Column
video_title
The page title from metadata or the visible H1.
Column
username
Comment author display name.
Column
user_channel_url
Absolute URL for the author's channel when available.
Column
comment_text
Visible top-level comment text.
Column
likes
Visible like count text.
Column
published_time
Publish label shown beside the comment.
Column
comment_url
Permalink to the comment when exposed.
Column
comment_id
The lc value parsed from the comment URL.
Column
author_avatar_url
Author avatar image URL.
Column
reply_count
Visible reply count text, such as 3 replies.
Sample rows
1 of many
| video_url | video_id | video_title | username | user_channel_url | comment_text | likes | published_time | comment_url | comment_id | author_avatar_url | reply_count |
|---|---|---|---|---|---|---|---|---|---|---|---|
| abc123 | Product launch walkthrough | Jordan Lee | This answered the pricing question I had. | 18 | 2 weeks ago | Ugx111 | 4 replies |
For adjacent workflows, browse the UScraper templates library, pair this with the YouTube Video List Scraper for video discovery, or read more no-code scraping tutorials in the UScraper blog.
Validation
Common issues when scraping YouTube comments
| Symptom | Likely cause | Fix |
|---|---|---|
| No comments appear | Comments are disabled, not loaded, or behind a gate | Open the video manually and confirm comments are visible. |
| CSV is empty | The row selector never found ytd-comment-thread-renderer | Check for consent, login, age, region, or unusual traffic prompts. |
| Row count is lower than YouTube's visible count | The scroll loop stopped before all dynamic rows loaded | Treat the export as loaded comments, or increase the guard cautiously. |
| Some fields are blank | YouTube did not expose a like count, avatar, channel URL, or permalink | Keep blanks instead of fabricating values. |
| Duplicate rows appear | Append mode reran the same URL list | Start a fresh CSV or dedupe by video_id and comment_id. |
Frequently asked questions
YouTube comments can be publicly visible, but collection and reuse may still be governed by YouTube terms, copyright, privacy law, data protection rules, and your own use case. Do not bypass access controls, collect private information, or republish comments without a valid basis.