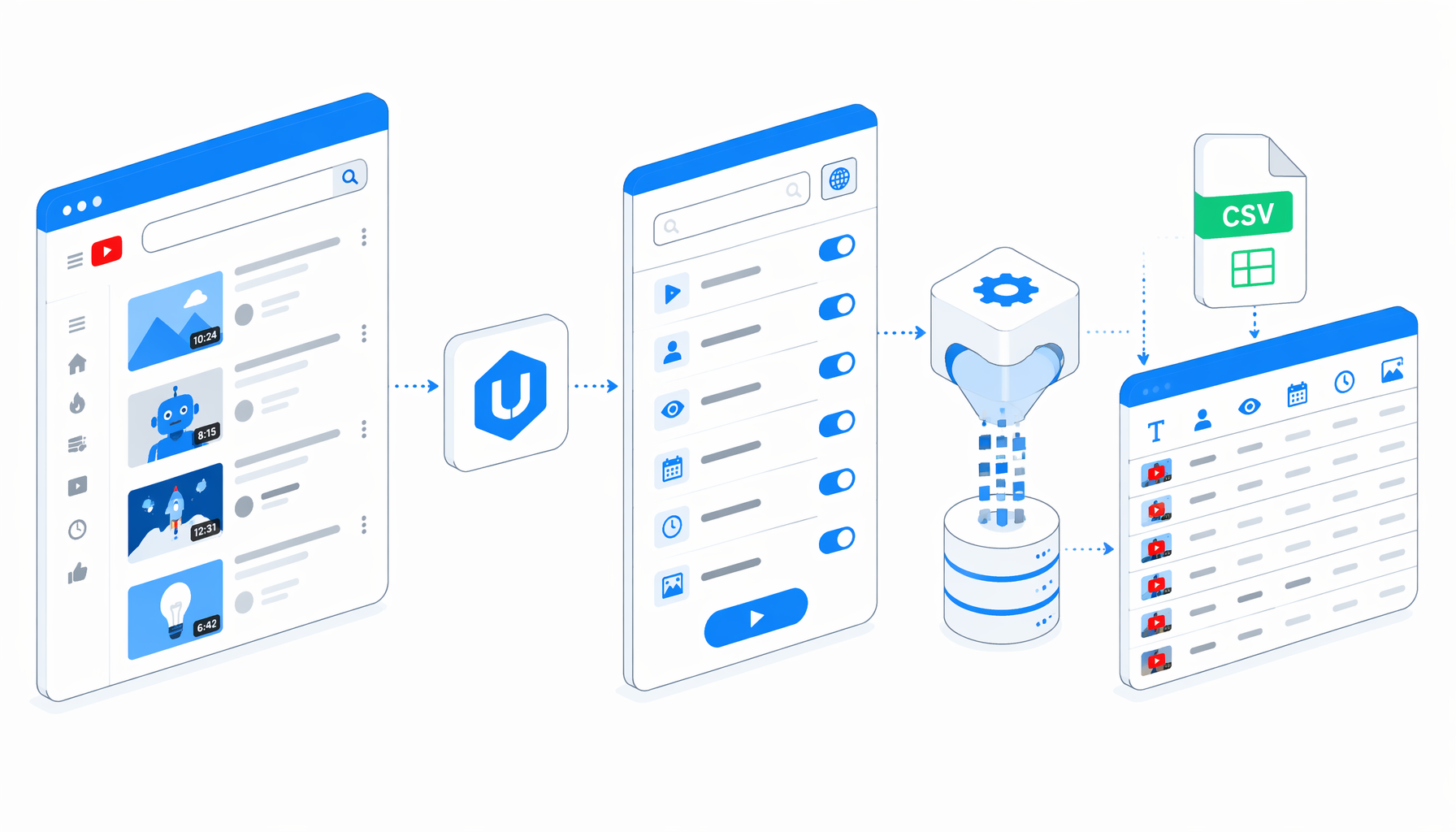
This YouTube scraping tutorial shows how to scrape YouTube search results into CSV with the YouTube Scraper template for UScraper. You will import the workflow, edit the search URL, run the bounded scroll, export metadata, and validate the rows.
Before you start
Prerequisites and scope
You need UScraper installed as a local desktop app, the current YouTube Scraper template, and a folder where the CSV can be saved. Start with one query before running a batch.
This guide covers YouTube search result metadata, not video downloads, transcripts, private account data, paid content, or comments. If your use case needs an official integration, compare this workflow with the YouTube Data API, including search.list, videos.list, and commentThreads.list.
Compliance first: use pages you are allowed to access, do not bypass CAPTCHA or login checks, respect YouTube policy, and get legal review before building datasets for commercial redistribution.
Workflow anatomy
Export shape from the YouTube scraper JSON
The bundled JSON export is the authoritative workflow definition. It sets a 1920 by 1080 browser window, opens https://www.youtube.com/results?search_query=web+scraping, handles common consent UI, waits for ytd-video-renderer, runs bounded auto-scroll, then exports loaded video cards.
| Workflow step | What it does | Why it matters |
|---|---|---|
| Set Window Size | Opens a large viewport | Reduces mobile or compact layout surprises. |
| Navigate | Loads the editable search URL | Your query lives here, so this is the first setting to change. |
| Consent check | Clicks common accept buttons when found | Prevents the export from reading a consent screen as the page. |
| Auto-scroll | Scrolls until height stabilizes or 30 scrolls complete | Loads more search results without an infinite run. |
| Structured Export | Reads ytd-video-renderer rows | Keeps one CSV row scoped to one loaded video card. |
The export writes youtube-scraper.csv in create mode with headers. There is no bundled CSV sample, so treat the JSON shape as the source of truth:
{
"rowSelector": "ytd-video-renderer",
"fileName": "youtube-scraper.csv",
"columns": [
"video_title",
"video_url",
"channel_name",
"channel_url",
"views",
"published_date",
"description",
"duration",
"thumbnail_url",
"badge"
]
}
Runbook
How to scrape YouTube search results to CSV
Import the template
Open the YouTube Scraper template, download the JSON workflow, and import it into UScraper.
Edit the search URL
In Navigate, replace web+scraping with your keyword, creator category, competitor name, product phrase, or topic cluster. Keep the YouTube results URL structure intact.
Confirm consent and waits
Keep the page-load waits and the ytd-video-renderer check. If YouTube shows a prompt, resolve it in the browser before judging selector quality.
Set the export folder
In Structured Export, confirm youtube-scraper.csv, headers, create mode, and the save location you want for the project.
Run and inspect
Run one query, open the CSV, compare a few rows with the browser, then duplicate the workflow or edit the query for the next research topic.
After the first export, sort by video_url. Each normal video result should have one row. If a row is incomplete, check whether the page displayed Shorts, playlists, ads, shelves, or another renderer.
Validation
Validate the YouTube video metadata export
Validation confirms the scraper is reading the page you saw. Keep the YouTube tab open beside the CSV and spot-check top, middle, and bottom rows.
| Symptom | Likely cause | Fix |
|---|---|---|
Empty video_title | The page did not reach standard video result cards | Handle prompts, rerun one query, and confirm ytd-video-renderer appears. |
Missing channel_url | YouTube did not expose the channel link in that card | Keep the row, but do not treat the channel URL as mandatory. |
| Repeated rows | The same query was exported more than once | Create a fresh CSV or dedupe by video_url. |
| Few results | Scroll stopped early or the query has limited visible inventory | Increase only after a small compliant test and review the browser response. |
| Blank thumbnails | Lazy loading or markup change | Scroll once manually, rerun, then update the image selector if needed. |
Alternatives
YouTube Data API alternative or official API?
UScraper is useful for supervised spreadsheet exports from visible search results. The official API is better for production integrations, documented quota behavior, and sanctioned access paths. Hosted scrapers and scripts sit between those choices.
| Option | Best fit | Output | Trade-off |
|---|---|---|---|
| YouTube Data API | Approved apps, repeatable product integrations, richer endpoint contracts | JSON responses from official endpoints | Requires API setup, quota planning, and policy compliance. |
| UScraper template | No-code research, creator discovery, competitor monitoring, content gap analysis | Local CSV from loaded search cards | Best-effort browser extraction that needs selector checks. |
| Hosted scraper actors | Scheduled collection, cloud runs, API delivery | Vendor datasets, CSV, JSON, or API results | Data passes through vendor infrastructure and pricing is usage based. |
| Python scripts | Engineering teams with custom parsing requirements | Whatever the script writes | Highest control, highest maintenance burden. |
If you are comparing the best YouTube scraper options, start with the access path. Use official APIs for approved applications, a local desktop workflow for analyst CSVs, and hosted providers only after weighing policy risk, infrastructure, and budget.
FAQ
Frequently asked questions
Automating YouTube can be restricted by YouTube terms, robots directives, copyright rules, privacy law, or local regulations even when search listings are visible in a browser. Review the current YouTube Terms of Service, avoid bypassing verification or access controls, keep runs modest, and use approved API access when you need sanctioned production collection.